一、group_concat函数的功能
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。group_concat函数首先根据group by指定的列进行分组,将同一组的列显示出来,并且用分隔符分隔。由函数参数(字段名)决定要返回的列。例如:
|
1 2 3 4 5 6 7 8 9 10 11 |
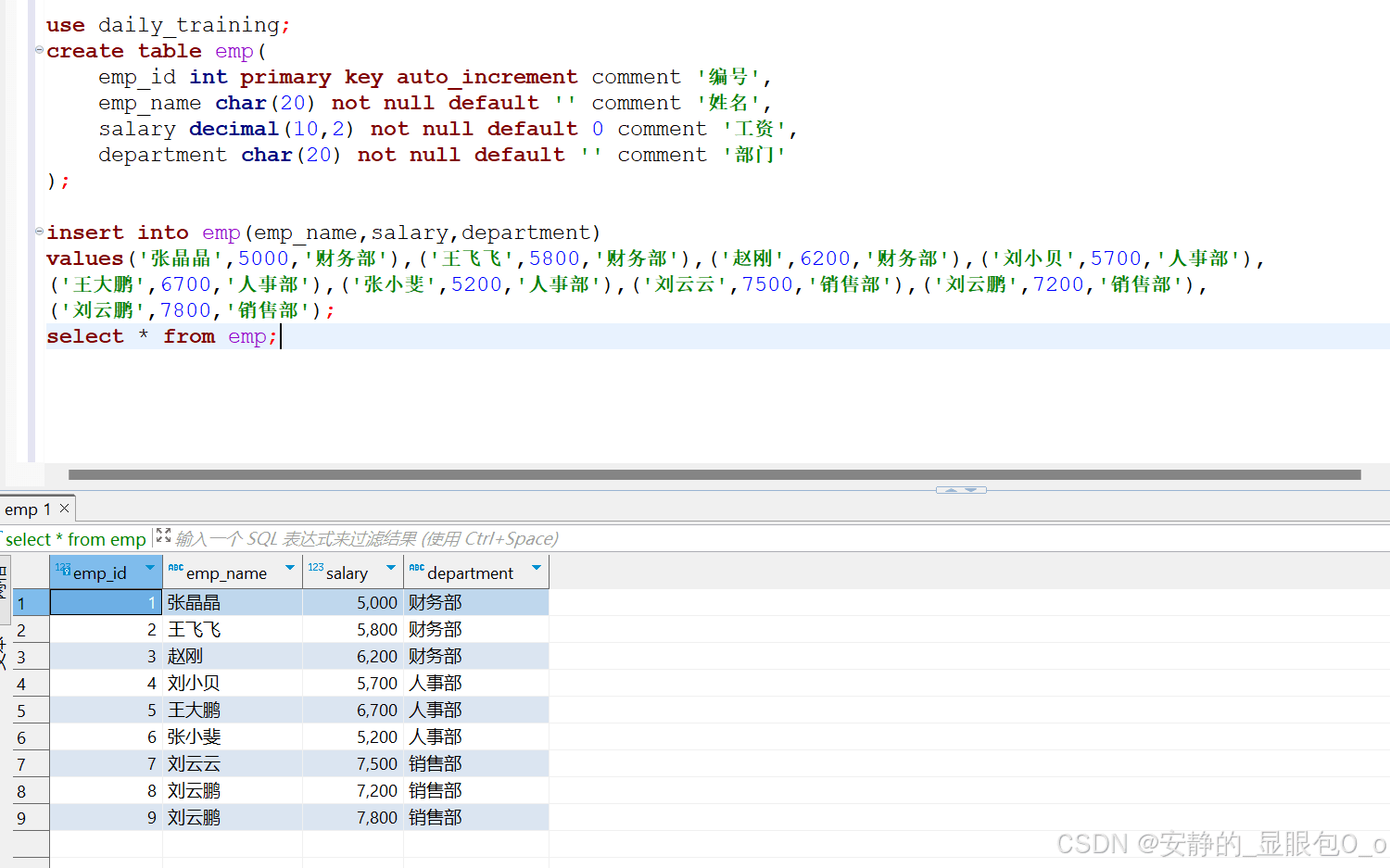
create table emp( emp_id int primary key auto_increment comment '编号', emp_name char(20) not null default '' comment '姓名', salary decimal(10,2) not null default 0 comment '工资', department char(20) not null default '' comment '部门' );
insert into emp(emp_name,salary,department) values('张晶晶',5000,'财务部'),('王飞飞',5800,'财务部'),('赵刚',6200,'财务部'),('刘小贝',5700,'人事部'), ('王大鹏',6700,'人事部'),('张小斐',5200,'人事部'),('刘云云',7500,'销售部'),('刘云鹏',7200,'销售部'), ('刘云鹏',7800,'销售部'); |
