
InnoDB主键索引树和二级索引树的场景分析

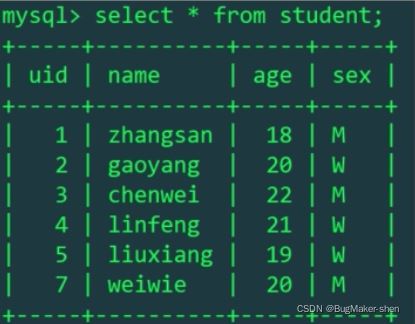
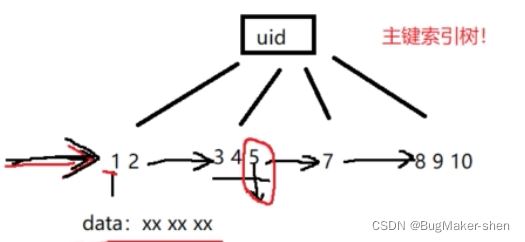
我们这里讨论InnoDB存储引擎,数据和索引存储在同一个文件student.ibd 场景1:主键索引树 uid是主键,其他字段没有添加任何索引 1 select * from student; 如果是这样查询,这表示整表搜索,从
|
我们这里讨论InnoDB存储引擎,数据和索引存储在同一个文件student.ibd
场景1:主键索引树
如果是这样查询,这表示整表搜索,从左到右遍历叶子节点链表,从小到大访问
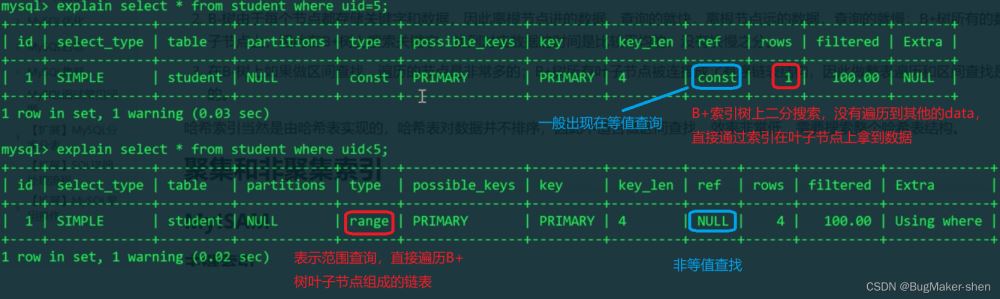
如果是这样查询,这表示范围查询,就直接在有序链表中遍历搜索就可以了,直到遍历到第一个不小于5的key结束遍历
如果是这样查询,这表示等值查询,在索引树上进行二分查找即可
由于name没有索引,于是做整表搜索
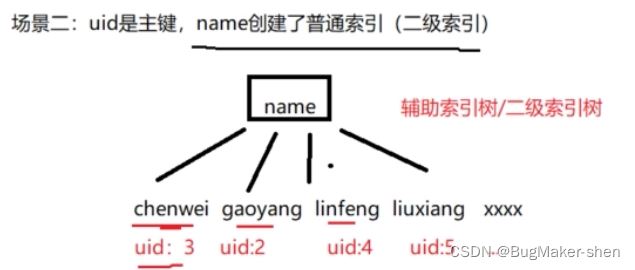
场景2:二级索引树
以name为索引构建的索引树,称为辅助索引树,也叫做二级索引树。key是辅助索引字段name的值,然后还有外加uid主键的值
在辅助索引树上,key是辅助索引的值,也就是name;data数据值是所在记录行的主键值(PRIMARY KEY),也就是uid(并不是表的一行数据) 分析语句1:
因为过滤字段是name且 只select了name一个字段,name有索引,索引树上直接就有,所以从name的二级索引树上去等值匹配linfeng 分析语句2:
这种情况select的是name和uid,而这些在二级索引树上也是直接就有,所以搜索二级索引树就完事了。 分析语句3:
这种情况下就涉及到回表了,这是一个很重要的概念。由于name字段有索引,所以我们会到name字段构建的二级索引树上去查找。但二级索引树没有linfeng这个人所有的信息,所以完整的查询过程应该是这样的:
