安装scrapy框架并测试
这是个系列文章,主要是能让大家快速的的做出一个小项目,主要是我现在在做计算机设计大赛,想把做过的东西记录下来,后续我会将整个计设的项目的制作过程写出来分享给大家。其中包括Django、mysql数据库、前端等。
这些文章主要是记录具体操作过程,具体的知识内容还请去刷视频,这里不做过多解释。
安装scrapy框架
在终端里先后运行这个语句即可安装
|
1 2 |
pip install wheel pip install scrapy |
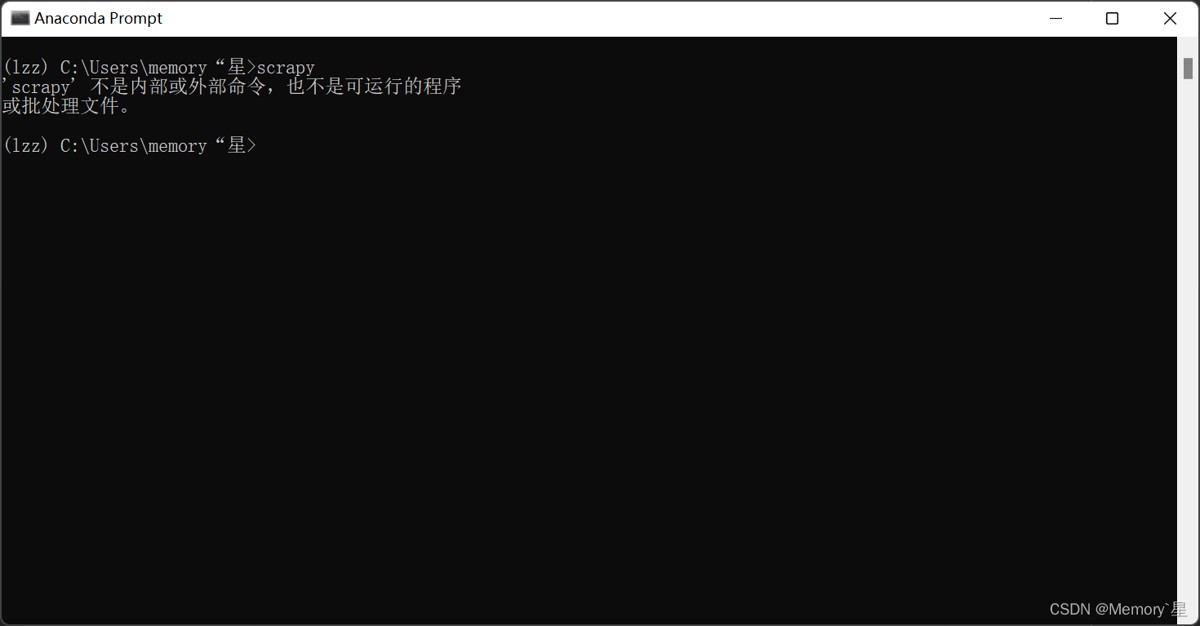
