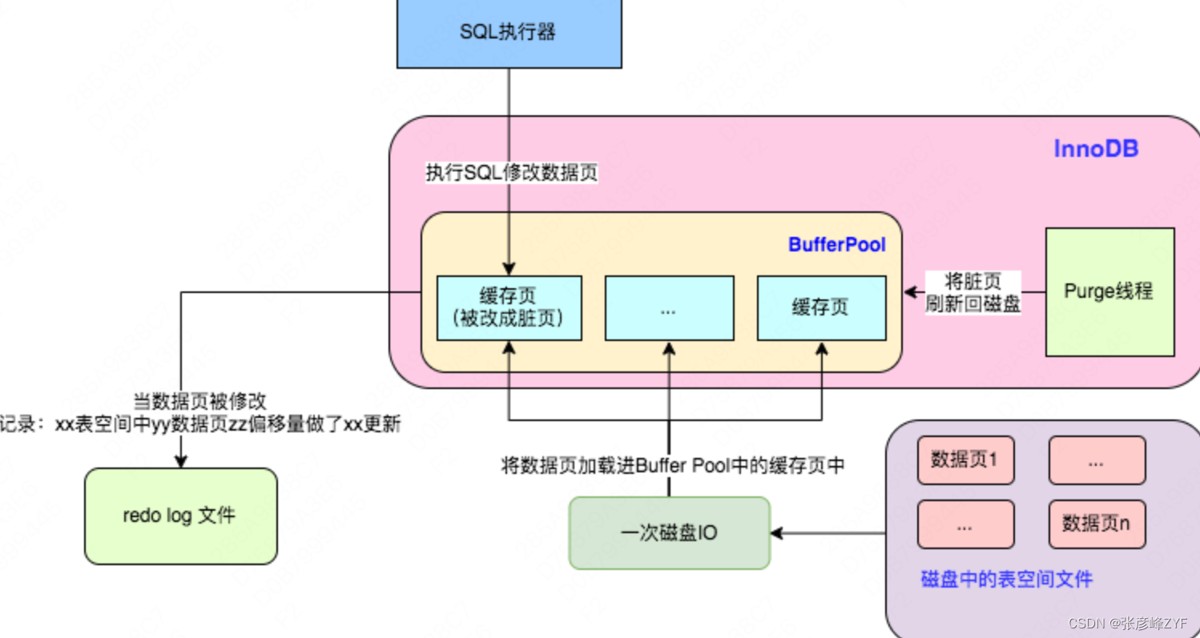
1.SHOW ENGINES
查看执行引擎以及默认引擎。
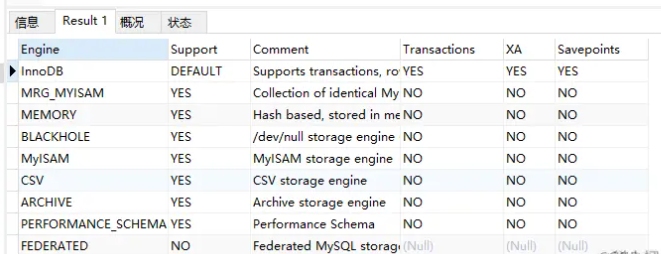
2.SHOW PROCESSLIST
SHOW PROCESSLIST查看当前数据库连接的使用情况,以及各种状态信息,非常有用。SHOW PROCESSLIST; 只列出前100条,如果想全列出请使用SHOW FULL PROCESSLIST;

属性列以及含义:
| id | 一个标识,要kill 一个语句的时候很有用。 |
|---|---|
| user | 显示当前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。 |
| host | 显示这个语句是从哪个ip 的哪个端口上发出的。可用来追踪出问题语句的用户。 |
| db | 显示这个进程目前连接的是哪个数据库。 |
| command | 显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。 |
state列以及含义,mysql列出的状态:
| Checking table | 正在检查数据表(这是自动的)。 |
|---|---|
| Closing tables | 正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。 |
| Connect Out | 复制从服务器正在连接主服务器。 |
| Copying to tmp table on disk | 由于临时结果集大于tmp_table_size(默认16M),正在将临时表从内存存储转为磁盘存储以此节省内存。 |
| Creating tmp table | 正在创建临时表以存放部分查询结果。 |
| deleting from main table | 服务器正在执行多表删除中的第一部分,刚删除第一个表。 |
3.SHOW STATUS LIKE 'InnoDB_row_lock%'
InnoDB 的行级锁定状态变量。
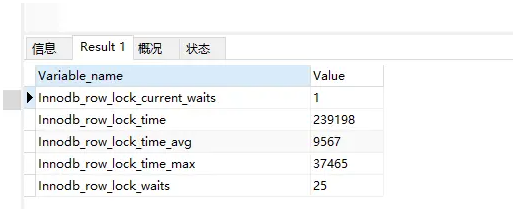
InnoDB 的行级锁定状态变量不仅记录了锁定等待次数,还记录了锁定总时长,每次平均时长,以及最大时长,此外还有一个非累积状态量显示了当前正在等待锁定的等待数量。对各个状态量的说明如下:
- InnoDB_row_lock_current_waits:当前正在等待锁定的数量;
- InnoDB_row_lock_time:从系统启动到现在锁定总时间长度;
- InnoDB_row_lock_time_avg:每次等待所花平均时间;
- InnoDB_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
- InnoDB_row_lock_waits:系统启动后到现在总共等待的次数;
