
PostgreSQL图(graph)的递归查询

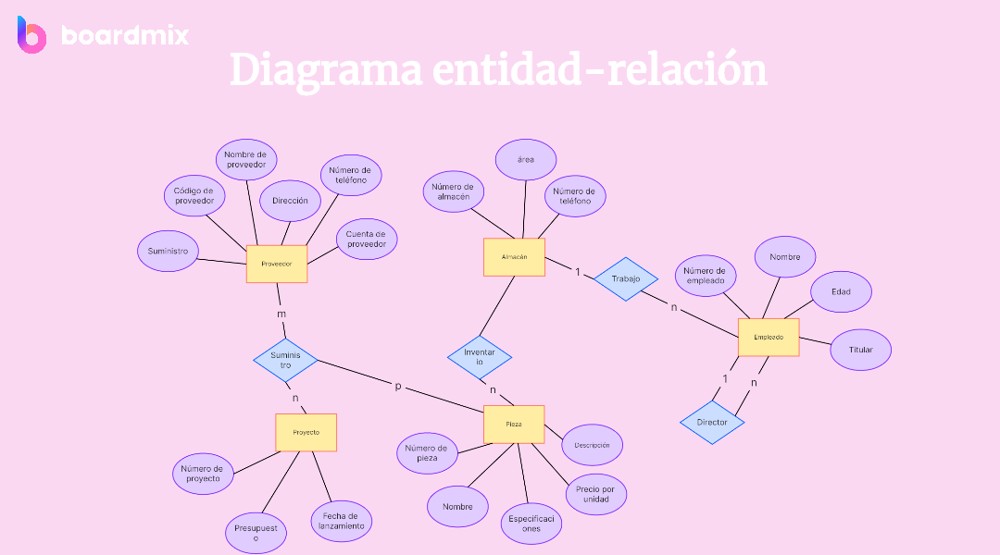
背景 在树形递归查询这篇文章,我记录了使用CTE语法查询树形结构的办法。在一个树形结构中,每一个节点最多有一个上级,可以有任意个数的下级。 在实际场景中,我们还会遇到对图(graph)的查询,图和树的最大区别是,图的节点可以有任意个数的上级和下级。如
|
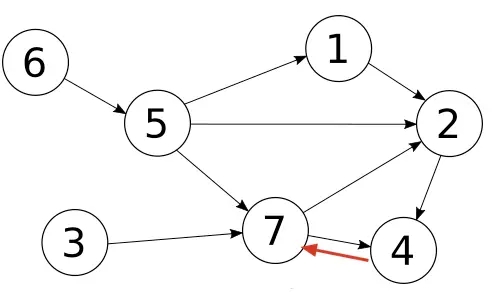
背景 在树形递归查询这篇文章,我记录了使用CTE语法查询树形结构的办法。在一个树形结构中,每一个节点最多有一个上级,可以有任意个数的下级。 在实际场景中,我们还会遇到对图(graph)的查询,图和树的最大区别是,图的节点可以有任意个数的上级和下级。如下图所示
因为图可能存在loop结构(上图红色箭头),所以在使用CTE递归的过程中,必须要破环(break loop),否则算法就会进入无限递归,永不结束。 存储和查询图结构,目前当红数据库是neo4j,但是当数据量只有十几万条的时候,PostgreSQL完全可以胜任。 构造样本数据
递归查询 指定节点的下级 常见的一个场景是,给定一个节点,查询这个节点的所有下级节点和路径。使用破环的算法关键如下
上面以节点7为开始,返回下级的所有节点和路径信息,如下。
指定节点的所有关联 在社交网络的场景中,我们根据一个特定的节点,查询所有的关系网。在本文的样本数据中,我们的需求就变成,同时查询指定节点的所有上级和下级。 为了方便后面的测试,我们封装一个函数
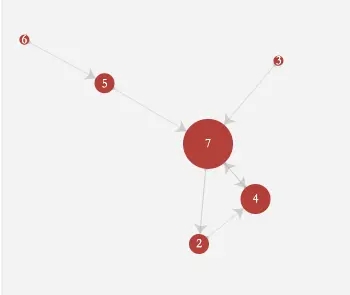
测试一下,查询节点7的所有3度关联节点信息,如下
图形显示结果 ECharts模板
在没有集成图形界面之前,使用ECharts的示例代码(地址),可以直观的查看关系图谱。对官方样表进行微调之后,代码如下
造显示用数据 构造 data 部分
构造 links 部分
图形显示 把构造的data和links替换到ECharts代码里面 查询节点7的所有2度关联节点信息,结果显示如下
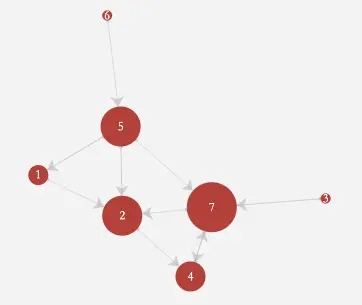
查询节点7的所有关联节点信息(不限层级数),结果显示如下
|
您可能感兴趣的文章 :

-
六大主流数据同步工具对比:DataX、Airbyte、Cana
当数据量变大、数据源复杂、实时需求提高,很多团队在选数据同步工具时犯难。本文对 DataX、Airbyte、Canal、Debezium、Fivetran 与 Apache SeaTun -
解读SQL生成工具
SQL 生成工具可用于测试Parser与其他数据库产品的兼容性,通过解析YACC语法文件中的产生式,生成对应的SQL语句,再使用数据库执行该SQL,根 -
Sqlite3基本语句及安装过程
SQLite3简介 SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据 -
在SQLite中进行批量操作的有效实现方法
SQLite 是一个轻量级的关系型数据库管理系统,因其高效性和易用性而广受欢迎。在许多应用场景中,批量操作的需求是不可避免的,例如在 -
一文介绍在Hive中NULL的理解
在 Hive 中,NULL 是一个特殊的值,表示未知或缺失。任何与NULL的比较操作(如=,,,=,=,)都会返回NULL,而不是TRUE或FALSE。 1.NULL 的比较规则 在 -
Navicat Premium 12数据库管理解决方案
Navicat Premium 12是一款全面的数据库管理工具,支持多种数据库系统如MySQL、MariaDB、Oracle、SQL Server、PostgreSQL等。它提供了多数据库连接、数据 -
sqlite3命令行工具使用介绍
一、启动与退出 启动数据库连接 1 2 3 sqlite3 [database_file] # 打开/创建数据库文件(如 test.db) sqlite3 # 启动临时内存数据库 (:memory:) sqlite3 :m



-
通过SQL进行分布式死锁的检测与消除
2021-05-19
-
DB2数据库中常见的堵塞问题分析与处
2021-07-26
-
一篇文章带你掌握SQLite3基本用法
2022-08-26
-
MariaDB Spider数据库分库分表实践记录
2022-08-12
-
sQlite常用语句以及sQlite developer的使用
2022-08-26

