下面的这篇文章主要教大家如何搭建一个基于Transformer的简单预测模型,并将其用于股票价格预测当中。原代码在文末进行获取。
1、Transformer模型
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。这篇文章的目的主要是将带大家通过Pytorch框架搭建一个基于Transformer的简单股票价格预测模型。
Transformer的基本架构:
具体地,我们用到了上证指数的收盘价数据为例,进行预测t+1时刻的收盘价。需要注意的是,本文只是通过这样一个简单的基本模型,带大家梳理一下数据预处理,模型构建以及模型评估的流程。模型还有很多可以改进的地方,例如选择更有意义的特征,如何进行有效的多步预测等。
2、环境准备
本地环境:
Python 3.7
IDE:Pycharm
库版本:
numpy 1.18.1
pandas 1.0.3
sklearn 0.22.2
matplotlib 3.2.1
torch 1.10.1
3、代码实现
3.1. 导入库以及定义超参
首先,需要导入用到库,以及模型的一些超参数的设置。其中,input_window和output_window分别用于设置输入数据的长度以及输出数据的长度。当然,这些参数大家也可以根据实际应用场景进行修改。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import torch
import torch.nn as nn
import numpy as np
import time
import math
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
torch.manual_seed(0)
np.random.seed(0)
input_window = 20
output_window = 1
batch_size = 64
device = torch.
device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
|
3.2. 模型构建
Transformer中很重要的一个组件是提出了一种新的位置编码的方式。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(PositionalEncoding)就是用来解决这种问题的方法。它的原理是将生成的不同频率的正弦和余弦数据作为位置编码添加到输入序列中,从而使得模型可以捕捉输入变量的相对位置关系。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
|
之后,搭建Transformer的基本结构,在Pytorch中有已经实现的封装好的Transformer组件,可以很方便地进行调用和修改。其中需要注意的是,文中并没有采用原论文中的Encoder-Decoder的架构,而是将Decoder用了一个全连接层进行代替,用于输出预测值。另外,其中的create_mask将输入进行mask,从而避免引入未来信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
class TransAm(nn.Module):
def __init__(self, feature_size=250, num_layers=1, dropout=0.1):
super(TransAm, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(feature_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=10, dropout=dropout) self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(feature_size, 1)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
|
3.3. 数据预处理
接下来需要对数据进行预处理,首先定义一个窗口划分的函数。它的作用是将输入按照延迟output_windw的方式来划分数据以及其标签,文中是进行单步预测,所以假设输入是1到20,则其标签就是2到21,以适应Transformer的seq2seq的形式的输出。
|
1
2
3
4
5
6
7
8
|
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L - tw):
train_seq = input_data[i:i + tw]
train_label = input_data[i + output_window:i + tw + output_window]
inout_seq.append((train_seq, train_label))
return torch.FloatTensor(inout_seq)
|
之后划分训练集和测试集,其中前70%条数据用于模型训练,后面的数据用于模型测试。具体地,我们用到了前input_window个收盘价来预测下一时刻的收盘价数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def get_data():
series = pd.read_csv('./000001_Daily.csv', usecols=['Close'])
# series = pd.read_csv('./daily-min-temperatures.csv', usecols=['Temp'])
scaler = MinMaxScaler(feature_range=(-1, 1))
series = scaler.fit_transform(series.values.reshape(-1, 1)).reshape(-1)
train_samples = int(0.7 * len(series)) train_data = series[:train_samples]
test_data = series[train_samples:]
train_sequence = create_inout_sequences(train_data, input_window)
