DISTINCT 六大注意事项
1. 作用范围:所有 SELECT 字段
|
1 |
SELECT DISTINCT a, b FROM table; -- 对(a,b)组合整体去重 |
误以为只作用于第一个字段:
|
1 2 |
-- 错误理解:以为只对name去重 SELECT DISTINCT name, class FROM students; |
实际效果:对 (name, class) 组合去重(如 ('张三','一班') 和 ('张三','二班') 算不同记录)
2. NULL 值的特殊处理
|
1 2 3 |
INSERT INTO students (name, class, score) VALUES (NULL, '三班', 90);
SELECT DISTINCT name FROM students; |
结果:
+--------+
| name |
+--------+
| 张三 |
| 李四 |
| 王五 |
| NULL | -- NULL被视为独立值保留
+--------+
3. 性能陷阱(大数据量)
|
1 2 |
-- 当表有百万行时慎用 SELECT DISTINCT text_column FROM huge_table; |
优化方案:
|
1 2 3 4 5 6 7 |
-- 先通过WHERE缩小范围再去重 SELECT DISTINCT text_column FROM huge_table WHERE create_time > '2023-01-01';
-- 或添加索引(对text类型有限制) ALTER TABLE huge_table ADD INDEX idx_text(text_column(20)); -- 前缀索引 |
4. 与 ORDER BY 的优先级
|
1 2 3 |
SELECT DISTINCT class FROM students ORDER BY score DESC; -- 错误!score不在SELECT中 |
正确写法:
|
1 2 3 4 5 6 7 8 9 10 |
-- 方案1:排序字段必须在SELECT中 SELECT DISTINCT class, MAX(score) AS max_score FROM students GROUP BY class ORDER BY max_score DESC;
-- 方案2:子查询 SELECT DISTINCT class FROM ( SELECT class, score FROM students ORDER BY score DESC ) AS tmp; |
5. 聚合函数中的 DISTINCT
|
1 2 3 4 5 |
-- 统计不重复的班级数量 SELECT COUNT(DISTINCT class) FROM students;
-- 错误用法(语法无效): SELECT DISTINCT COUNT(class) FROM students; |
6. 不可用于部分字段计算
|
1 2 |
-- 尝试计算不同班级的平均分(错误!) SELECT DISTINCT class, AVG(score) FROM students; |
正确做法:必须配合 GROUP BY
|
1 2 3 |
SELECT class, AVG(score) FROM students GROUP BY class; -- 这才是标准解法 |
高级注意点
7. 与 LIMIT 的配合问题
|
1 |
SELECT DISTINCT class FROM students LIMIT 2; |
结果不确定性:
返回的 2 条记录是随机的(除非指定 ORDER BY),不同执行可能结果不同。
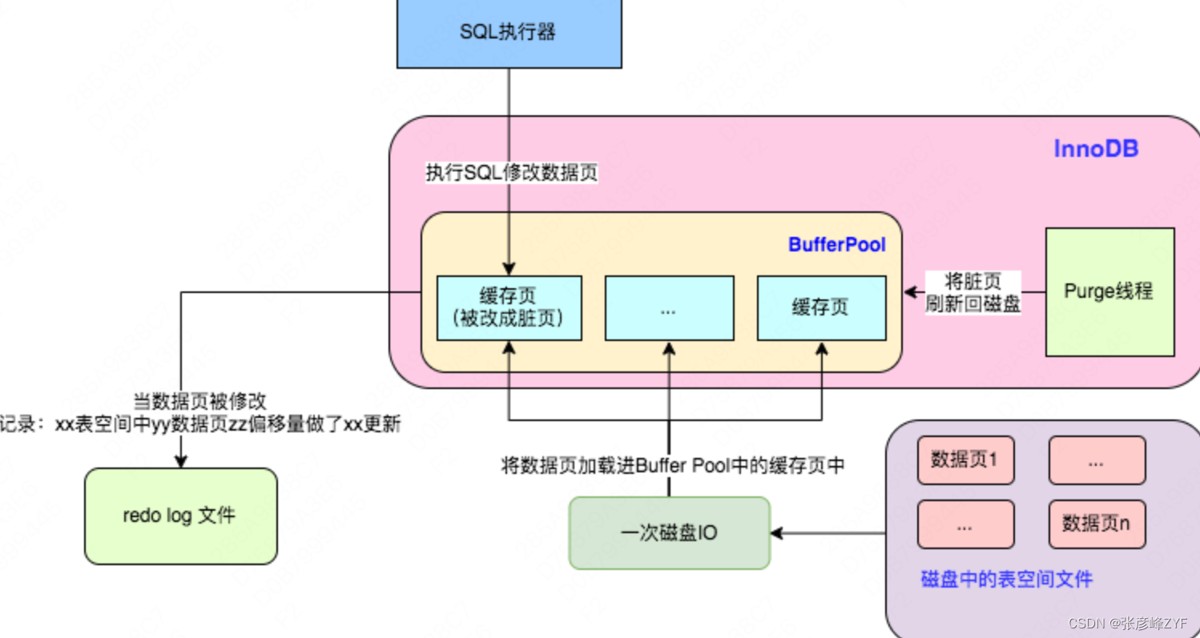
8. 临时表空间占用
DISTINCT 操作会在内存/磁盘创建临时表存储唯一值
当去重字段总数据量超过 tmp_table_size 时,性能急剧下降
查看阈值:
|
1 |
SHOW VARIABLES LIKE 'tmp_table_size'; -- 默认16MB |
对比 GROUP BY 去重
| 特性 | DISTINCT | GROUP BY |
|---|---|---|
| 是否可搭配聚合函数 | ? | ? (如SUM/AVG) |
| 结果排序 | 无序 | 可按分组键排序 |
| 执行效率 | 简单场景更快 | 复杂聚合时更优 |
| 索引利用 | 可使用索引 | 必须用分组字段索引 |
最佳实践总结
小数据量:直接 DISTINCT 简洁高效
需要聚合计算:用 GROUP BY 替代
精确去重计数:优先 COUNT(DISTINCT column)
排序需求:必须显式写 ORDER BY
超大数据:先过滤再去重 + 合理索引
实战检验
订单表 orders 结构:
|
1 2 3 4 5 6 7 |
CREATE TABLE orders ( id INT PRIMARY KEY, product_id INT, user_id INT, amount DECIMAL(10,2), coupon_code VARCHAR(20) -- 允许为NULL ); |
问题:
如何高效获取使用过不同优惠券的用户ID列表(含NULL)?
写出你的解决方案:
SELECT _______________________________
FROM orders;
答案(折叠):
|
1 2 3 4 5 6 7 8 |
-- 方案1:基础写法 SELECT DISTINCT user_id, coupon_code FROM orders WHERE coupon_code IS NOT NULL; -- 若需包含NULL则去掉WHERE
???????-- 方案2:大数据量优化(添加联合索引) ALTER TABLE orders ADD INDEX idx_user_coupon(user_id, coupon_code); SELECT DISTINCT user_id, coupon_code FROM orders; |