二、group_concat函数的语法
group_concat([distinct] 字段名 [order by 排序字段 asc/desc] [separator ‘分隔符’])
|
1 |
group_concat([distinct] 字段名 [order by 排序字段 asc/desc] [separator '分隔符']) |
说明:
(1)使用distinct可以排除重复值;
(2)如果需要对结果中的值进行排序,可以使用order by子句;
(3)separator是一个字符串值,默认为逗号。
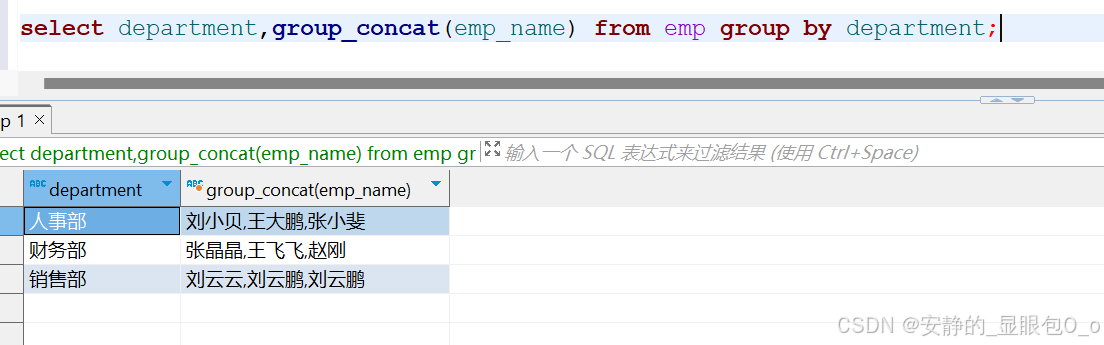
1.group_concat(emp_name):只指定了字段名,销售部有两个同名的也全部显示出来,并且姓名的连接顺序就是表中的记录顺序,连接的分隔符为逗号,结果如下:
|
1 |
select department,group_concat(emp_name) from emp group by department; |
|
1 |
select department,group_concat(emp_name SEPARATOR ',') as e_name from emp group by department; |
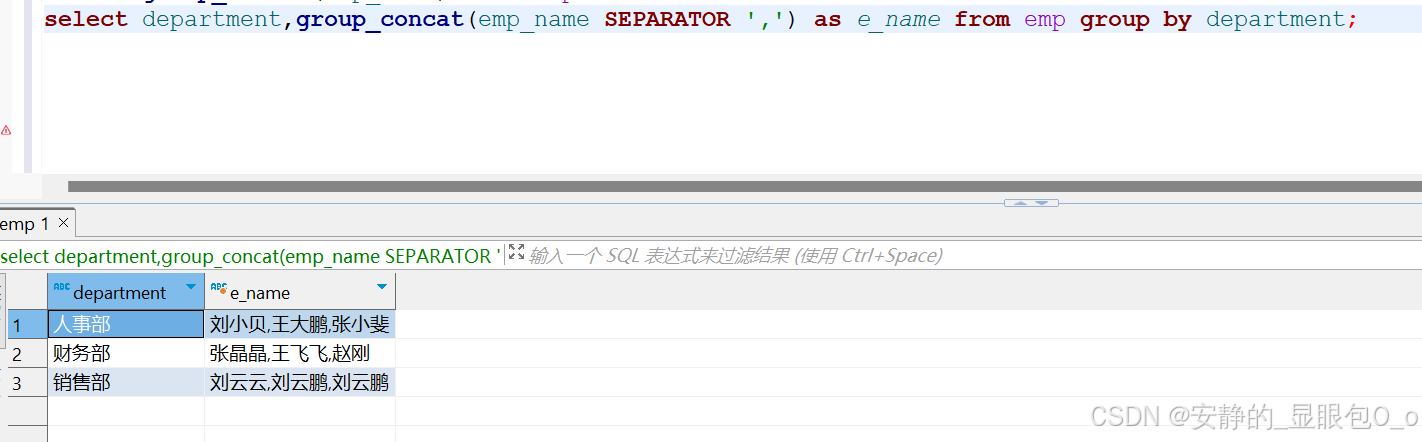