train_sequence = train_sequence[:-output_window]
test_data = create_inout_sequences(test_data, input_window)
test_data = test_data[:-output_window]
return train_sequence.to(device), test_data.to(device)
|
接下来实现一个databatch generator,便于从数据中按照batch的形式进行读取数据。
|
1
2
3
4
5
6
|
def get_batch(source, i, batch_size):
seq_len = min(batch_size, len(source) - 1 - i)
data = source[i:i + seq_len]
input = torch.stack(torch.stack([item[0] for item in data]).chunk(input_window, 1))
target = torch.stack(torch.stack([item[1] for item in data]).chunk(input_window, 1))
return input, target
|
3.4. 模型训练以及评估
下面是模型训练的代码。具体地,就是通过遍历训练集,通过既定的loss,对参数进行反向传播,其中用到了梯度裁剪的技巧用于防止梯度爆炸,然后每间隔几个间隔打印一下loss。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def train(train_data):
model.train()
for batch_index, i in enumerate(range(0, len(train_data) - 1, batch_size)):
start_time = time.time()
total_loss = 0
data, targets = get_batch(train_data, i, batch_size)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.7)
optimizer.step()
total_loss += loss.item()
log_interval = int(len(train_data) / batch_size / 5)
if batch_index % log_interval == 0 and batch_index > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | lr {:02.6f} | {:5.2f} ms | loss {:5.5f} | ppl {:8.2f}'
.format(epoch, batch_index, len(train_data) // batch_size, scheduler.get_lr()[0], elapsed * 1000 / log_interval, cur_loss, math.exp(cur_loss)))
|
接下来是对模型进行评估的代码。
|
1
2
3
4
5
6
7
8
9
10
|
def evaluate(eval_model, data_source):
eval_model.eval()
total_loss = 0
eval_batch_size = 1000
with torch.no_grad():
for i in range(0, len(data_source) - 1, eval_batch_size):
data, targets = get_batch(data_source, i, eval_batch_size)
output = eval_model(data)
total_loss += len(data[0]) * criterion(output, targets).cpu().item()
return total_loss / len(data_source)
|
最后,是模型运行过程的可视化:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def plot_and_loss(eval_model, data_source, epoch):
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
with torch.no_grad():
for i in range(0, len(data_source) - 1):
data, target = get_batch(data_source, i, 1)
output = eval_model(data)
total_loss += criterion(output, target).item()
test_result = torch.cat((test_result, output[-1].view(-1).cpu()), 0)
truth = torch.cat((truth, target[-1].view(-1).cpu()), 0)
plt.plot(test_result, color="red") plt.plot(truth, color="blue")
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
plt.savefig('graph/transformer-epoch%d.png' % epoch)
plt.close()
return total_loss / i
|
3.5. 模型运行
最后,对模型进行运行。其中用到了mse作为loss,adam作为优化器,以及设定学习率的调度器,最后运行200个epoch,每隔10个epoch在测试集上评估一下模型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
train_data, val_data = get_data()
model = TransAm().to(device)
criterion = nn.MSELoss()
lr = 0.005
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95)
