所用到的技术有Jsoup,HttpClient。
Jsoup
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
HttpClient
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
爬取豆瓣电影数据
豆瓣电影网址。
|
1
|
https://movie.douban.com/explore#!type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0 |
打开浏览器f12,地址栏中输入该地址访问,可以看到请求响应的页面,对应可以找到电影数据的请求地址,数据请求地址
|
1
|
https://movie.douban.com/j/search_subjects?type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0 |

可以看到数据请求地址响应过来的是一个JSON格式的数据,之后我们看到请求地址上的参数type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0。其中type是电影tag是标签,sort是按照热门进行排序的,page_limit是每页20条数据,page_start是从第几条数据开始查询(下标从0开始)。但是这不是我们想要的,我们需要去找豆瓣电影数据的总入口地址是下面这个
|
1
|
https://movie.douban.com/j/search_subjects |
创建SpringBoot项目爬取数据
把爬取到的数据保存到数据库中,电影图片保存在本地磁盘中,这里持久层用的是JPA,所以需要引入对应的依赖。pom.xml中依赖代码如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.mcy</groupId> <artifactId>crawler-douban</artifactId> <version>0.0.1-SNAPSHOT</version> <name>crawler-douban</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <!--httpclient--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <!--jsoup,解析HTML--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project> |
项目目录结构如下。
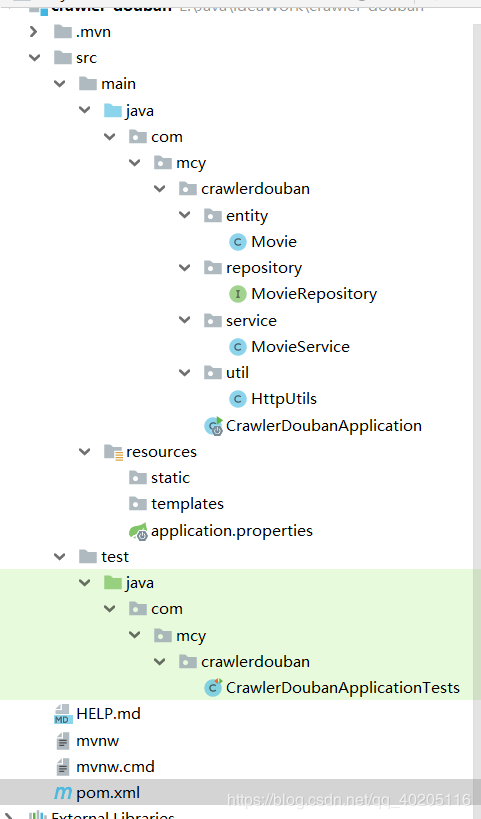
首先我们在entity包中建立实体对象,字段为豆瓣电影的基本信息(有些信息是详情页面的信息)。
Movie实体类。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
import javax.persistence.*; @Entitypublic class Movie { private Integer id; private double rate; //评分 private String title; //电影名称 private String director; //导演 private String protagonist; //主演 private String dateTime; //电影时长 @Id @GeneratedValue(strategy = GenerationType.IDENTITY) public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public double getRate() { return rate; } public void setRate(double rate) { this.rate = rate; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getDirector() { return director; } public void setDirector(String director) { this.director = director; } @Column(length=2000) public String getProtagonist() { return protagonist; } public void setProtagonist(String protagonist) { this.protagonist = protagonist; } public String getDateTime() { return dateTime; } public void setDateTime(String dateTime) { this.dateTime = dateTime; }} |