分析语句4:
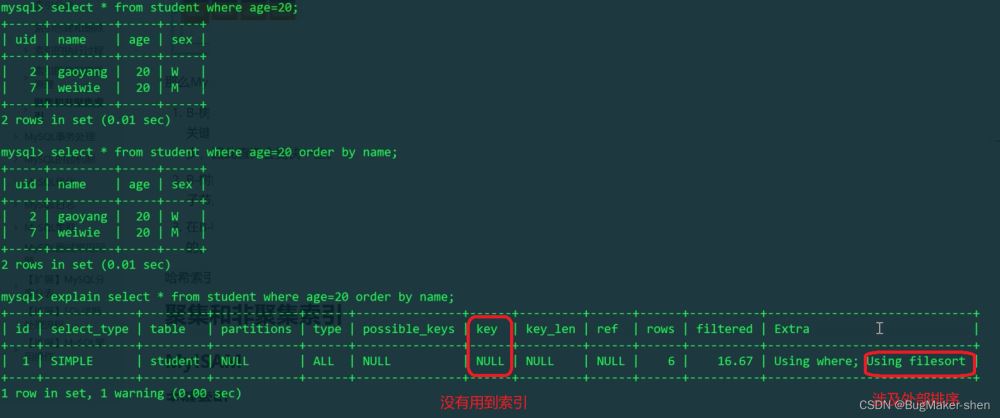
没有用到索引,还使用外部排序了。此外我们还看到using filesort,这时需要优化了。 我们的过滤条件是age,先给age添加索引,看看行不行
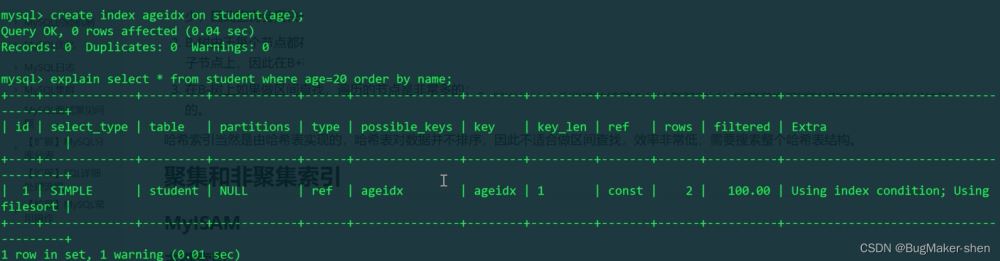
可以看到,age命中索引了,查询age所在的索引树。由于我们写的是select *,依然存在回表。还有using filesort,因为使用age=20查询到的结果是多个,然而name此时是没有顺序的,所以还需要再进行外部排序。 那能不能通过给name加载索引来解决问题呢? 不能,因为一次SQL执行只能用到1个索引,搜索了这个字段的索引树就不会再去搜索另一个字段的索引树了,因为加载索引是要耗费磁盘I/O的,查找多个索引树就太慢了! 分析:既然索引树上只能存自己建立的索引字段以及主键,那我们把需要查询的字段都设置成索引不就好了? 解决方法:我们可以在二级索引树上的key:age+name,形成联合索引,先按age排序,age相同了,再按name排序
再次select *
这时候就使用到联合索引了,而且没有using filesort,这次是这样查询的: 先用age=20在辅助索引树上查找,如果数据足够会找到多个结果,这个结果就是已经排好序的,不需要再using filesort 我们现在直接用第二个字段name作为过滤条件
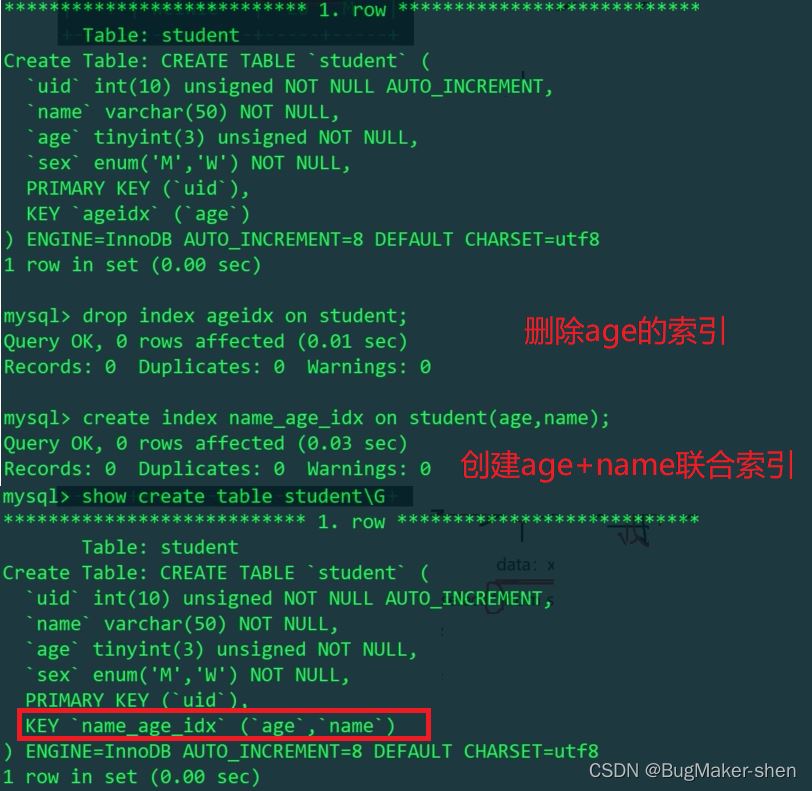
我们看到这里没有用到索引,因为我们用(age,name)创建索引,是先按age排序,再按name排序。如果我们只用name作为过滤条件,这就没有办法使用索引匹配了,因为是优先用age排序。 所以我们经常说,多列索引一定要使用到第1个字段,这样才能用到索引!
在建立(age,name)联合索引的情况下,以下操作不回表(到二级索引树上搜索,再去主索引树上搜索):
以下操作要回表
|