epochs = 200
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(train_data)
if (epoch % 10 is 0):
val_loss = plot_and_loss(model, val_data, epoch)
else:
val_loss = evaluate(model, val_data)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.5f} | valid ppl {:8.2f}'.format(epoch, ( time.time() - epoch_start_time), val_loss, math.exp(val_loss)))
print('-' * 89) scheduler.step()
|
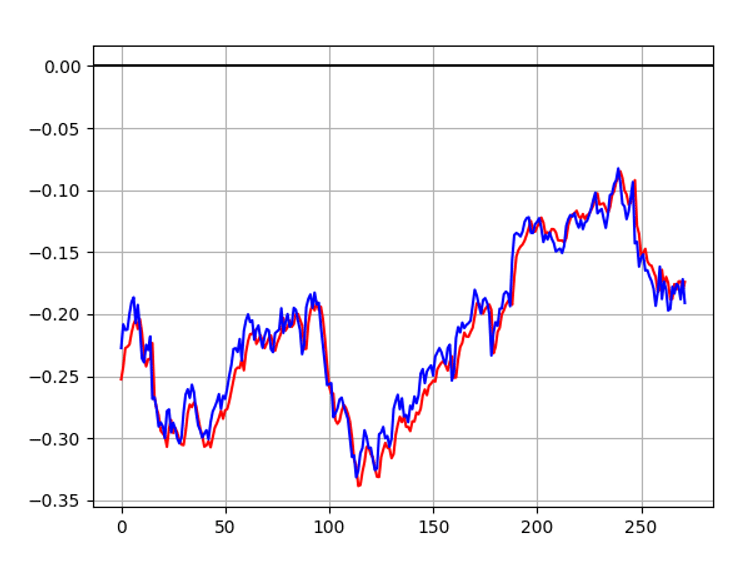
下面是运行的结果,可以看到loss明显降低了:
cuda| epoch 1 | 2/ 10 batches | lr 0.005000 | 7.83 ms | loss 39.99368 | ppl 233902099994043520.00| epoch 1 |
4/ 10 batches | lr 0.005000 | 7.81 ms | loss 7.20889 | ppl 1351.39| epoch 1 | 6/ 10 batches | lr 0.005000 | 11.10 ms | loss 1.68758 | ppl 5.41| epoch 1 |
8/ 10 batches | lr 0.005000 | 9.35 ms | loss 0.00833 | ppl 1.01| epoch 1 | 10/ 10 batches | lr 0.005000 | 7.81 ms | loss 1.18041 | ppl 3.26-----------------------------------------------------------------------------------------| end of epoch 1 | time: 1.96s | valid loss 2.58557 | valid ppl 13.27
...
| end of epoch 198 | time: 0.30s | valid loss 0.00032 | valid ppl 1.00-----------------------------------------------------------------------------------------| epoch 199 |
2/ 10 batches | lr 0.000000 | 15.62 ms | loss 0.00057 | ppl 1.00| epoch 199 | 4/ 10 batches | lr 0.000000 | 15.62 ms | loss 0.00184 | ppl 1.00| epoch 199 |
6/ 10 batches | lr 0.000000 | 15.62 ms | loss 0.00212 | ppl 1.00| epoch 199 | 8/ 10 batches | lr 0.000000 | 7.81 ms | loss 0.00073 | ppl 1.00| epoch 199 | 10/ 10 batches | lr 0.000000 |
7.81 ms | loss 0.00057 | ppl 1.00-----------------------------------------------------------------------------------------| end of epoch 199 | time: 0.30s | valid loss 0.00032 | valid ppl 1.00-----------------------------------------------------------------------------------------| epoch 200 | 2/ 10 batches | lr 0.000000 | 15.62 ms | loss 0.00053 | ppl 1.00| epoch 200 |
4/ 10 batches | lr 0.000000 | 7.81 ms | loss 0.00177 | ppl
1.00| epoch 200 | 6/ 10 batches | lr 0.000000 | 7.81 ms | loss 0.00224 | ppl 1.00| epoch 200 | 8/ 10 batches | lr 0.000000 | 15.62 ms | loss 0.00069 | ppl 1.00| epoch 200 | 10/ 10 batches | lr 0.000000 | 7.81 ms | loss 0.00049 | ppl 1.00-----------------------------------------------------------------------------------------| end of epoch 200 | time: 0.62s | valid loss 0.00032 | valid ppl
1.00-----------------------------------------------------------------------------------------
最后是模型的拟合效果,从实验结果中可以看出我们搭建的简单的Transformer模型可以实现相对不错的数据拟合效果。
4、总结
在这篇文章中,我们介绍了如何基于Pytorch框架搭建一个基于Transformer的股票预测模型,并通过真实股票数据对模型进行了实验,可以看出Transformer模型对股价预测具有一定的效果。另外,文中只是做了一个简单的demo,其中仍然有很多可以改进的地方,如采用更多有意义的输入数据,优化其中的一些组件等。除此之外,目前基于Transformer的模型层出不穷,其中也有很多值得我们去学习,大家也可以采用更先进的Transformer模型进行试验
|














