HashMap 的线程不安全
HashMap 的线程不安全主要体现在下面两个方面
- 在 jdk 1.7 中,当并发执行扩容操作时会造成环形链和数据丢失的情况
- 在 jdk 1.8 中,在并发执行 put 操作时会发生数据覆盖的情况
对于 jdk 1.7 中 HashMap 的线程不安全,暂且不谈了,我们主要看看 jdk 1.8 中的
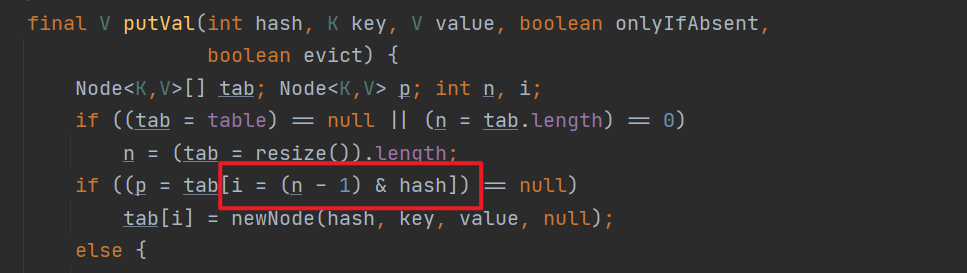
HashMap 中的 put() 方法
该 put() 方法是 jdk 1.8 中的
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
|
数据的覆盖一
第 13 行代码是判断是否出现 hash 冲突的,假设两个线程 A、B 都在进行 put 操作,并且它们 put 数据的 key 的 hash 值是相同的,同时它们 keyA == keyB 为 true 或者 keyA.equals(keyB) 为 true,也就是说它们 put 数据的 value 是不相同的
当线程 A 执行完第 13 行代码后由于时间片耗尽导致被挂起,而线程 B 得到时间片后在该单链表处插入了元素,完成了正常的插入
然后线程 A 获得时间片,由于之前已经进行了 hash 冲突的判断,所有此时不会再进行判断,而是直接进行插入覆盖,这就导致了线程 B 插入的数据被线程 A 覆盖了,从而发生了线程不安全
数据的覆盖二
第 58 行处有个 ++size,我们这样想,还是线程 A、B,这两个线程同时进行 put 操作时,假设当前 HashMap 的 size 大小为 10
当线程 A 执行到第 58 行代码时,从主内存中获得 size 的值为 10 后准备进行 +1 操作,但是由于时间片耗尽只好让出 CPU
于是线程 B 得到 CPU 调度,还是从主内存中拿到 size 的值 10 进行 +1 操作,完成了 put 操作,并将 size = 11 写回了主内存
然后线程 A 再次得到 CPU 调度,并继续执行(此时 size 的值仍为10),当执行完 put 操作后,还是将 size = 11 写了回内存。
此时,线程 A、B 都执行了一次 put 操作,但是 size 的值只增加了 1,所有说还是由于数据覆盖又导致了线程不安全
|
1 2 |
|