需求来源
今天甲方这边要查看一个机车的周时数据(就是一个机车从到我的管辖范围内,到出我的管辖内所用的时间),那这个它会跑很多次,我们要查询这一天的周时数据,锚定一个点比如出管辖区的时间,那么根据查询到今天所有这个时间范围内出去的车信息,然后去数据表里找这个机车进来的数据且时最新的一条就行了。
实现思路
分两次查询的第一次查询出来所有的当天出管辖区的机车信息,第二个查询是根据第一个查询小小的改动,把时间范围去掉就好,然后根据机车信息进行组取时间每个机车时间最新的数据就好。直接使用group by,但是这个并不能取出其它的信息所以就pass掉了。GPTl了一下给的方案是使用partition这个功能。
实施
就不看项目数据了就看一下我写的小demo的结果吧。我有一个student表,这个表里有10个班的学生,每个班的学生有20个,我现在要取出每个班的学生id最大的这个记录,就可以使用这个partition了。

|
1 |
select * from (SELECT *, ROW_NUMBER() over (partition by classes_id order by id desc) as rn FROM `student`) a where rn=1 |

解释一下这个啊。
这条 SQL 语句使用了窗口函数 ROW_NUMBER() 来为每个 classes_id 组中的行编号,并在外部查询中只选择每个 classes_id 组中的最新一行(根据 id 倒序排序)。以下是对这条 SQL 语句的详细解释:
SQL 语句结构
|
1 2 3 4 5 6 7 |
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY classes_id ORDER BY id DESC) AS rn FROM `student` ) a WHERE rn = 1; |
内部查询(子查询)
|
1 2 3 |
SELECT *, ROW_NUMBER() OVER (PARTITION BY classes_id ORDER BY id DESC) AS rn FROM `student` |
SELECT *:
选择 student 表中的所有列。
ROW_NUMBER() OVER (PARTITION BY classes_id ORDER BY id DESC) AS rn:
- ROW_NUMBER() 是一个窗口函数,它为结果集中的每一行分配唯一的行号。
- OVER 子句定义了窗口的分区和排序规则: PARTITION BY classes_id:将结果集按 classes_id 列进行分组。对于每个 classes_id,将重新开始编号。
- ORDER BY id DESC:在每个 classes_id 分区中,按照 id 列的降序排序。
- AS rn:将生成的行号列命名为 rn。
这部分查询为每个 classes_id 组中的行编号,编号从1开始,按照 id 倒序排列。因此,rn 为1的行是每个 classes_id 组中 id 最大的行。
外部查询
|
1 2 3 4 5 6 7 |
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY classes_id ORDER BY id DESC) AS rn FROM `student` ) a WHERE rn = 1; |
FROM (...) a:
将内部查询的结果作为一个临时表 a。
WHERE rn = 1:
筛选出临时表 a 中 rn 等于 1 的行,即每个 classes_id 组中 id 最大的行。 结果
整个查询的作用是:
- 对 student 表进行分组(按 classes_id)。
- 在每个 classes_id 组中,按 id 倒序排列,并为每行分配一个行号 rn。
- 选择每个 classes_id 组中 rn 等于 1 的行(即每个 classes_id 组中 id 最大的行)。
partition的升级使用
partition不仅仅可以在日常查询中使用,还可以在表的数据结构上进行优化,比如在建表的时候创建分区或者后期添加分区,这个分区操作是在物理上的操作,可以看我下面这张表的结构,有一部分注释说明就是分区的设置,
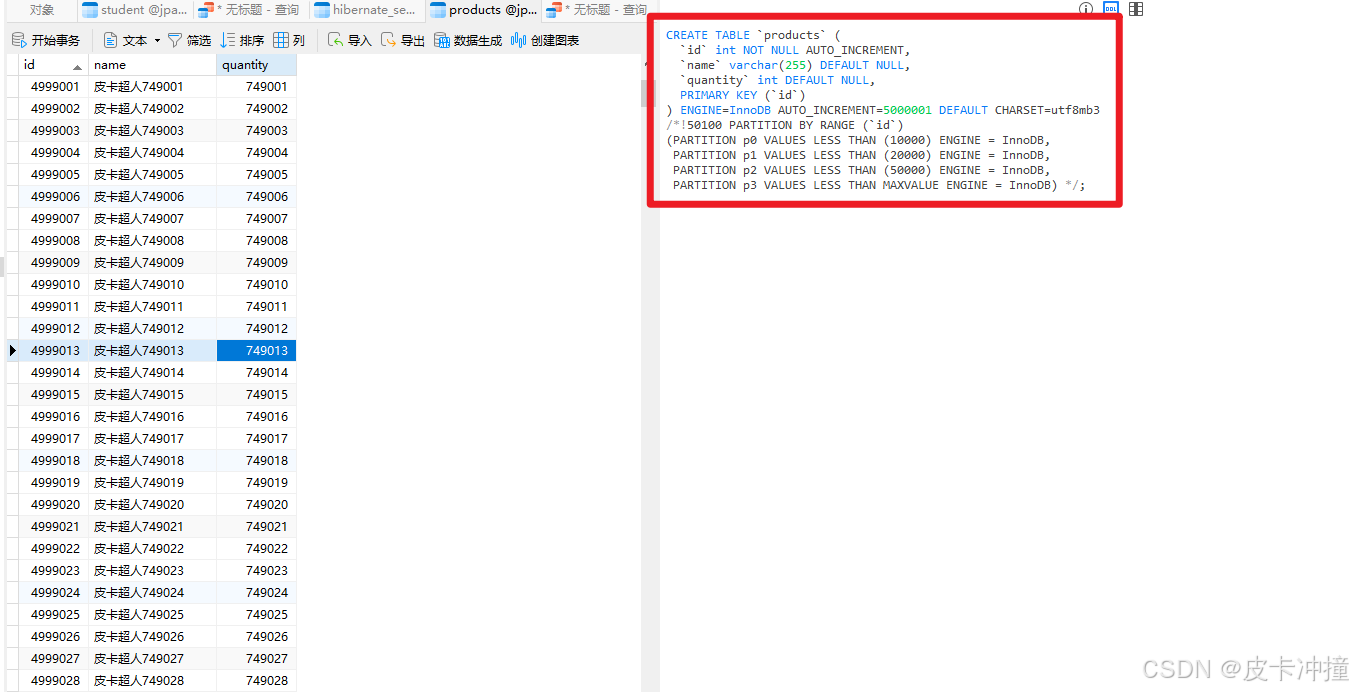
对表进行分区可以提升查询性能和数据管理的效率。由于 ENGINE=MyISAM 不支持分区,我们需要将表的存储引擎更改为 InnoDB,因为 InnoDB 支持分区。
假设我们要根据 id 列进行范围分区,将数据划分为四个分区:
- p0:包含 id 小于 10000的数据。
- p1:包含 id 小于 20000的数据。
- p2:包含 id 小于 50000的数据。
- p3:包含其余的数据。
|
1 2 3 4 5 6 |
PARTITION BY RANGE (id) ( PARTITION p0 VALUES LESS THAN (10000), PARTITION p1 VALUES LESS THAN (20000), PARTITION p2 VALUES LESS THAN (50000), PARTITION p3 VALUES LESS THAN MAXVALUE ); |
解释
- PARTITION BY RANGE (id): 根据 id 列进行范围分区。
- PARTITION p0 VALUES LESS THAN (10000): 第一个分区,包含 id 小于 10000的数据。
- PARTITION p1 VALUES LESS THAN (20000): 第二个分区,包含 id 小于 20000的数据。
- PARTITION p2 VALUES LESS THAN (50000): 第三个分区,包含 id 小于 50000的数据。
- PARTITION p3 VALUES LESS THAN MAXVALUE: 第四个分区,包含 id 大于等于 50000的数据。
这样,表 products 就被划分为四个分区,每个分区包含一定范围的 id 值的数据。
验证一下看看分区
上面说了创建分区了,但是怎么才能确定我们的查询sql使用到了分区呢?使用explain来查看执行的sql有没有在分区的范围呢,
下面是使用了explain查看执行的sql有没有用到分区,partition的值为p0对应了上面设置的分区。

