
MySQL中DISTINCT去重的核心注意事项

DISTINCT 六大注意事项 1. 作用范围:所有 SELECT 字段 1 SELECT DISTINCT a, b FROM table; -- 对(a,b)组合整体去重 误以为只作用于第一个字段: 1 2 -- 错误理解:以为只对name去重 SELECT DISTINCT name, class FROM
DISTINCT 六大注意事项1. 作用范围:所有 SELECT 字段
误以为只作用于第一个字段:
实际效果:对 (name, class) 组合去重(如 ('张三','一班') 和 ('张三','二班') 算不同记录) 2. NULL 值的特殊处理
结果:
3. 性能陷阱(大数据量)
优化方案:
4. 与 ORDER BY 的优先级
正确写法:
5. 聚合函数中的 DISTINCT
6. 不可用于部分字段计算
正确做法:必须配合 GROUP BY
高级注意点7. 与 LIMIT 的配合问题
结果不确定性: 返回的 2 条记录是随机的(除非指定 ORDER BY),不同执行可能结果不同。 8. 临时表空间占用DISTINCT 操作会在内存/磁盘创建临时表存储唯一值 当去重字段总数据量超过 tmp_table_size 时,性能急剧下降 查看阈值:
对比 GROUP BY 去重
最佳实践总结小数据量:直接 DISTINCT 简洁高效 需要聚合计算:用 GROUP BY 替代 精确去重计数:优先 COUNT(DISTINCT column) 排序需求:必须显式写 ORDER BY 超大数据:先过滤再去重 + 合理索引 实战检验订单表 orders 结构:
问题: 如何高效获取使用过不同优惠券的用户ID列表(含NULL)? 写出你的解决方案:
答案(折叠):
|
您可能感兴趣的文章 :