在src/main/resources下找到application.properties文件,在该配置文件中配置数据库链接信息,需要在数据库中新建一个名为douban的数据库。
|
1
2
3
4
5
6
7
8
|
spring.datasource.url=jdbc:mysql://localhost:3306/douban?serverTimezone=GMT%2B8spring.datasource.username=rootspring.datasource.password=rootspring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverspring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialectspring.jpa.show-sql=truespring.jpa.hibernate.ddl-auto=updatespring.jpa.hibernate.use-new-id-generator-mappings=false |
创建MovieRepository数据访问层接口
|
1
2
3
4
5
6
|
import com.mcy.crawlerdouban.entity.Movie;import org.springframework.data.jpa.repository.JpaRepository; public interface MovieRepository extends JpaRepository<Movie, Integer> { } |
创建MovieService类,里边有一个保存数据的方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import com.mcy.crawlerdouban.entity.Movie;import com.mcy.crawlerdouban.repository.MovieRepository;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service; @Servicepublic class MovieService { @Autowired private MovieRepository movieRepository; public void save(Movie movie) { movieRepository.save(movie); }} |
创建一个HttpUtils获取网页数据和保存图片的工具类。
创建连接池和配置连接池信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
//创建连接池管理器private static PoolingHttpClientConnectionManager cm; public HttpUtils(){ cm = new PoolingHttpClientConnectionManager(); //设置最大连接数 cm.setMaxTotal(100); //设置每个主机的最大连接数 cm.setDefaultMaxPerRoute(10);} //配置请求信息private static RequestConfig getConfig() { RequestConfig config = RequestConfig.custom() .setConnectTimeout(10000) //创建连接的最长时间,单位毫秒 .setConnectionRequestTimeout(10000) //设置获取链接的最长时间,单位毫秒 .setSocketTimeout(10000) //设置数据传输的最长时间,单位毫秒 .build(); return config;} |
根据请求地址获取响应信息方法,获取成功后返回响应信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
