注:本篇文章以新冠疫情数据文件的合并为例。
一、单目录下面的数据合并
将2020下的所有文件进行合并,成一个文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import requests import json import openpyxl import datetime import datetime as dt import time import pandas as pd import csv from openpyxl import load_workbook from sqlalchemy import create_engine import math import os import glob |
|
1 2 3 4 5 6 7 8 |
csv_list=glob.glob(r'D:\Python\03DataAcquisition\COVID-19\2020\*.csv') print("所有数据文件总共有%s" %len(csv_list)) for i in csv_list: fr=open(i,"rb").read() #除了第一个数据文件外,其他不读取表头 with open('../output/covid19temp0314.csv','ab') as f: f.write(fr) f.close() print('数据合成完毕!') |

合并后的数据:

二、使用函数进行数据合并
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
## 02 使用函数进行数据合并 import os import pandas as pd # 定义函数(具有递归功能) def mergeFile(parent,path="",pathdeep=0,filelist=[],csvdatadf=pd.DataFrame(),csvdata=pd.DataFrame()): fileAbsPath=os.path.join(parent,path) if os.path.isdir(fileAbsPath)==True: if(pathdeep!=0 and ('.ipynb_checkpoints' not in str(fileAbsPath))): # =0代表没有下一层目录 print('--'+path) for filename2 in os.listdir(fileAbsPath): mergeFile(fileAbsPath,filename2,pathdeep=pathdeep+1) else: if(pathdeep==2 and path.endswith(".csv") and os.path.getsize(parent+'/'+path)>0): filelist.append(parent+'/'+path) return filelist
# D:\Python\03DataAcquisition\COVID-19 path=input("请输入数据文件所在目录:") filelist=mergeFile(path)
filelist
csvdata=pd.DataFrame() csvdatadf=pd.DataFrame()
for m in filelist: csvdata=pd.read_csv(m,encoding='utf-8-sig') csvdatadf=csvdatadf.append(csvdata) # 由于2023年的数据还没有,所以不合并 |

(* ̄(oo) ̄)注: 这个的等待时间应该会比较长,因为一共有一百九十多万条数据。
将合并后的数据进行保存:
|
1 |
csvdatadf.to_csv("covid190314.csv",index=None,encoding='utf-8-sig') |
|
1 2 |
csvdatadf=pd.read_csv("covid190314.csv",encoding='utf-8-sig') csvdatadf.info() |

读取新冠疫情在2020/0101之前的数据:
|
1 |
beforedf=pd.read_csv(r'D:\Python\03DataAcquisition\COVID-19\before20201111.csv',encoding='utf-8-sig') |
|
1 |
beforedf.info() |


将两组数据合并:
|
1 2 |
tempalldf=beforedf.append(csvdatadf) tempalldf.head() |

三、处理港澳台数据
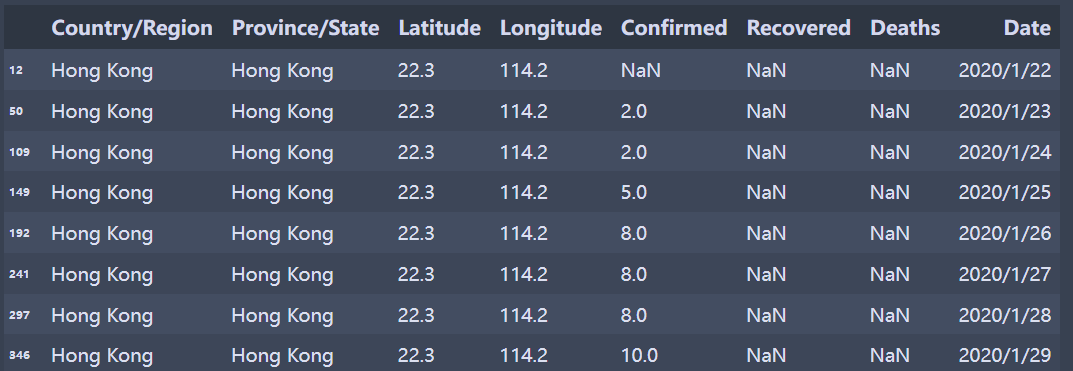
如图所示:要将Country_Region从Hong Kong变成China。澳门和台湾也是如此:
查找有关台湾的数据:
|
1 2 |
beforedf.loc[beforedf['Country/Region']=='Taiwan'] beforedf.loc[beforedf['Country/Region'].str.contains('Taiwan')] |
|
1 2 3 |
beforedf.loc[beforedf['Country/Region'].str.contains('Taiwan'),'Province/State']='Taiwan' beforedf.loc[beforedf['Province/State']=='Taiwan','Country/Region']='China' beforedf.loc[beforedf['Province/State']=='Taiwan'] |

香港的数据处理:
|
1 2 3 4 |
beforedf.loc[beforedf['Country/Region'].str.contains('Hong Kong'),'Province/State']='Hong Kong' beforedf.loc[beforedf['Province/State']=='Hong Kong','Country/Region']='China' afterdf.loc[afterdf['Country_Region'].str.contains('Hong Kong'),'Province_State']='Hong Kong' afterdf.loc[afterdf['Province_State']=='Hong Kong','Country_Region']='China' |
澳门的数据处理:
|
1 2 3 4 |
beforedf.loc[beforedf['Country/Region'].str.contains('Macau'),'Province/State']='Macau' beforedf.loc[beforedf['Province/State']=='Macau','Country/Region']='China' afterdf.loc[afterdf['Country_Region'].str.contains('Macau'),'Province_State']='Macau' afterdf.loc[afterdf['Province_State']=='Macau','Country_Region']='China' |
最终将整理好的数据进行保存:
|
1 2 |
beforedf.to_csv("beforedf0314.csv",index=None,encoding='utf-8-sig') afterdf.to_csv("afterdf0314.csv",index=None,encoding='utf-8-sig') |