您可能感兴趣的文章 :

-
一文介绍在Hive中NULL的理解
在 Hive 中,NULL 是一个特殊的值,表示未知或缺失。任何与NULL的比较操作(如=,,,=,=,)都会返回NULL,而不是TRUE或FALSE。 1.NULL 的比较规则 在 -
Navicat Premium 12数据库管理解决方案
Navicat Premium 12是一款全面的数据库管理工具,支持多种数据库系统如MySQL、MariaDB、Oracle、SQL Server、PostgreSQL等。它提供了多数据库连接、数据 -
sqlite3命令行工具使用介绍
一、启动与退出 启动数据库连接 1 2 3 sqlite3 [database_file] # 打开/创建数据库文件(如 test.db) sqlite3 # 启动临时内存数据库 (:memory:) sqlite3 :m -

centos虚拟机部署opengauss数据库详细图文
一、基本信息 1、虚拟机安装的centos版本 2、opengauss版本 地址:https://opengauss.org/zh/download/ 3、opengauss和gaussdb的区别 高斯数据库(GaussDB)是云 -
Sql Server 2008 数据库附加错误:9004问题解决方案介
【问题描述】 数据库文件存在异常状况,有可能是因为硬盘有坏区引起的。附加数据库的时候,提示错误9004。 【解决方法】 假设数据库名 -
Access数据中的SQL偏移注入原理解析介绍
使用场景: 目标数据表的字段较多,无法一一获取的时候,尝试使用偏移注入的方式实现SQL注入。 原理: 例如:一个表有6个字段,而你想 -

Navicat导入Excel数据时数据被截断的问题分析与解
在数据库的日常操作中,将Excel数据导入MySQL是常见的需求之一,特别是通过Navicat工具进行Excel数据导入时,可能会遇到数据截断的问题。具



-
通过SQL进行分布式死锁的检测与消除
2021-05-19
-
DB2数据库中常见的堵塞问题分析与处
2021-07-26
-
MariaDB Spider数据库分库分表实践记录
2022-08-12
-
InnoDB主键索引树和二级索引树的场景
2022-03-11
-
DB2中REVERSE函数的实现方法
2022-08-12