public static String doGetHtml(String url, Map<String, String> map, Map<String, String> mapTile) throws URISyntaxException { //创建HTTPClient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //设置请求地址 //创建URLBuilder URIBuilder uriBuilder = new URIBuilder(url); //设置参数 if(!map.isEmpty()){ for(String key : map.keySet()){ uriBuilder.setParameter(key, map.get(key)); } } //创建HTTPGet对象,设置url访问地址 //uriBuilder.build()得到请求地址 HttpGet httpGet = new HttpGet(uriBuilder.build()); //设置请求头信息 if(!mapTile.isEmpty()){ for(String key : mapTile.keySet()){ httpGet.addHeader(key, mapTile.get(key)); } } //设置请求信息 httpGet.setConfig(getConfig()); System.out.println("发起请求的信息:"+httpGet); //使用HTTPClient发起请求,获取response CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); //解析响应 if(response.getStatusLine().getStatusCode() == 200){ //判断响应体Entity是否不为空,如果不为空就可以使用EntityUtils if(response.getEntity() != null) { String content = EntityUtils.toString(response.getEntity(), "utf8"); return content; } } }catch (IOException e){ e.printStackTrace(); }finally { //关闭response try { response.close(); } catch (IOException e) { e.printStackTrace(); } } return "";} |
根据链接下载图片保存到本地方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
public static String doGetImage(String url) throws IOException { //获取HTTPClient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //设置HTTPGet请求对象,设置url地址 HttpGet httpGet = new HttpGet(url); //设置请求信息 httpGet.setConfig(getConfig()); //使用HTTPClient发起请求,获取响应 CloseableHttpResponse response = null; try { //使用HTTPClient发起请求,获取响应 response = httpClient.execute(httpGet); //解析响应,返回结果 if(response.getStatusLine().getStatusCode() == 200){ //判断响应体Entity是否不为空 if(response.getEntity() != null) { //下载图片 //获取图片的后缀 String extName = url.substring(url.lastIndexOf(".")); //创建图片名,重命名图片 String picName = UUID.randomUUID().toString() + extName; //下载图片 //声明OutputStream OutputStream outputStream = new FileOutputStream(new File("E://imges/" + picName)); response.getEntity().writeTo(outputStream); //返回图片名称 return picName; } } } catch (IOException e) { e.printStackTrace(); }finally { //关闭response if(response != null){ try { response.close(); } catch (IOException e) { e.printStackTrace(); } } } return "";} |
