背景
说到哈夫曼树大家应该都不陌生,它是一颗根据叶子节点权重进行构造的树,它能够使得树的带权路径长度最短。
而哈夫曼编码就是基于哈夫曼树,这是一个经典的压缩算法,可以根据权重给某个值分配一个01串,用这个较短的01串表达这个较长的值,权重越高的值的01串会越短,从而提高压缩率;
同时哈夫曼编码也是前缀不重复的,也就是不会有某个编码是另外一个编码的前缀,这样我们就能够把编码后的字符连续的存放,不需要其他额外的信息也能解码。
比如对于字符(a,b,c)对应的编码是:
| 字符 | 编码 |
|---|---|
| h | 110 |
| e | 111 |
| l | 10 |
| o | 0 |
可以看到上面的编码都不是其他编码的前缀,我们考虑对hello这个单词进行编码:11011110100,则解码过程就是从左读取,如果发现表里有对应的编码,则找到对应的字符,然后继续下一个字符解码:
| 当前编码值 | 字符 |
|---|---|
| 1 | |
| 11 | |
| 110 | h |
| 1 | |
| 11 | |
| 111 | e |
| 1 | |
| 10 | l |
| 1 | |
| 10 | l |
| 0 | o |
算法原理
定义
- 路径长度:从根节点到叶子节点的长度,也就是编码长度。
- 节点权重:一般使用字符出现的概率。
- 带权路径长度:路径长度*节点权重。
- 树的带权路径长度:整棵树每个叶子节点的带权路径长度之和。
- 节点编码:往左节点走为0,往右节点走为1,到节点经过的路径就是节点的编码。
树构建过程
- 从树的集合S中,找到权重最小的两棵树A和B(只有单个节点也是一棵树);
- 产生一个新节点C;
- 把A和B的权重加起来作为新节点C的权重,把A和B作为节点C的左右子节点;
- 节点C加入集合S;
- 重复上面过程直到集合只有一棵树。
比如对于hello这个单词,我们可以知道每个字符出现的次数:
| 字符 | 出现次数 |
|---|---|
| h | 1 |
| e | 1 |
| l | 2 |