对于这5个状态变量,比较重要的主要是InnoDB_row_lock_time_avg(等待平均时长),InnoDB_row_lock_waits(等待总次数)以及InnoDB_row_lock_time(等待总时长)这三项。尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手指定优化计划。
如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDB Monitors 来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
4.SHOW ENGINE INNODB STATUS
SHOW ENGINE INNODB STATUS命令会输出当前InnoDB监视器监视到的很多信息,它输出就是一个单独的字符串,没有行和列,内容分为很多小段,每一段对应innodb存储引擎不同部分的信息,其中有一些信息对于innodb开发者来说非常有用。
有一节LATEST DETECTED DEADLOCK,就是记录的最后一次死锁信息, 如下案例:
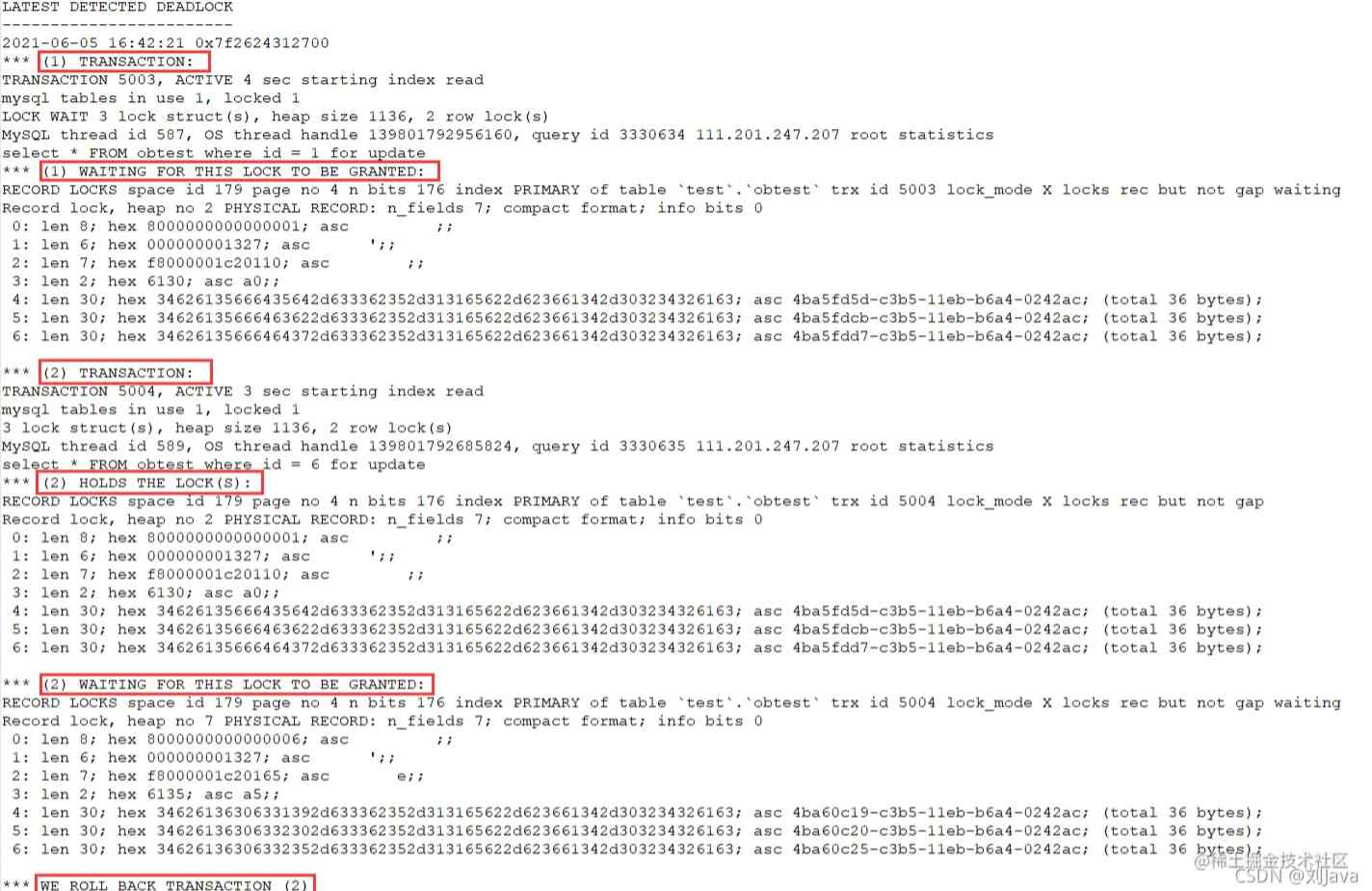
- “(1) TRANSACTION”显示第一个事务的信息;
- “(1) WAITING FOR THIS LOCK TO BE GRANTED”显示第一个事务等待的锁信息
- “(2) TRANSACTION”显示第二个事务的信息;
- “(2) HOLDS THE LOCK(S)” 显示的是第二个事务持有的锁信息;
- “(2) WAITING FOR THIS LOCK TO BE GRANTED” 显示第二个事务等待的锁信息
- 最后一行表示处理结果,比如“WE ROLL BACK TRANSACTION (2),表示回滚了第二个事务。
5.SHOW INDEXS
SHOW INDEXS查询一个表中的索引信息:SHOW INDEXES FROM table_name;
建表的sql如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE contacts( contact_id INT AUTO_INCREMENT, first_name VARCHAR(100) NOT NULL comment 'first name', last_name VARCHAR(100) NOT NULL, email VARCHAR(100), phone VARCHAR(20), PRIMARY KEY(contact_id), UNIQUE(email), INDEX phone(phone) , INDEX names(first_name, last_name) comment 'By first name and/or last name' ); |
存储过程插入五万条数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
CREATE PROCEDURE zqtest ( ) BEGIN DECLARE i INT DEFAULT 0; DECLARE j VARCHAR ( 100 ) DEFAULT 'first_name'; DECLARE k VARCHAR ( 100 ) DEFAULT 'last_name'; DECLARE l VARCHAR ( 100 ) DEFAULT 'email'; DECLARE m VARCHAR ( 20 ) DEFAULT '11111111111';