HttpUtils工具类全部代码。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.net.URISyntaxException;import java.util.Map;import java.util.UUID;import org.apache.http.client.config.RequestConfig;import org.apache.http.client.methods.CloseableHttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.client.utils.URIBuilder;import org.apache.http.impl.client.CloseableHttpClient;import org.apache.http.impl.client.HttpClients;import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;import org.apache.http.util.EntityUtils; public class HttpUtils { //创建连接池管理器 private static PoolingHttpClientConnectionManager cm; public HttpUtils(){ cm = new PoolingHttpClientConnectionManager(); //设置最大连接数 cm.setMaxTotal(100); //设置每个主机的最大连接数 cm.setDefaultMaxPerRoute(10); } //配置请求信息 private static RequestConfig getConfig() { RequestConfig config = RequestConfig.custom() .setConnectTimeout(10000) //创建连接的最长时间,单位毫秒 .setConnectionRequestTimeout(10000) //设置获取链接的最长时间,单位毫秒 .setSocketTimeout(10000) //设置数据传输的最长时间,单位毫秒 .build(); return config; } /** * 根据请求地址下载页面数据 * @param url 请求路径 * @param map 请求参数 * @param mapTile 请求头 * @return //页面数据 * @throws URISyntaxException */ public static String doGetHtml(String url, Map<String, String> map, Map<String, String> mapTile) throws URISyntaxException { //创建HTTPClient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //设置请求地址 //创建URLBuilder URIBuilder uriBuilder = new URIBuilder(url); //设置参数 if(!map.isEmpty()){ for(String key : map.keySet()){ uriBuilder.setParameter(key, map.get(key)); } } //创建HTTPGet对象,设置url访问地址 //uriBuilder.build()得到请求地址 HttpGet httpGet = new HttpGet(uriBuilder.build()); //设置请求头信息 if(!mapTile.isEmpty()){ for(String key : mapTile.keySet()){ httpGet.addHeader(key, mapTile.get(key)); } } //设置请求信息 httpGet.setConfig(getConfig()); System.out.println("发起请求的信息:"+httpGet); //使用HTTPClient发起请求,获取response CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); //解析响应 if(response.getStatusLine().getStatusCode() == 200){ //判断响应体Entity是否不为空,如果不为空就可以使用EntityUtils if(response.getEntity() != null) { String content = EntityUtils.toString(response.getEntity(), "utf8"); return content; } } }catch (IOException e){ e.printStackTrace(); }finally { //关闭response try { response.close(); } catch (IOException e) { e.printStackTrace(); } } return ""; } /** * 下载图片 * @param url * @return 图片名称 */ public static String doGetImage(String url) throws IOException { //获取HTTPClient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //设置HTTPGet请求对象,设置url地址 HttpGet httpGet = new HttpGet(url); //设置请求信息 httpGet.setConfig(getConfig()); //使用HTTPClient发起请求,获取响应 CloseableHttpResponse response = null; try { //使用HTTPClient发起请求,获取响应 response = httpClient.execute(httpGet); //解析响应,返回结果 if(response.getStatusLine().getStatusCode() == 200){ //判断响应体Entity是否不为空 if(response.getEntity() != null) { //下载图片 //获取图片的后缀 String extName = url.substring(url.lastIndexOf(".")); //创建图片名,重命名图片 String picName = UUID.randomUUID().toString() + extName; //下载图片 //声明OutputStream OutputStream outputStream = new FileOutputStream(new File("E://imges/" + picName)); response.getEntity().writeTo(outputStream); //返回图片名称 return picName; } } } catch (IOException e) { e.printStackTrace(); }finally { //关闭response if(response != null){ try { response.close(); } catch (IOException e) { e.printStackTrace(); } } } return ""; }} |
在项目的test类中编写代码获取数据保存到数据库中。
先通过@Resource注解将MovieService类对应的实现类注入进来。
|
1
2
|
@Autowiredprivate MovieService movieService; |
设置请求地址https://movie.douban.com/j/search_subjects
|
1
|
String url = "https://movie.douban.com/j/search_subjects"; |
之后在定义两个Map,用于存储请求头和请求参数信息。
网页请求头。
请求参数,type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0
设置请求参数和请求头代码如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Map<String, String> map = new HashMap<>();Map<String, String> mapTitle = new HashMap<>();//设置请求参数map.put("type", "movie");map.put("tag", "热门");map.put("sort", "recommend");map.put("page_limit", "20");//i为一个变量,从多少条数据开始查询map.put("page_start", i+"");//设置请求头mapTitle.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");mapTitle.