PDF文件现已成为文档存储和分发的首选格式。然而,PDF文件的静态特性有时会限制其交互性。超链接是提高PDF文件互动性和用户体验的关键元素。Python作为一种强大的编程语言,拥有多种库和工具来处理PDF文件,包括添加、删除超链接。本文将详细介绍如何使用第三方库Spire.PDF for Python来进行这些操作。
所需Python库 - Spire.PDF for Python。可以通过下面的pip 命令直接安装:
pip install Spire.Pdf
Python 在PDF文档中添加超链接
Spire.PDF for Python支持在PDF中添加不同类型的超链接:
- 简单文字链接:直接使用 PdfPageBase.Canvas.DrawString() 方法将其绘制到页面上。
- 超文本链接、邮箱链接:通过 PdfTextWebLink.DrawTextWebLink() 方法绘制到页面上。
- 文档链接:通过 PdfPageBase.AnnotationsWidget.Add(PdfFileLinkAnnotation) 方法添加。
Python 代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
from spire.pdf.common import * from spire.pdf import *
# 创建PDF文档 pdf = PdfDocument()
# 添加页面 page = pdf.Pages.Add()
# 设置初始X和Y坐标 y = 30.0 x = 10.0
# 创建PDF字体 font = PdfTrueTypeFont("宋体", 14.0, PdfFontStyle.Regular, True) font1 = PdfTrueTypeFont("宋体", 14.0, PdfFontStyle.Underline, True)
# 添加简单文本链接 label = "简单链接: " format = PdfStringFormat() format.MeasureTrailingSpaces = True page.Canvas.DrawString(label, font, PdfBrushes.get_Black(), 0.0, y, format) x = font.MeasureString(label, format).Width url = "https://www.e-iceblue.cn" page.Canvas.DrawString(url, font1, PdfBrushes.get_Blue(), x, y) y = y + 28
# 添加超文本链接 label = "超文本链接:" page.Canvas.DrawString(label, font, PdfBrushes.get_Black(), 0.0, y, format) x = font.MeasureString(label, format).Width webLink = PdfTextWebLink() webLink.Text = "主页" webLink.Url = url webLink.Font = font1 webLink.Brush = PdfBrushes.get_Blue() webLink.DrawTextWebLink(page.Canvas, PointF(x, y)) y = y + 28
# 添加邮件链接 label = "邮件链接: " page.Canvas.DrawString(label, font, PdfBrushes.get_Black(), 0.0, y, format) x = font.MeasureString(label, format).Width link = PdfTextWebLink() link.Text = "联系我们" link.Url = "mailto:support @e-iceblue.com" link.Font = font1 link.Brush = PdfBrushes.get_Blue() link.DrawTextWebLink(page.Canvas, PointF(x, y)) y = y + 28
# 添加文档链接 label = "文档链接: " page.Canvas.DrawString(label, font, PdfBrushes.get_Black(), 0.0, y, format) x = font.MeasureString(label, format).Width text = "点击打开文件" location = PointF(x, y) size = font1.MeasureString(text) linkBounds = RectangleF(location, size) fileLink = PdfFileLinkAnnotation(linkBounds, "C:\\Users\\Administrator\\Desktop\\排名.xlsx") fileLink.Border = PdfAnnotationBorder(0.0) page.AnnotationsWidget.Add(fileLink) page.Canvas.DrawString(text, font1, PdfBrushes.get_Blue(), x, y)
# 保存PDF文档 pdf.SaveToFile("PDF超链接.pdf") pdf.Close() |
生成文件:
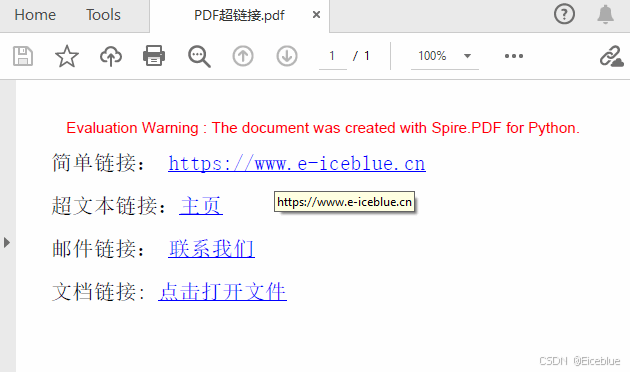
Python 删除PDF 文档中的超链接
如果要将PDF文档中已有的超链接一次性全部删除,可以参考以下步骤:
- 通过LoadFromFile()方法加载 PDF 文档。
- 循环遍历文档中的页面,并通过 PdfPageBase.AnnotationsWidget 属性获取每个页面上的注释。
- 循环遍历所有注释,检查每个注释是否为超链接。
- 如果是,则使用 PdfAnnotationCollection.Remove() 方法将其删除。
- 使用 PdfDocument.SaveToFile() 方法保存文档。
Python 代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from spire.pdf import * from spire.pdf.common import *
# 加载PDF文档 pdf = PdfDocument() pdf.LoadFromFile("PDF超链接.pdf")
# 遍历文档中的所有页面 for j in range(pdf.Pages.Count): # 获取每一页 page = pdf.Pages.get_Item(j) # 获取每一页上的注释 annotations = page.AnnotationsWidget # 检查注释是否为空 if annotations.Count > 0: # 遍历所有注释 i = annotations.Count - 1 while i >=0: # 获取注释 annotation = annotations.get_Item(i) # 检查注释是否为超链接 if isinstance(annotation, PdfTextWebLinkAnnotationWidget): # 删除超链接 annotations.Remove(annotation) i -= 1
# 保存PDF文档 pdf.SaveToFile("删除PDF超链接.pdf") pdf.Close() |
如果仅需删除PDF某一页中的指定超链接,可以参考 以下代码:
|
1 2 3 |
# 删除第一页中的第一个超链接 page = pdf.Pages.get_Item(0) page.AnnotationsWidget.RemoveAt(0) |


