
解读SQL生成工具

SQL 生成工具可用于测试Parser与其他数据库产品的兼容性,通过解析YACC语法文件中的产生式,生成对应的SQL语句,再使用数据库执行该SQL,根据结果判断语句是否与其他数据库语法兼容。 01 工
|
SQL 生成工具可用于测试 Parser 与其他数据库产品的兼容性,通过解析 YACC 语法文件中的产生式,生成对应的 SQL 语句,再使用数据库执行该 SQL,根据结果判断语句是否与其他数据库语法兼容。 01 工具使用语法文件预处理预处理目的是将语法文件中无关的内容去除,只保留各个语句的产生式,可以通过命令 bison -v sql.y 获取语法文件中的语法规则(不带 Action),然后再去除生成文件中的无用部分,如终结符列表、非终结符列表、状态转换表等,如下所示: 生成的 sql.output 文件内容如下,我们仅保留其“语法”一节 注:对于保留的“语法” 一节,还需要去除其序号。 对于上述过程,我们通过预处理脚本 preprocess.sh 进行封装,使处理后的文件满足工具的要求。生成的文件形式如下,输出的 .output 文件即为预处理后的语法文件。 SQL 语句生成生成符合条件的语法文件后,即可使用工具生成 SQL。工具支持如下参数: •-b:指定语法文件,必选。语法文件为 preprocess.sh 脚本处理后的产生的文件 •-n:指定待生成的产生式名称,必选 •-R:随机生成模式,可选,默认为枚举模式 •-o:指定生成 SQL 语句的保存文件,可选,默认为 report.csv •-N:限制生成 SQL 条数,可选,默认不限制 02 工具实现该工具包含两个 package:yacc_parser和sql_generator,分别负责完成 Token 解析和 SQL 生成。 产生式的表示方法
Token 解析函数 Tokenize 用于将读取的语法文件中的字符 Token 化,每次调用将返回一个 Token。该函数仅处理了简单的分隔符和引号,并未实现标准词法分析器的正则匹配。 Parse 函数调用 Tokenize 函数,每次返回一个 Token,返回后 Parse 函数根据当前状态和 Token 类型,将一连串的 Token 组装成 Production。 SQL 生成SQL 生成有两种模式: 1、是遍历 Production 中指定产生式的 body 列表,枚举生成 SQL 语句; 2、随机选择 Production 中指定产生式的 body 列表,随机生成 SQL 语句。 1、枚举 枚举的实现方式是使用一个链表保存待 resolve 的Token,每次从链表头取一个 Token,并自增该 Token出现的次数,再根据其每个子表达式中 Token 在记录中出现次数是否大于指定次数,筛选可以继续推导的子表达式。 另一方面使用了两个数组记录当前所取的子表达式的下标(choice)和当前最大子表达式下标(max)进行记录,以便下一次自增 choice 取下一个表达式。 经过筛选后,选取 choice 位置的产生式右部子表达式并将其全部 Token 插入链表头部,然后判断头部是否为 literal 或 keyword,如果是则取出头部放入 SQL 数组,如果不是则继续循环处理链表。 当处理到当前产生式末尾时(判断方式为 choice>max),此时将尝试“进位”,即记录的当前所取的位置数组最后一位自增。 比如:max 数组为 1 2 1 3,choice 数组为 0 0 0 3,则进位后 choice 数组为 0 0 1 0,表示最后一个位置已全部遍历,现在要将倒数第二位自增,最后一位置零,继续下一次排列组合的读取。 生成过程则是通过递归实现,例如针对以下这条产生式,处理逻辑如图所示:
根据记录的 choice 值,选择产生式的第 choice 条子表达式,直到生成一条 SQL。然后再将choice数组进位,继续下一轮选择。 2、随机 随机生成模式与枚举生成模式类似,区别在于其并不会顺序遍历产生式 body 列表中每个 Token,而是随机选择一个 Token 作为组成 SQL 的一部分。 |
您可能感兴趣的文章 :