在终端里输入scrapy即可验证是否安装成功,以下是没有安装前的情况。
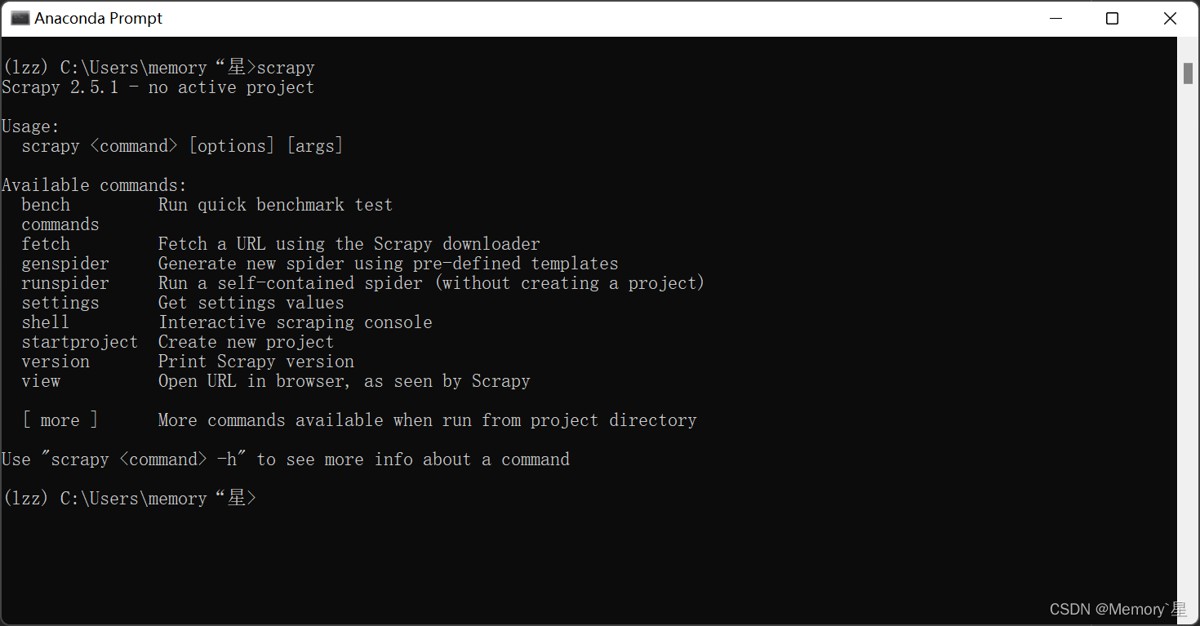
以下是安装过后验证的情况
这样就说明安装成功了。
我们需要在pycharm终端里创建一个工程
代码如下:
|
1 |
scrapy startproject comment(comment为你的工程名称) |
创建成功如下
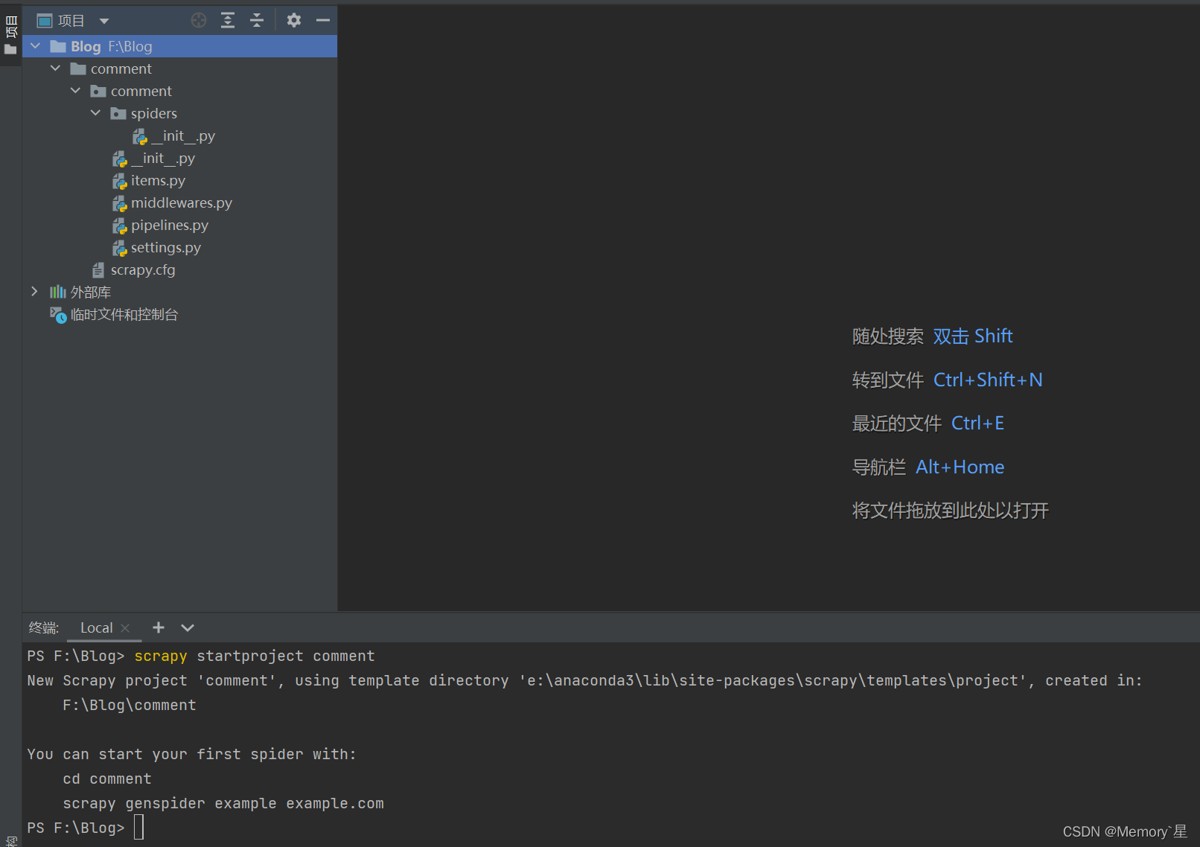