参数解释:
- emp_name:要合并的列名。
- SEPARATOR:可选参数,用于指定合并结果中值之间的分隔符,默认为逗号,
添加了distinct参数,则销售部两个同名的员工只显示一个,结果如下:
|
1 2 |
select department,group_concat(distinct emp_name) from emp group by department; |
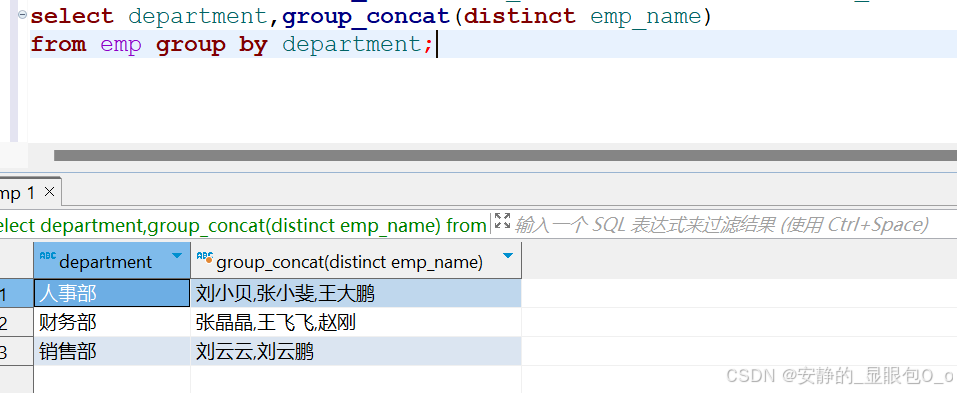
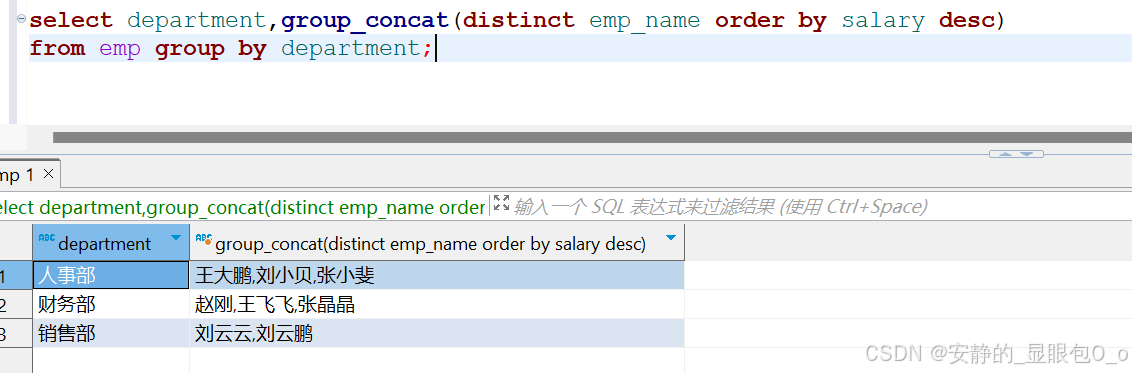
4. 添加了order by参数,表中的记录按salary降序排列,然后再把姓名连接起来,结果如下:
|
1 2 |
select department,group_concat(distinct emp_name order by salary desc) from emp group by department; |
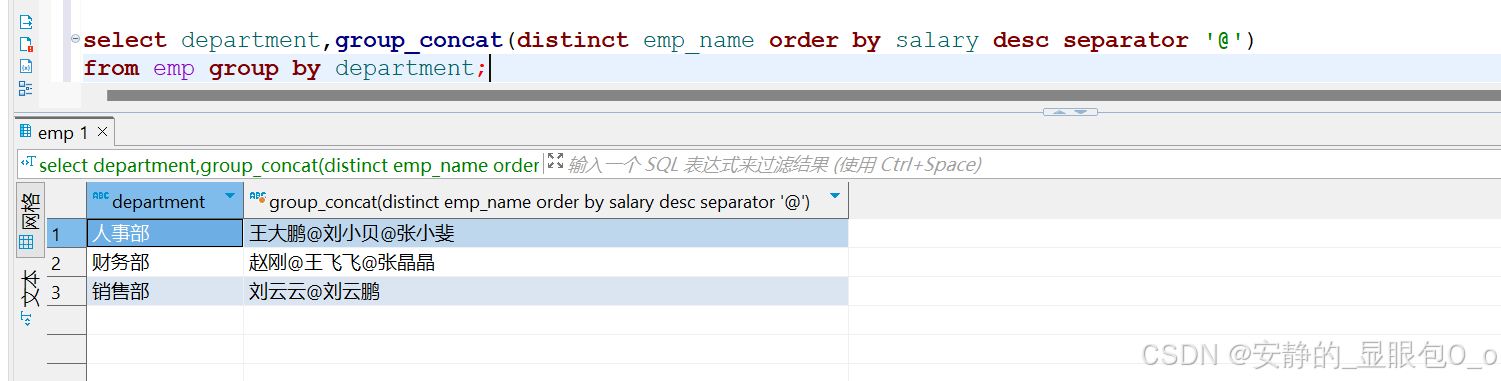
5.分隔符修改为@符号,结果如下:
|
1 2 |
select department,group_concat(distinct emp_name order by salary desc separator '@') from emp group by department; |