-
从入门到精通MySQL数据库索引(实战案例)
一、索引是什么?能干嘛? 类比理解:索引就像书的目录。比如你想查《哈利波特》中 伏地魔 出现的页数,不用逐页翻书,直接看目录找 -
MySQL中DISTINCT去重的核心注意事项
DISTINCT 六大注意事项 1. 作用范围:所有 SELECT 字段 1 SELECT DISTINCT a, b FROM table; -- 对(a,b)组合整体去重 误以为只作用于第一个字段: 1 2 -- 错误 -
MySQL中日期相减的完整指南(最新推荐)
MySQL 中日期相减的完整指南 在 MySQL 中,日期相减有几种不同的方法,具体取决于你想要得到的结果类型(天数差、时间差等)。 1. 使用 -
MySQL中的LIMIT语句及基本用法
MySQL 中的 LIMIT 语句 LIMIT语句用于限制查询返回的行数,常用于分页查询或取部分数据,提高查询效率。 1. LIMIT 语法 1 2 3 4 5 SELECT 列名1, 列名 -
MySQL备份失败的问题:undo log清理耗时10小时的问题
在数据库运维领域,备份失败是令人头疼的问题。本文将结合实际案例,剖析 MySQL 8.0.18 环境下,因 undo log 清理耗时过长导致全备失败的故 -
MySQL启动报错:InnoDB表空间丢失问题及解决方法
MySQL启动报错:InnoDB表空间丢失问题及解决方法 在启动 MySQL时,遇到了如下错误: 1 2 3 2025-01-16T12:43:28.341240Z 0 [ERROR] InnoDB: Tablespace 5975 was -
MySQL查看表的最后一个ID的常见方法
在MySQL中,id字段通常被用作主键,尤其是自增主键(AUTO_INCREMENT)。自增主键的特性是每次插入新记录时,id值会自动递增。因此,最后一个 -
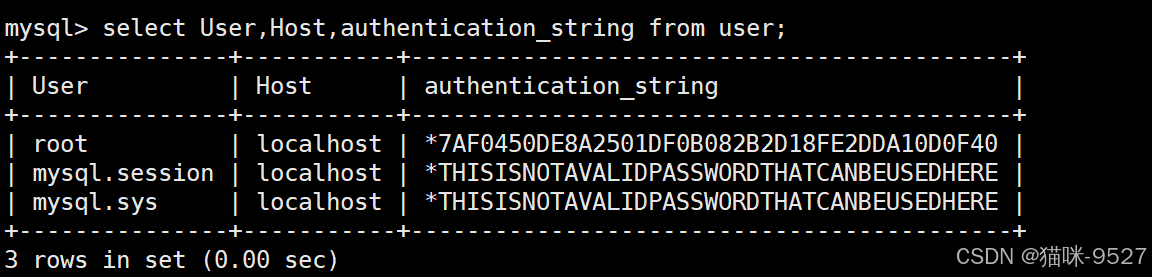
Mysql中的用户管理
13. 用户管理 为什么不能只用 root:出于安全考虑,不应该所有操作都由 root 执行。 MySQL 的用户信息存储位置:mysql.user表。 13.1 用户 ???? 1 -
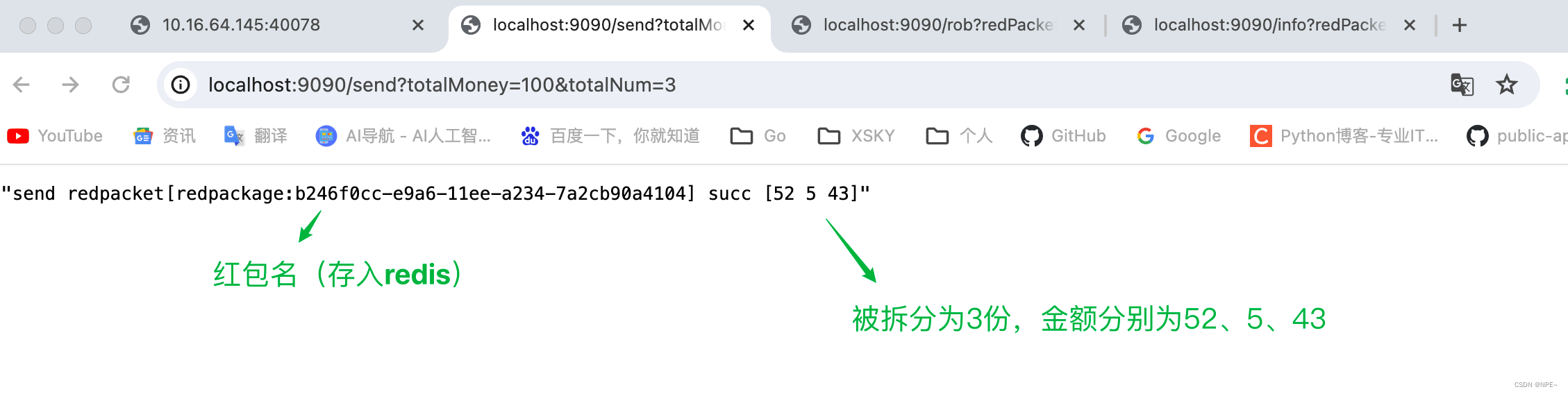
Redis迷你版微信抢红包
全部代码:https://github.com/ziyifast/ziyifast-code_instruction/tree/main/redis_demo/redpacket_demo 1 思路分析 抢红包是一个高并发操作,且我们需要保证其原 -
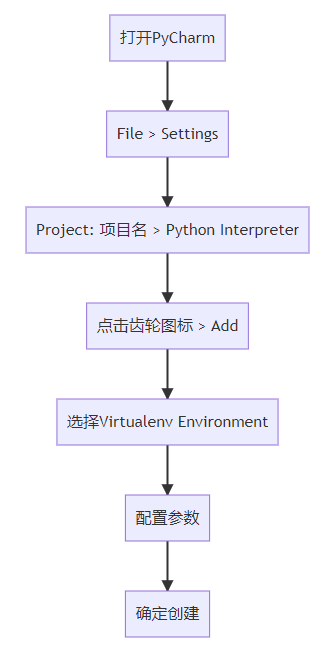
Python虚拟环境终极(含PyCharm的使用教程)
一、为什么需要虚拟环境? 场景 问题表现 虚拟环境解决方案 多项目依赖冲突 项目A需要Django 3.2,项目B需要Django 4.1 隔离不同项目的依赖版



-
zabbix监控mysql的实例方法
2021-06-02
-
MySQL时间类型的选择
2021-06-05
-
MySQL数据库基本SQL语句教程之高级操作
2022-06-27
-
MySQL文件权限存在的安全问题和解决方
2024-07-31
-
利用Mysql定时+存储过程创建临时表统
2024-02-19