(这里注意,有些同学创建不成功报错的,需要在pycharm终端里再次执行pip install scrapy)
紧接着执行下面提示的两段代码来创建我们的爬虫主文件
|
1 |
cd comment |
注意这里的example.com我们需要换成自己的起始url (这里随便设一个就好,这个不影响我们的任务)
|
1 |
scrapy genspider news(这里的news为爬虫文件名称)www.xxx.com |
然后配置成如下的形式
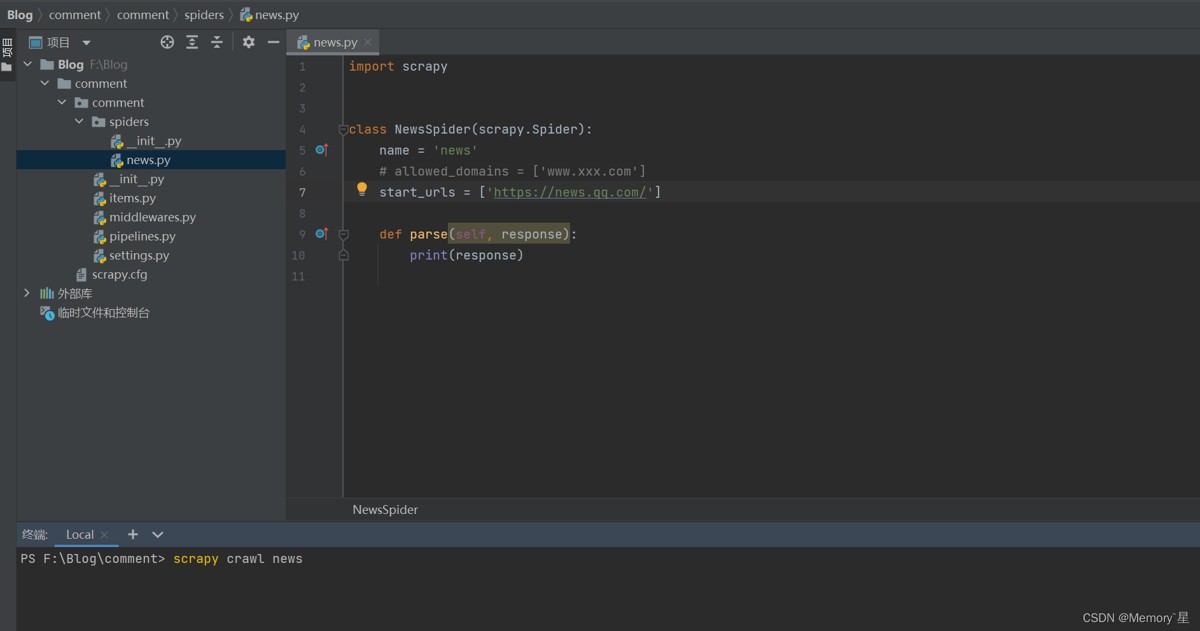
