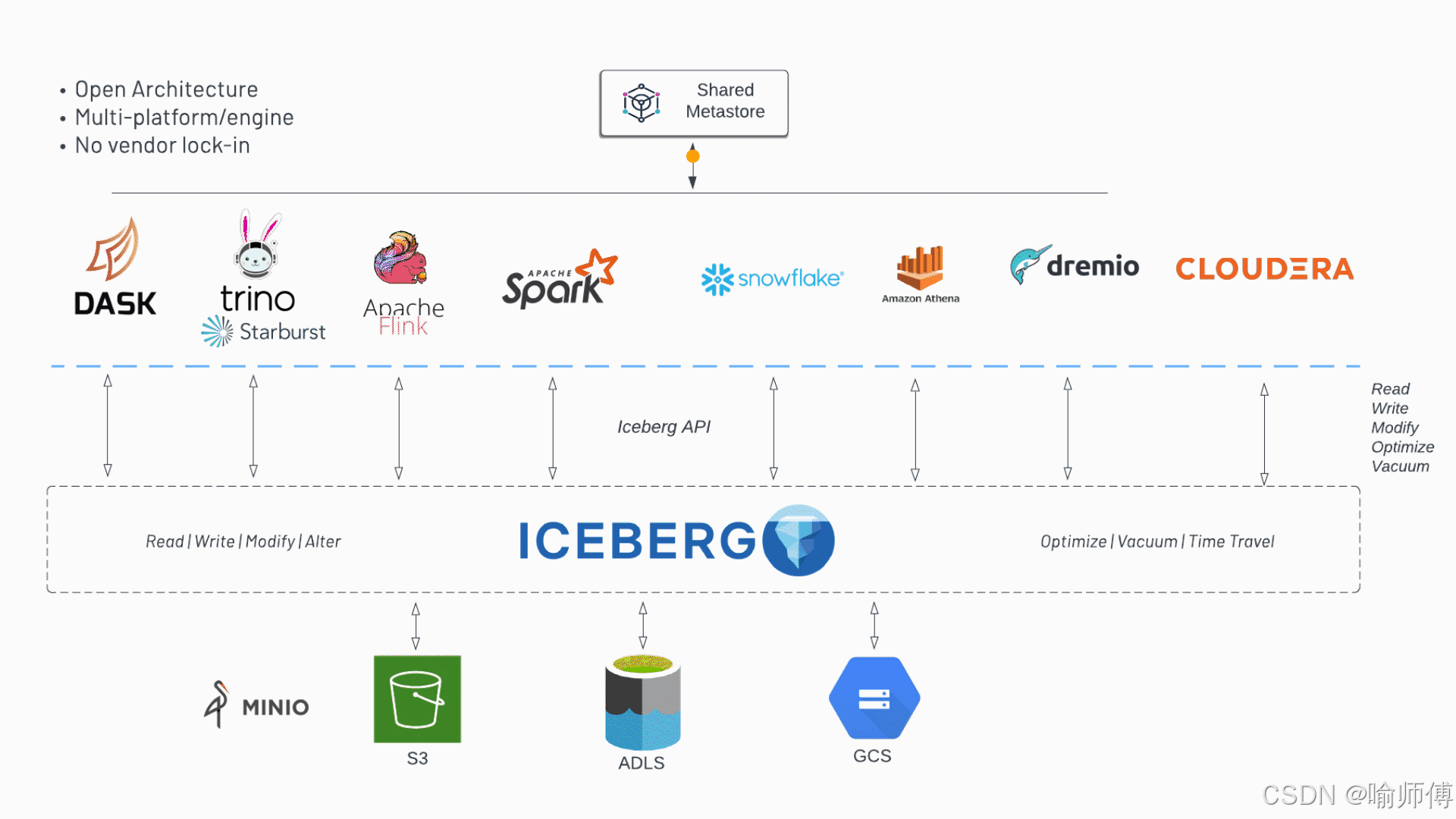
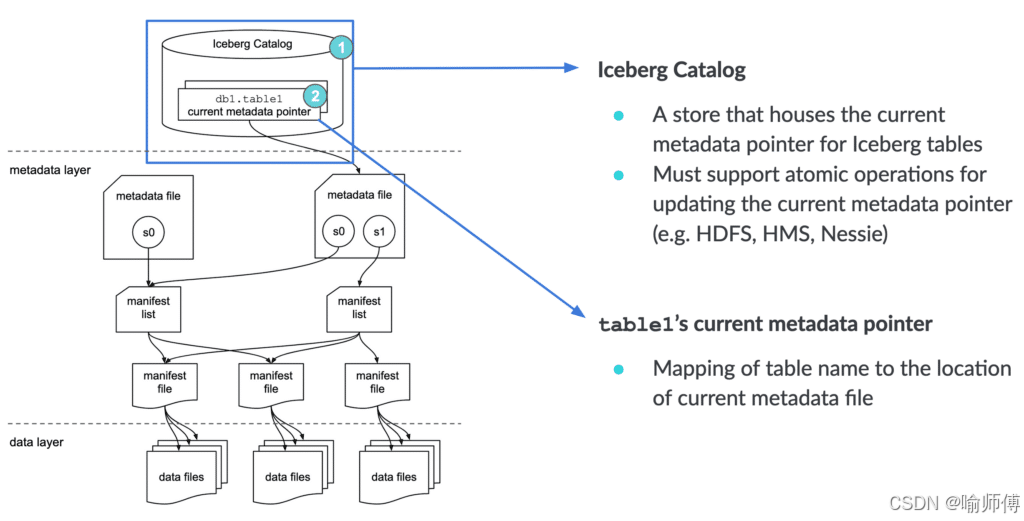
Apache Iceberg 底层数据存储

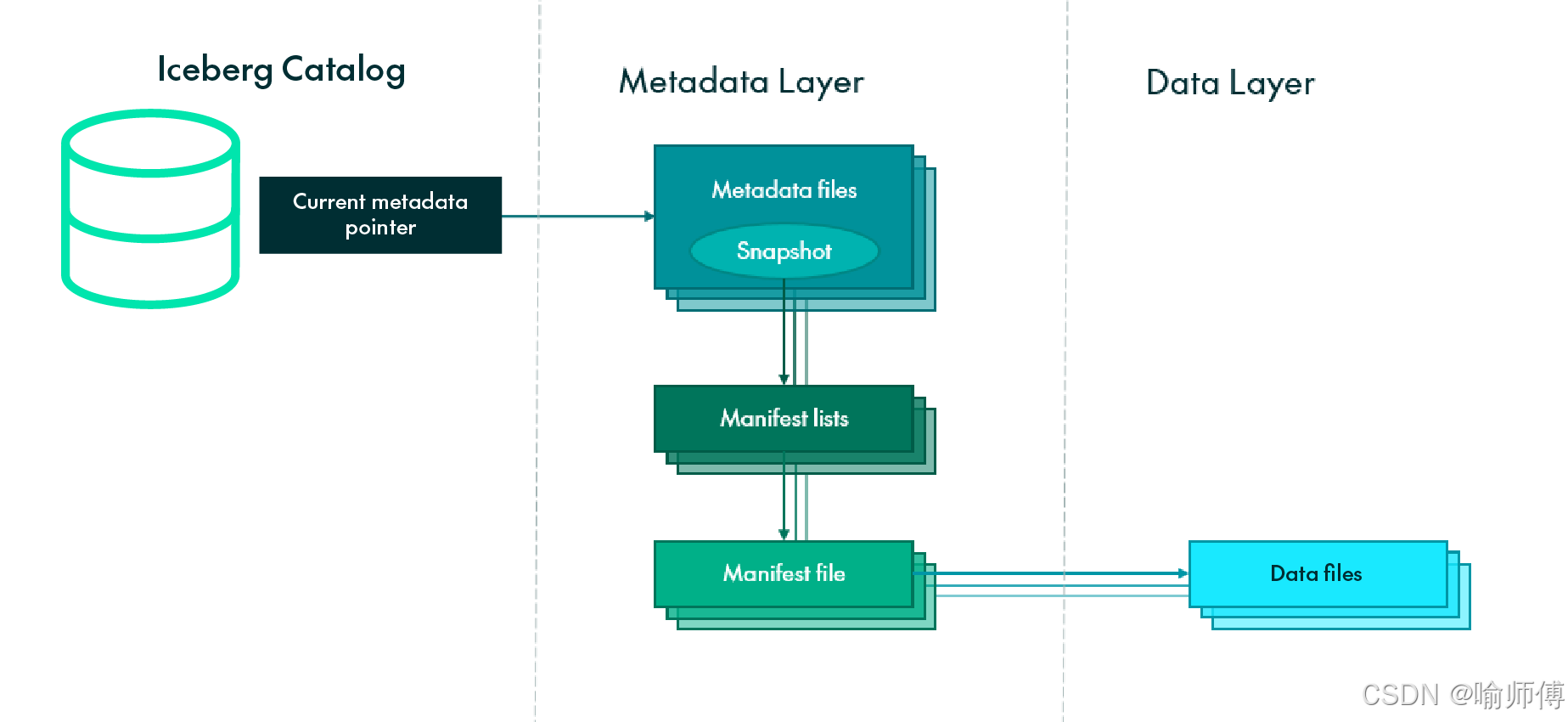
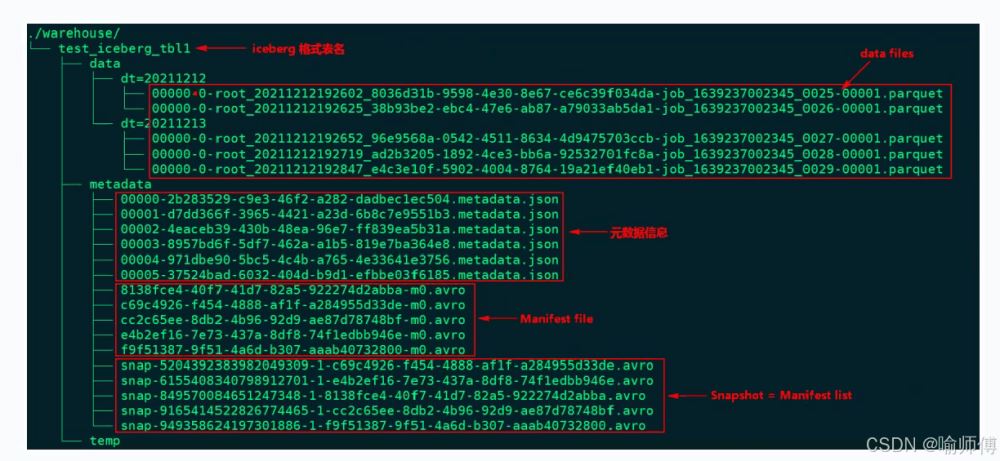
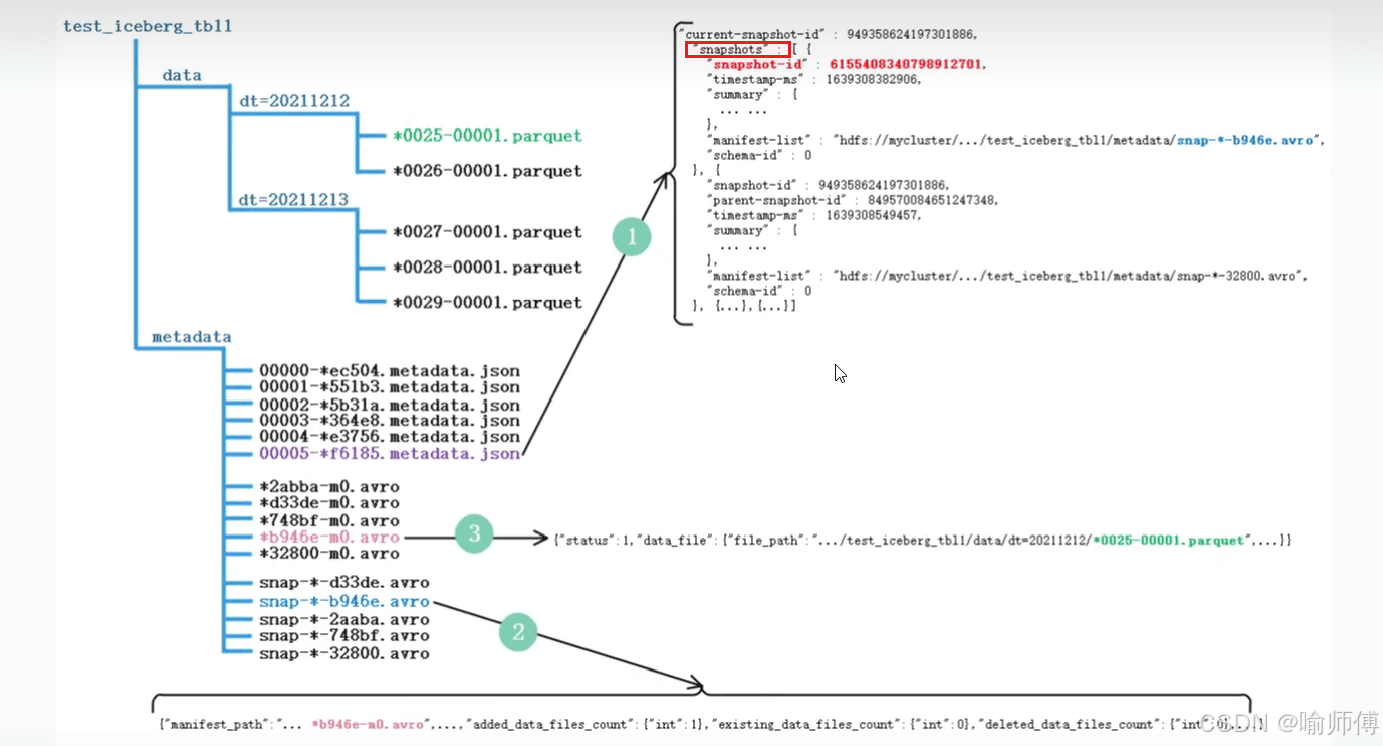
Iceberg 数据组织图(HDFS): 5个SnapShot对应5个manifest list清单列表。
1.查询最新快照数据
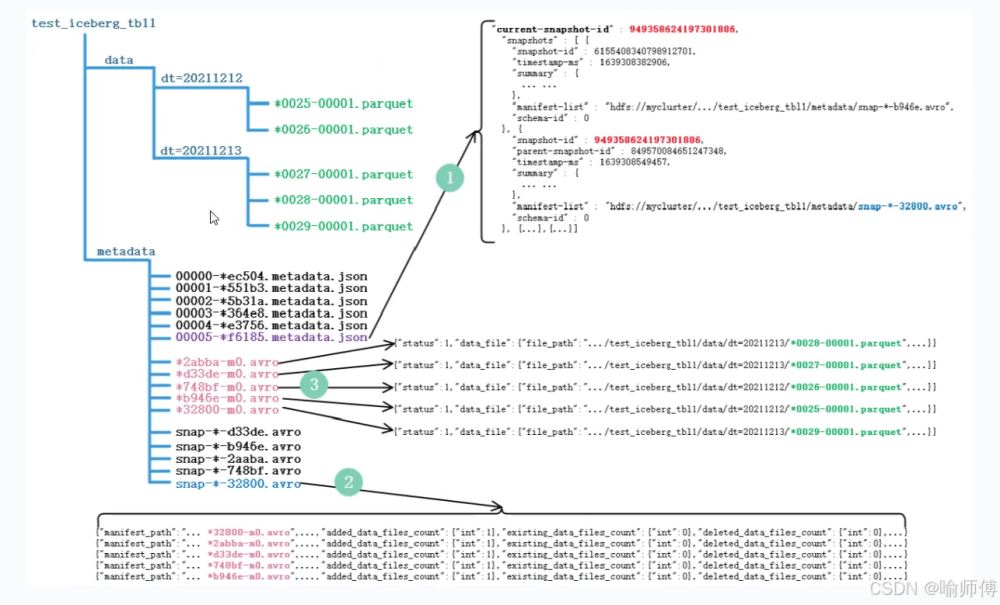
获取最新元数据
获取 Iceberg 表的最新元数据文件,eg:00000-ec504.metadata.json。