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0");mapTitle.put("Cookie", "bid=QNoG_zn4mZY; _pk_id.100001.4cf6=6209709719896af7.1575619506.2.1575940374.1575621362.; __utma=30149280.1889677372.1575619507.1575619507.1575940335.2; __utmz=30149280.1575619507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.986359939.1575619507.1575619507.1575940335.2; __utmz=223695111.1575619507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=QVSP2uvzzDBrpnvHKzZpZEWJnuARZ4aL; ll=\"118259\"; _vwo_uuid_v2=D1FC45CAE50CF6EE38D245C68D7CECC4F|e8d1db73f4c914f0b0be7ed85ac50d14; trc_cookie_storage=taboola%2520global%253Auser-id%3D690a21c0-9ad9-4f8d-b997-f0decb3cfc9b-tuct4e39874; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utmb=30149280.0.10.1575940335; __utmc=30149280; __utmb=223695111.0.10.1575940335; __utmc=223695111; __gads=ID=2f06cb0af40206d0:T=1575940336:S=ALNI_Ma4rv9YmqrkIUNXsIt5E7zT6kZy2w"); |
通过HttpUtils类doGetHtml方法获取该请求响应的数据。
|
1
|
String html = HttpUtils.doGetHtml(url, map, mapTitle); |
请求响应数据格式。
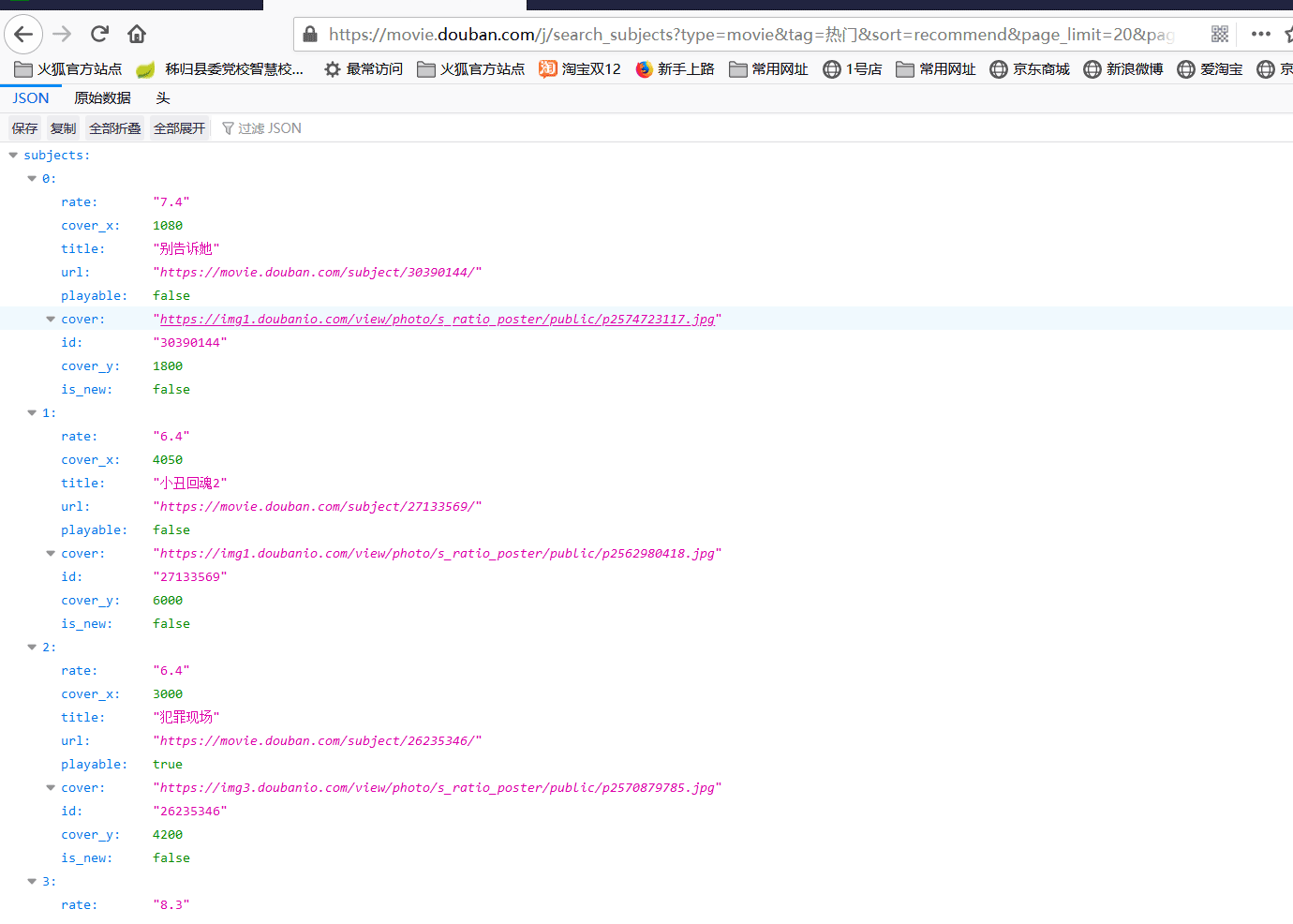
可以看出是一个json格式的数据,我们可以通过阿里巴巴的Fastjson一个json解析库,把它解析成为一个List格式数据。Fastjson基本用法
|
1
2
|
JSONObject jsonObject = JSONObject.parseObject(html);JSONArray jsonArray = jsonObject.getJSONArray("subjects"); |
因为每页查询是是20条数据,我们用一个for循环遍历一下这一页的数据。可以获得电影的标题,评分,图片链接和详情页面的链接,上面JSON数据中的cover属性值为图片的地址。通过图片的链接我们可以调用HttpUtils类的doGetImage方法把图片保存到本地磁盘。
|
1
|
HttpUtils.doGetImage(json.getString("cover")); |
上面请求的数据只能获取到标题,评分和图片,然而我们还有获取导演,主演,和电影时长。这些信息我们点开上面请求到的json数据的url属性值,会打开详情页面,详情页面中有导演,主演,和电影时长信息。
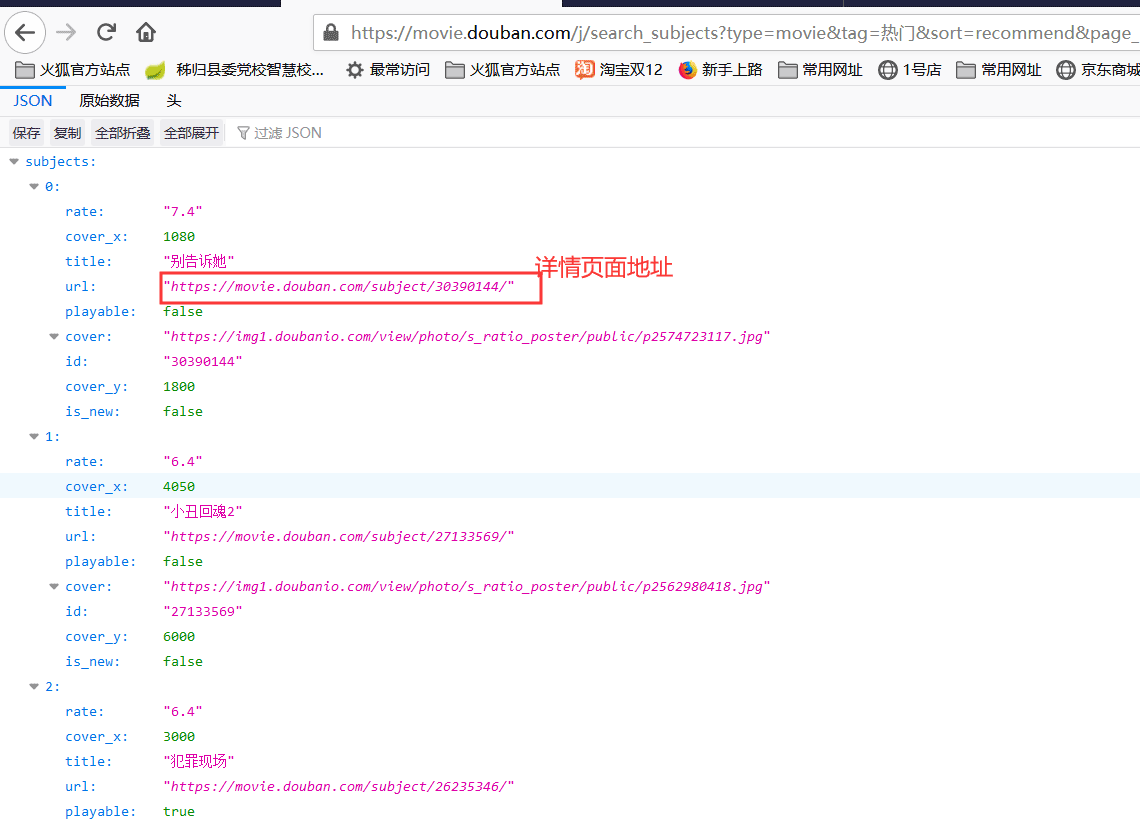
打开的详情页面,我们可以看到导演,主演和电影时长等信息。
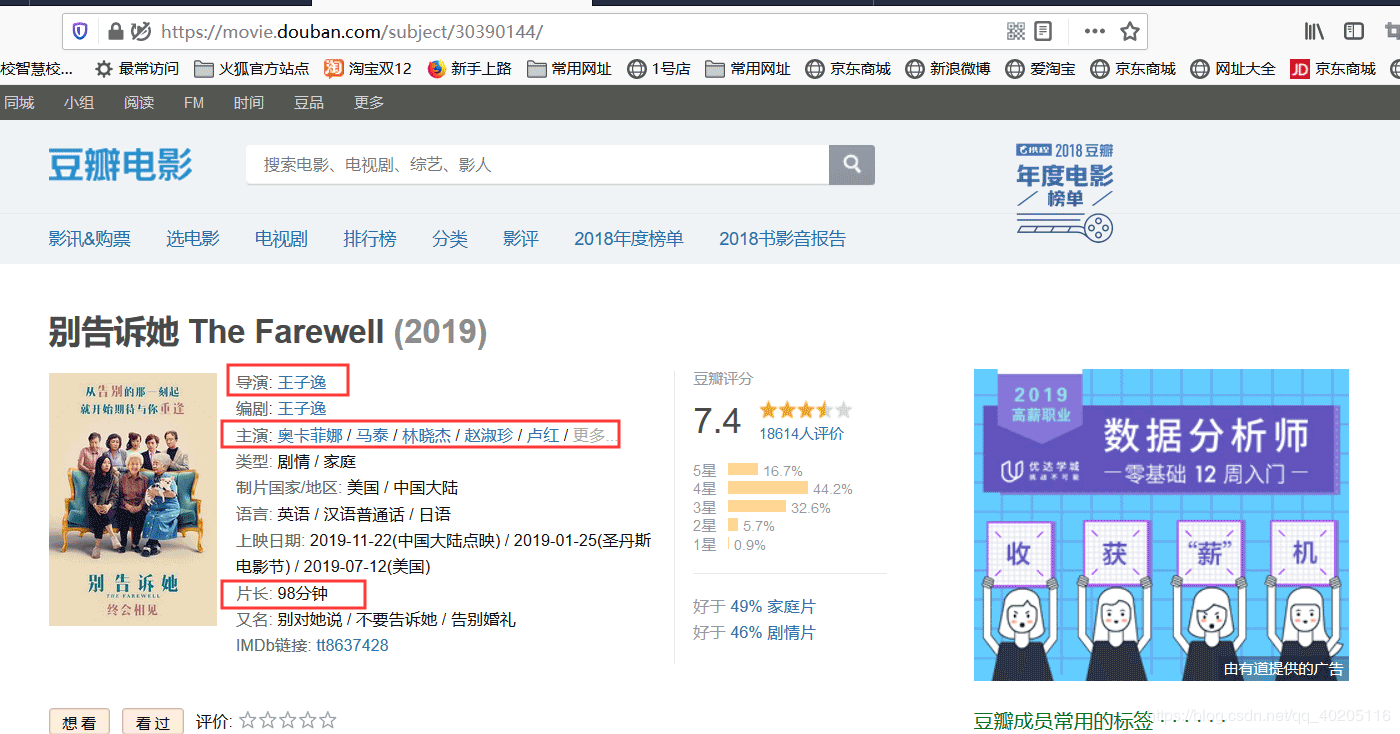
我们查询详情页面的源代码,可以看到导演,主演,电影时长等信息的位置。
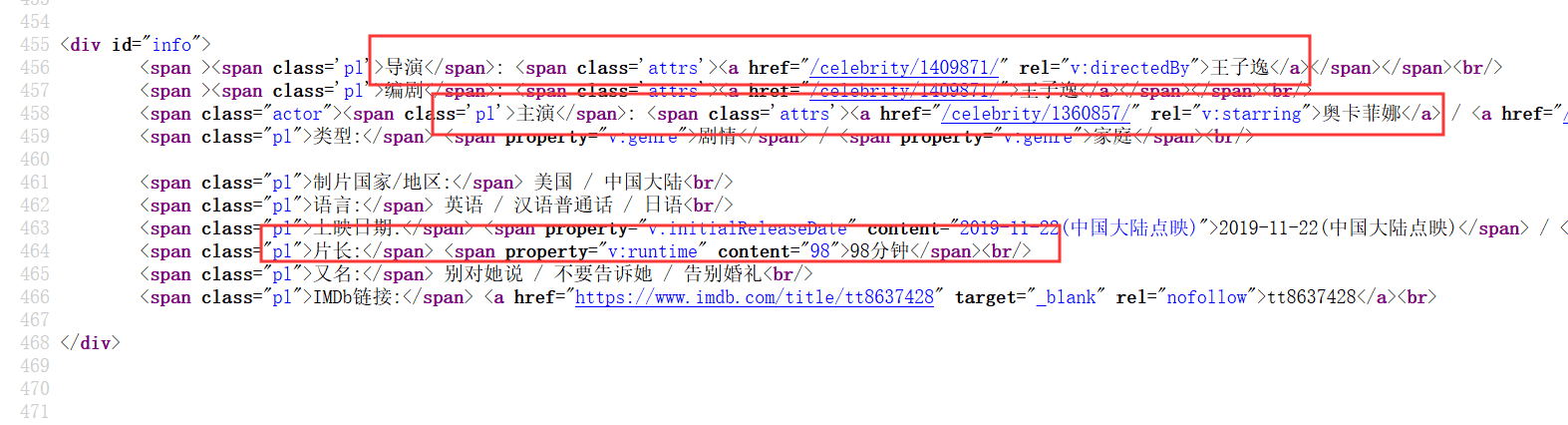
我们在通过HttpUtils类doGetHtml方法获取详情页面的数据,利用Jsoup进行解析,Jsoup是一个可以让java代码解析HTML代码的一个工具,可以参考一下Jsoup官网文档,找到主演,导演和电影时长信息。到这里我们需要的全部信息都获取到了,最后把数据保存起来。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