SET i = 0; START TRANSACTION; WHILE i < 50000 DO IF MOD ( i, 100 ) = 0 THEN
SET j = CONCAT( 'first_name', i );
END IF; IF MOD ( i, 200 ) = 0 THEN
SET k = CONCAT( 'last_name', i );
END IF; IF MOD ( i, 50 ) = 0 THEN
SET m = CONCAT( '', CAST( m as UNSIGNED) + i );
END IF; INSERT INTO contacts ( first_name, last_name, email, phone ) VALUES ( j, k, CONCAT(l,i), m );
SET i = i + 1;
END WHILE; COMMIT;
END; |
使用show index from contacts;后结果如下:

字段说明:
| Table | 表名 |
|---|---|
| Non_unique | 唯一索引为0,其他索引为1。主键索引也是唯一索引。 |
| Key_name | 索引名。如果名字相同则表明是同一个索引,并且是联合索引,每一行都表示联合索引中的某一个列。 |
| Seq_in_index | 索引中的列序列号,从1开始。也可以表明该列在联合索引中的顺序。 |
| Column_name | 索引列名,如果是联合索引则是某一个列的名字 |
| Collation | 列以什么方式存储在索引中,大概意思就是字符序。 |
| Cardinality | 一个索引上不同的值的个数,我们称之为“基数”(cardinality),也称为区分度,这个基数越大,索引的区分度越好。该值的统计不一定是准确的,可以使用ANALYZE TABLE修正。 |
| Sub_part | 前缀索引。如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列的值都被编入索引,则为NULL。 |
| Packed | 关键字如何被压缩。如果没有被压缩,则为NULL。压缩一般包括压缩传输协议、压缩列解决方案和压缩表解决方案。 |
| Null | 如果列值可以包含null,则为YES |
| Index_type | 索引结构类型,常见有FULLTEXT,HASH,BTREE,RTREE |
| Comment、Index_comment | 注释 |
6.ALTER TABLE xx ENGINE = INNODB
重建表,包括索引结构。可以消除索引页分裂以及删除数据时留下的磁盘碎片。
7.ANALYZE TABLE
不是重建表,只是对表的索引信息做重新统计,没有修改数据,这个过程中加了MDL读锁。可以用来修正show index from tablename;中统计索引的Cardinality是数据异常的情况。