-
六大主流数据同步工具对比:DataX、Airbyte、Cana
当数据量变大、数据源复杂、实时需求提高,很多团队在选数据同步工具时犯难。本文对 DataX、Airbyte、Canal、Debezium、Fivetran 与 Apache SeaTun -
解读SQL生成工具
SQL 生成工具可用于测试Parser与其他数据库产品的兼容性,通过解析YACC语法文件中的产生式,生成对应的SQL语句,再使用数据库执行该SQL,根 -
一文介绍在Hive中NULL的理解
在 Hive 中,NULL 是一个特殊的值,表示未知或缺失。任何与NULL的比较操作(如=,,,=,=,)都会返回NULL,而不是TRUE或FALSE。 1.NULL 的比较规则 在 -
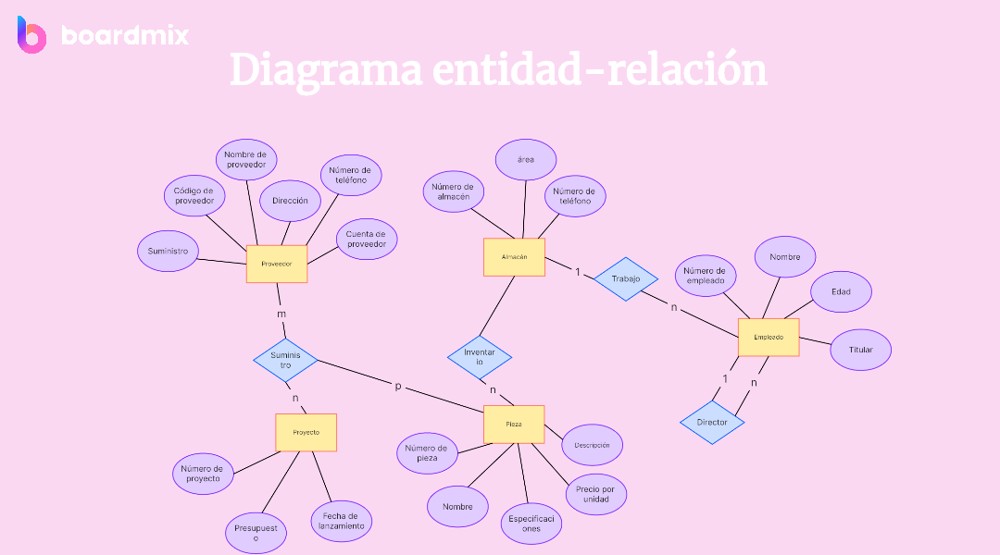
Navicat Premium 12数据库管理解决方案
Navicat Premium 12是一款全面的数据库管理工具,支持多种数据库系统如MySQL、MariaDB、Oracle、SQL Server、PostgreSQL等。它提供了多数据库连接、数据 -
sqlite3命令行工具使用介绍
一、启动与退出 启动数据库连接 1 2 3 sqlite3 [database_file] # 打开/创建数据库文件(如 test.db) sqlite3 # 启动临时内存数据库 (:memory:) sqlite3 :m -

centos虚拟机部署opengauss数据库详细图文
一、基本信息 1、虚拟机安装的centos版本 2、opengauss版本 地址:https://opengauss.org/zh/download/ 3、opengauss和gaussdb的区别 高斯数据库(GaussDB)是云 -
Sql Server 2008 数据库附加错误:9004问题解决方案介
【问题描述】 数据库文件存在异常状况,有可能是因为硬盘有坏区引起的。附加数据库的时候,提示错误9004。 【解决方法】 假设数据库名 -
Access数据中的SQL偏移注入原理解析介绍
使用场景: 目标数据表的字段较多,无法一一获取的时候,尝试使用偏移注入的方式实现SQL注入。 原理: 例如:一个表有6个字段,而你想



-
通过SQL进行分布式死锁的检测与消除
2021-05-19
-
DB2数据库中常见的堵塞问题分析与处
2021-07-26
-
MariaDB Spider数据库分库分表实践记录
2022-08-12
-
InnoDB主键索引树和二级索引树的场景
2022-03-11
-
DB2中REVERSE函数的实现方法
2022-08-12