String url2 = json.getString("url");Map<String, String> map2 = new HashMap<>();Map<String, String> mapTitle2 = new HashMap<>();String html2 = HttpUtils.doGetHtml(url2, map2, mapTitle2);//解析HTML获取DOM对象Document doc = Jsoup.parse(html2);//获取导演名称Element element = doc.select("div#info a[rel=v:directedBy]").first();movie.setDirector(element.text());Elements elements = doc.select("div#info a[rel=v:starring]");//主演String protagonist = "";for (Element e : elements) { protagonist += e.text()+",";}if(!protagonist.equals("")){ protagonist = protagonist.substring(0, protagonist.length()-1);}movie.setProtagonist(protagonist);//获取电影时长element = doc.select("div#info span[property=v:runtime]").first();movie.setDateTime(element.text());movieService.save(movie); |
测试类全部代码如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
import com.alibaba.fastjson.JSONObject;import com.mcy.crawlerdouban.entity.Movie;import com.mcy.crawlerdouban.service.MovieService;import com.mcy.crawlerdouban.util.HttpUtils;import com.alibaba.fastjson.JSONArray;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException;import java.net.URISyntaxException;import java.util.HashMap;import java.util.Map; @SpringBootTestclass CrawlerDoubanApplicationTests { @Autowired private MovieService movieService; @Test public void contextLoads() throws URISyntaxException, IOException { //请求地址 //https://movie.douban.com/j/search_subjects?type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0 String url = "https://movie.douban.com/j/search_subjects"; Map<String, String> map = new HashMap<>(); Map<String, String> mapTitle = new HashMap<>(); //设置请求参数 map.put("type", "movie"); map.put("tag", "热门"); map.put("sort", "recommend"); map.put("page_limit", "20"); //设置请求头 mapTitle.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"); mapTitle.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"); mapTitle.put("Cookie", "bid=QNoG_zn4mZY; _pk_id.100001.4cf6=6209709719896af7.1575619506.2.1575940374.1575621362.; __utma=30149280.1889677372.1575619507.1575619507.1575940335.2; __utmz=30149280.1575619507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.986359939.1575619507.1575619507.1575940335.2; __utmz=223695111.1575619507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=QVSP2