分区的一些操作
创建分区后,数据库管理系统会自动处理分区的数据存储和检索,用户在日常操作中并不需要特殊处理分区。不过,你可以通过一些特定的查询和操作来利用分区的优势。以下是一些常见的用法示例:
1. 普通查询
普通的查询不需要特别处理分区,数据库管理系统会自动根据分区优化查询:
|
1 |
SELECT * FROM student WHERE id < 50; |
2. 分区表上的查询优化
当你的查询条件包含分区键时,数据库会自动选择相关的分区进行查询,从而提高查询性能。例如:
|
1 |
SELECT * FROM student WHERE id BETWEEN 50 AND 100; |
3. 插入数据
插入数据时,数据库会根据分区键自动将数据插入到相应的分区:
|
1 |
INSERT INTO student (name, classes_id) VALUES ('Alice', 1); |
4. 删除分区中的数据
可以通过分区键删除特定分区中的数据:
|
1 |
DELETE FROM student WHERE id < 50; |
5. 分区维护操作
你可以进行一些特定的分区维护操作,例如合并分区、拆分分区、删除分区等:
添加新的分区
|
1 2 3 |
ALTER TABLE student ADD PARTITION ( PARTITION p4 VALUES LESS THAN (200) ); |
删除分区
|
1 |
ALTER TABLE student DROP PARTITION p0; |
重组分区
可以将多个分区合并为一个分区:
|
1 2 3 |
ALTER TABLE student REORGANIZE PARTITION p1, p2 INTO ( PARTITION p1_2 VALUES LESS THAN (150) ); |
6. 检查分区信息
你可以使用 SHOW 语句查看表的分区信息:
|
1 |
SHOW CREATE TABLE student; |
总结
综合示例展示了如何创建分区表、插入数据以及进行查询和维护操作:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- 创建分区表 CREATE TABLE `student` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `classes_id` int DEFAULT NULL, PRIMARY KEY (`id`), KEY `FK4l5dnicegnvpmu0pv6vdvrmb6` (`classes_id`) ) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb3 PARTITION BY RANGE (id) ( PARTITION p0 VALUES LESS THAN (50), PARTITION p1 VALUES LESS THAN (100), PARTITION p2 VALUES LESS THAN (150), PARTITION p3 VALUES LESS THAN MAXVALUE ); -- 插入数据 INSERT INTO student (name, classes_id) VALUES ('Alice', 1); INSERT INTO student (name, classes_id) VALUES ('Bob', 2); -- 查询数据 SELECT * FROM student WHERE id < 50; -- 删除分区中的数据 DELETE FROM student WHERE id < 50; -- 添加新分区 ALTER TABLE student ADD PARTITION ( PARTITION p4 VALUES LESS THAN (200) ); -- 删除分区 ALTER TABLE student DROP PARTITION p0; -- 检查分区信息 SHOW CREATE TABLE student; |
目前先整理这么多,以后有深入学习使用了再继续!!!