| o | 1 |
把这个出现次数作为每个字符的权重:
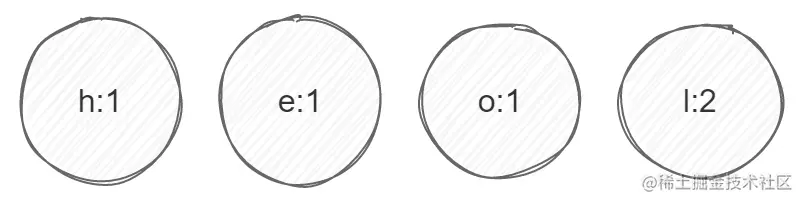
①选节点h和e(因为权重最小),生成新节点(绿色节点),新节点权重为h+e:
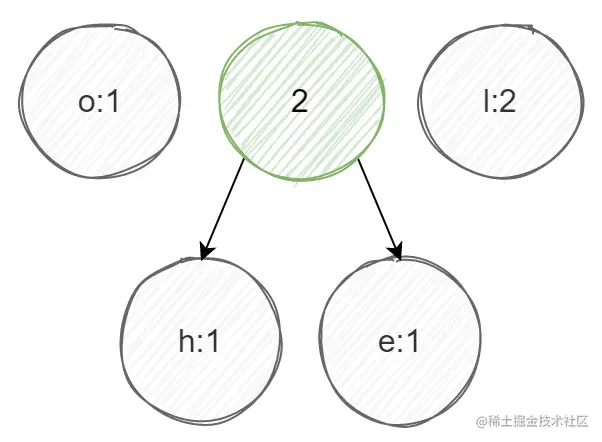
②选节点o和绿色节点(因为权重最小),生成新节点(蓝色节点),新节点权重为o+绿色节点:
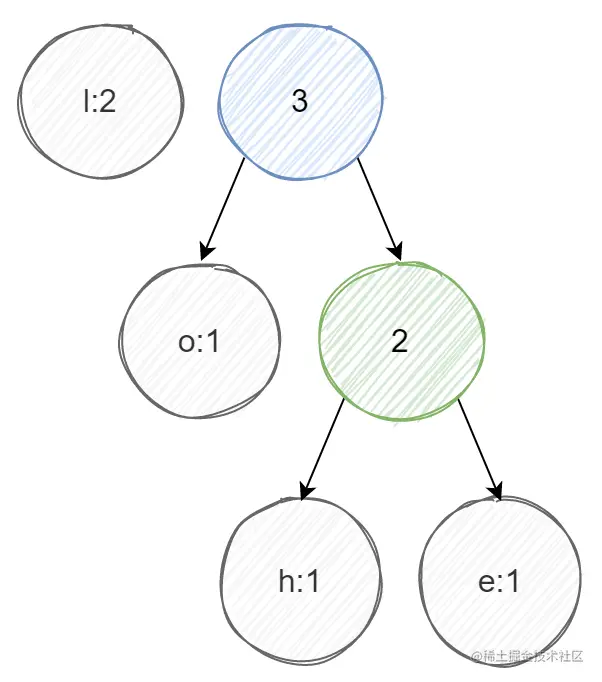
③选节点l和蓝色节点(因为权重最小),生成新节点(红色节点),新节点权重为l+蓝色节点:
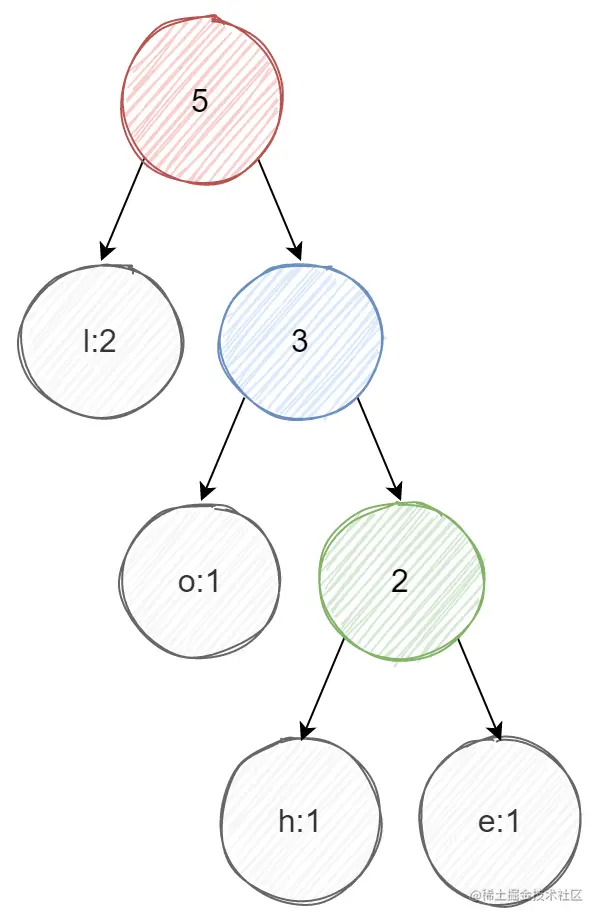
编码
根据上面的树,按照往左走0,往右1,可以得到每个字符的编码:
| 字符 | 编码 |
|---|---|
| h | 110 |
| e | 111 |
| l | 0 |
| o | 10 |
根据上表则hello的编码为:1101110010,按照二进制为10位,也就是只需要两个字节就可以存储。比直接用hello的ASCII编码需要5个字节少3个字节。
HTTP2的应用
了解HTTP2的同学肯定知道HTTP2是一个二进制协议,为了减小传输体积使用了头部压缩算法HPACK,算法有三个组成部分:静态表编码、动态表编码和哈夫曼编码。
为了使用哈夫曼编码,HPACK统计了大量HTTP头部,根据字符出现频率将ASCII编码为哈夫曼编码:
| 字符 | 编码 | 二进制长度 |
|---|---|---|
| '0' | 00000 | 5 |
| '1' | 00001 | 5 |
| '2' | 00010 | 5 |
| '3' | 011001 | 6 |
| 'A' | 100001 | 6 |
| 'B' | 1011101 | 7 |
| 'C' | 1011110 | 7 |
| 'D' | 1011111 | 7 |
通过减小出现频率高的字符的编码长度,从而减小整个HTTP头部的大小,提高传输效率,