uvzzDBrpnvHKzZpZEWJnuARZ4aL; ll=\"118259\"; _vwo_uuid_v2=D1FC45CAE50CF6EE38D245C68D7CECC4F|e8d1db73f4c914f0b0be7ed85ac50d14; trc_cookie_storage=taboola%2520global%253Auser-id%3D690a21c0-9ad9-4f8d-b997-f0decb3cfc9b-tuct4e39874; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utmb=30149280.0.10.1575940335; __utmc=30149280; __utmb=223695111.0.10.1575940335; __utmc=223695111; __gads=ID=2f06cb0af40206d0:T=1575940336:S=ALNI_Ma4rv9YmqrkIUNXsIt5E7zT6kZy2w"); //获取前100条数据,可以自行更改 for(int i = 0; i < 100; i+=20){ map.put("page_start", i+""); String html = HttpUtils.doGetHtml(url, map, mapTitle); JSONObject jsonObject = JSONObject.parseObject(html); JSONArray jsonArray = jsonObject.getJSONArray("subjects"); for(int j = 0; j < jsonArray.size(); j++){ //循环遍历每页数据 Movie movie = new Movie(); JSONObject json = (JSONObject) jsonArray.get(j); movie.setRate(json.getDouble("rate")); movie.setTitle(json.getString("title")); //下载保存图片 HttpUtils.doGetImage(json.getString("cover")); String url2 = json.getString("url"); Map<String, String> map2 = new HashMap<>(); Map<String, String> mapTitle2 = new HashMap<>(); String html2 = HttpUtils.doGetHtml(url2, map2, mapTitle2); //解析HTML获取DOM对象 Document doc = Jsoup.parse(html2); //获取导演名称 Element element = doc.select("div#info a[rel=v:directedBy]").first(); movie.setDirector(element.text()); Elements elements = doc.select("div#info a[rel=v:starring]"); //主演 String protagonist = ""; for (Element e : elements) { protagonist += e.text()+","; } if(!protagonist.equals("")){ protagonist = protagonist.substring(0, protagonist.length()-1); } movie.setProtagonist(protagonist); //获取电影时长 element = doc.select("div#info span[property=v:runtime]").first(); movie.setDateTime(element.text()); movieService.save(movie); } } System.out.println("数据获取完成。。。"); }} |
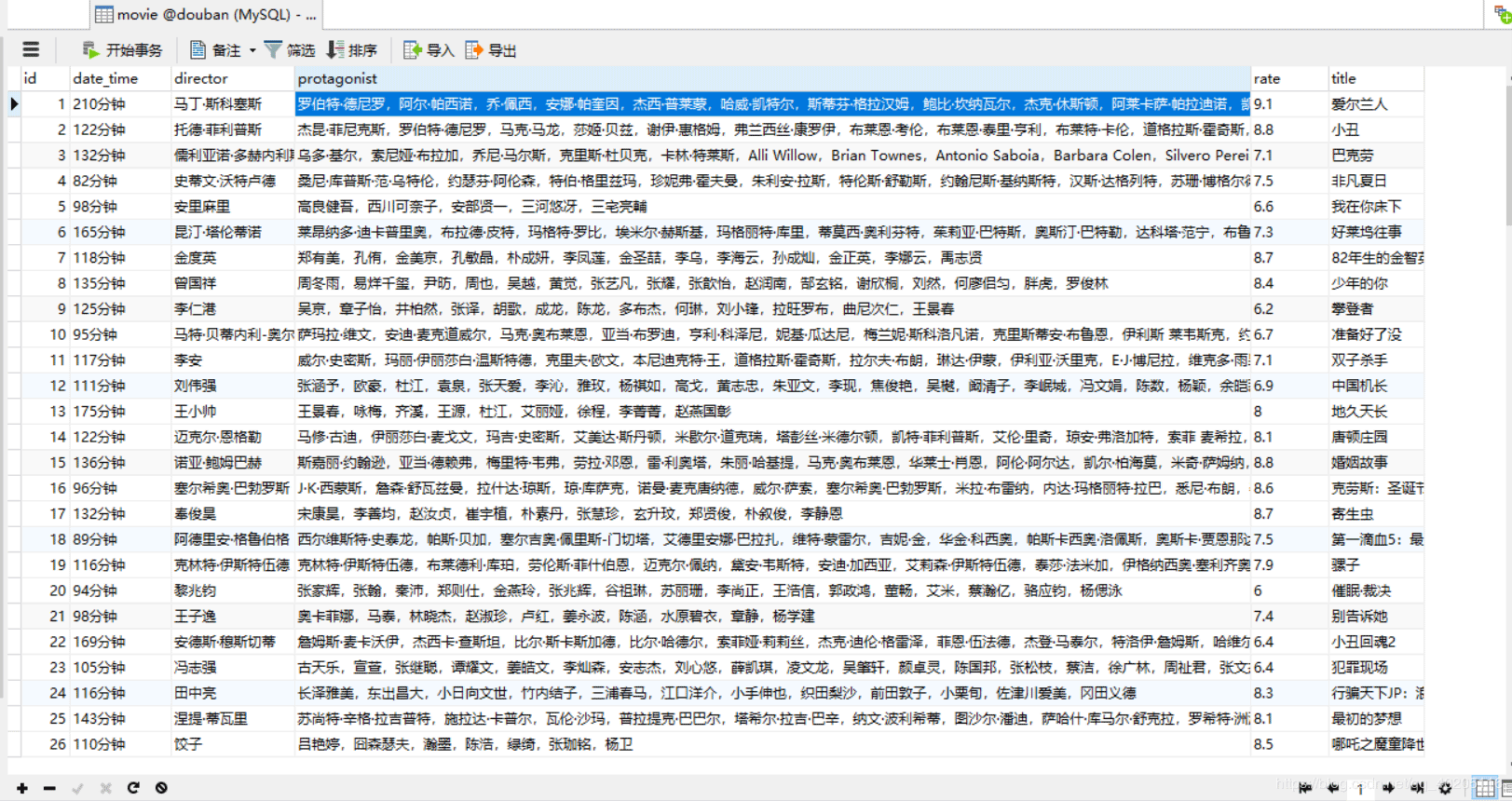
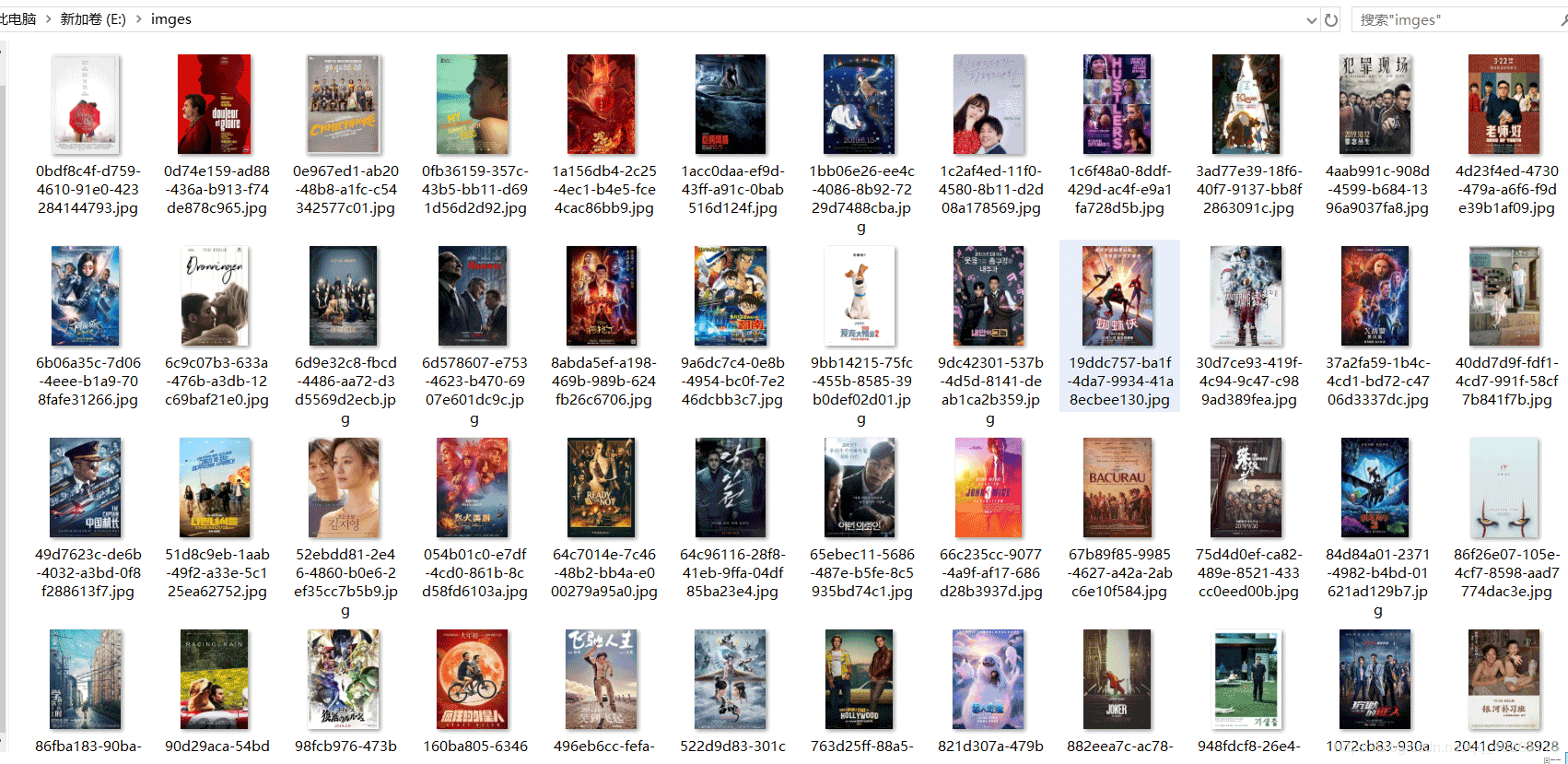
最后我们在mysql数据库中新建一个名为douban的数据库,启动项目,JPA会自动在数据库中新建一张movie表,存放获取到的电影数据。在本地磁盘也会保存电影图片,如图。
电影图片,保存的位置和HttpUtils的doGetImage方法中设置的保存地址一样。
最后放上下载地址https://github.com/machaoyin/crawler-douban