解析元数据
从元数据文件中提取以下信息:
- 当前表的快照 ID:949358624197301886
- 所有快照信息:在 JSON 中的 snapshots 数组。
获取快照文件信息
根据快照 ID,找到对应的 Avro 文件信息,eg:snap--32800.avro。
在该快照文件中,提取 Manifest File清单文件信息:
- *32800-m0.avro
- *2abba-m0.avro
- *d33de-m0.avro
- *748bf-m0.avro
- *b946e-m0.avro
读取最新数据
读取以上 Manifest File清单文件中描述的 Parquet 数据文件(Data files)。
分析 Snap 文件
在 snap--32800.avro 文件中,可以找到以下属性:
- deleted data files count
- added data files count
- existing data files count
判断数据文件状态
Iceberg 根据 deleted data files count 判断是否存在被删除的数据:
如果该值大于 0,表示对应的 Manifest 文件中有已删除的数据。读取数据时,无需读取这些被删除的文件。
Manifest 清单文件分析
根据 Manifest 清单文件,找到对应的 Parquet 文件存储位置。
每个 Manifest 文件中有 status 属性:
1:代表对应的 Parquet 文件为新增文件,需要读取。
2:代表 Parquet 文件被删除。
2.查询指定快照(历史快照)数据
Apache Iceberg 支持查询历史上任何时刻的快照。