注意这里的allowed_domains可以注释掉,对我们的任务没有太大的影响。start_urls里的url换成我们需要请求的网址。(这里我就用腾讯新闻的主页来测试了)
在此之前我们需要在settings.py文件里完成如下配置:
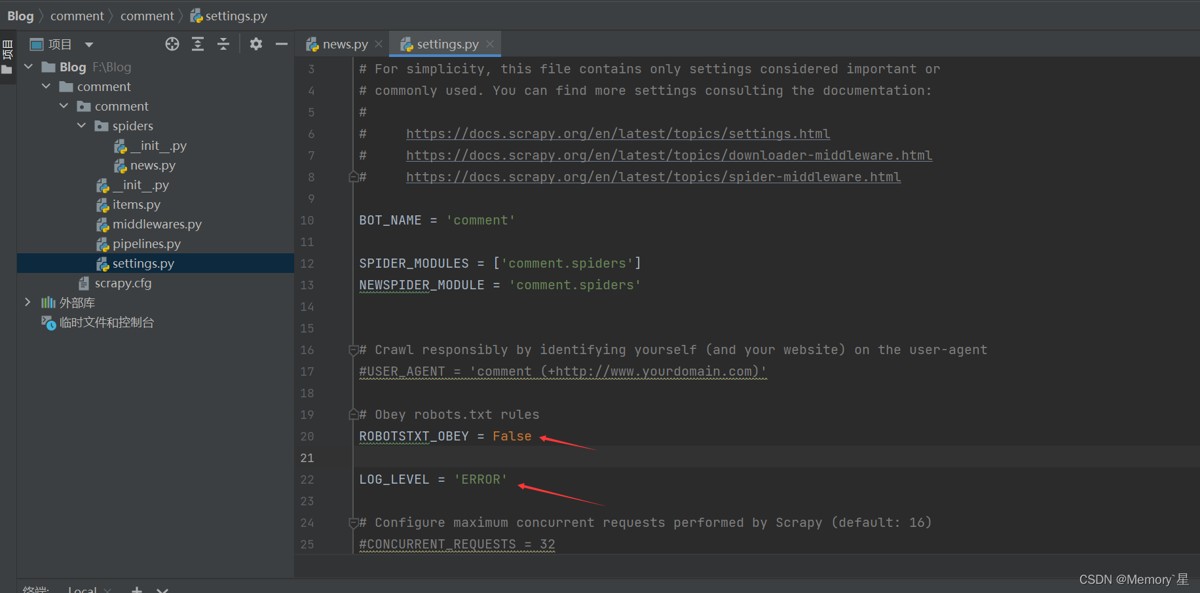
然后在终端输入以下代码来运行爬虫文件:
|
1 |
scrapy crawl news |
运行成功!
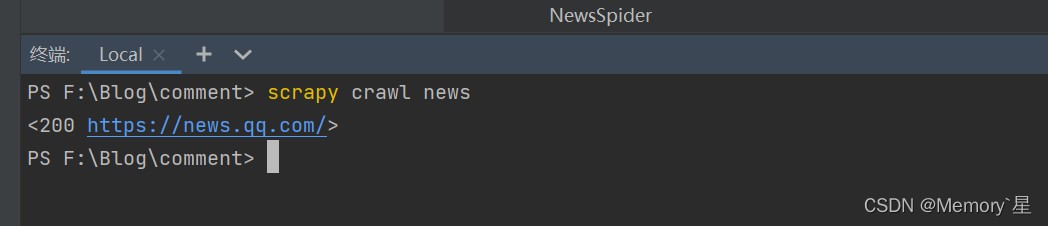
这样测试就完成了,可以进行后续的任务了。
原文链接:
相关文章