要查询特定快照,需要指定 snapshot-id 属性,可以通过 Spark 或 Flink 实现。
在 Spark 中查询指定快照的数据:
|
1 2 3 4 |
spark.read .option("snapshot-id", 6155488348798912701L) .format("iceberg") .load("path") |
查询某个快照数据的原理:
指定快照 ID
在读取数据时,通过 snapshot-id 指定要查询的快照。
查找快照信息
Iceberg 会根据指定的快照 ID 检索相关的元数据(如下metadata里面的snapshots数组),包括快照中包含的数据文件和 Manifest 文件。
3.根据时间戳查询某个快照数据
Apache Iceberg 支持通过 as-of-timestamp 参数读取特定时间戳的快照数据,通常也是通过 Spark 或 Flink 实现。
在 Spark 中根据时间戳查询数据:
|
1 2 3 4 |
spark.read .option("as-of-timestamp", "时间戳") .format("iceberg") .load("path") |
指定时间戳
使用 as-of-timestamp 指定要查询的时间点。
查找快照信息
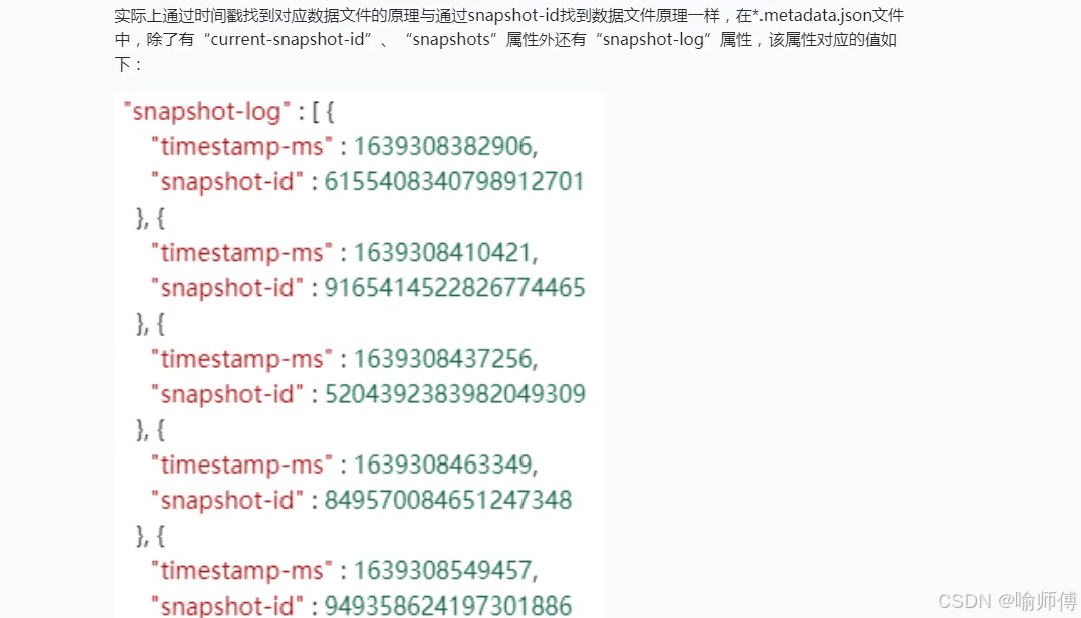
Iceberg 将查找与时间戳对应的快照,利用 *.metadata.json 文件中的信息。
属性解析
在元数据文件中,除了 current-snapshot-id 和 snapshots 属性外,还有一个 snapshot-log 属性,该属性记录了快照的历史信息。