
PostgreSQL索引失效会发生什么?

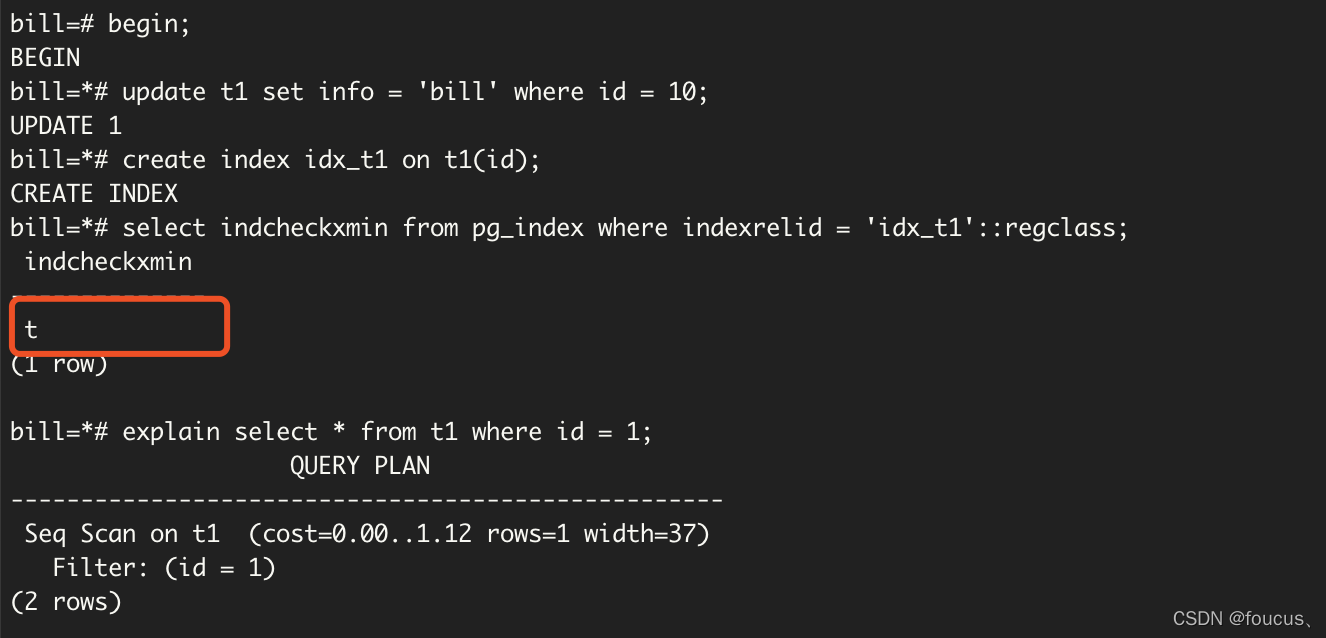
前段时间碰到个奇怪的索引失效的问题,实际情况类似下面这样: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bill=# begin; BEGIN bill=*# create index idx_t1 on t1(id); CREATE INDEX bill=*# explain select * f
|
前段时间碰到个奇怪的索引失效的问题,实际情况类似下面这样:
很显然的问题就是,我在事务中创建了索引,却没办法使用。但是当事务提交了后便可以正常使用了,这是什么情况呢? 这个其实和pg_index中indcheckxmin属性有关,关于这个字段的解释如下:
经检查也确实如此:
那么问题来了,什么情况下创建索引时会将索引的该属性设置为true呢? 从前面官方文档对于该字段的解释,如果表中包含broken HOT chains 则会为true,那什么是broken HOT chains ?似乎和HOT机制有关。那是不是只有存在broken HOT chains 才会设置为true呢? 这里就不卖关子了,直接给出结论,然后我们再去一一验证。 经测试发现,以下两种情况会导致索引的indcheckxmin设置为true:
场景一:broken HOT chains 这种情况,只要在当前事务中表中存在HOT更新的行时就会存在。那么什么时候会进行HOT更新呢?两个前提:
既然如此,实际中常见的两种情况就是:
例子: 表中插入10条数据,自然只有1个page:
进行更新:
查看发现的确是HOT更新: 关于t_infomask2字段的解释这里就不再赘述。
接下来我们创建索引: 可以发现indcheckxmin被设置为true,在当前事务中索引不可用。
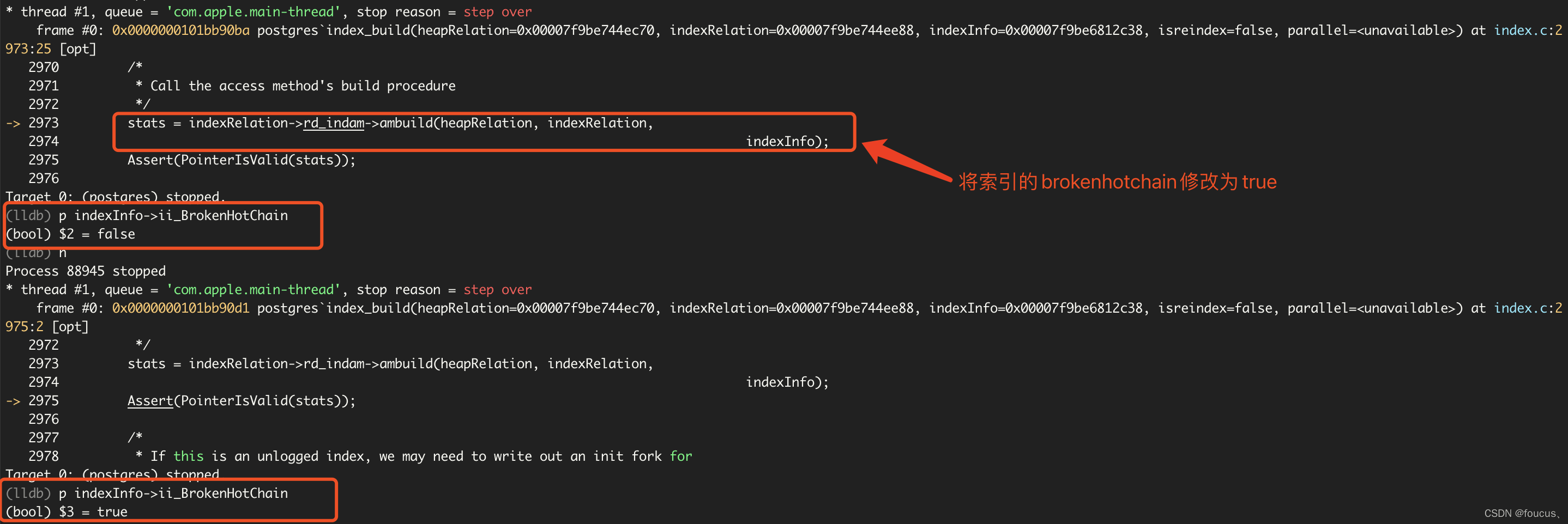
经过验证,在index_build阶段,判断到BrokenHotChain,便将indcheckxmin修改为true。
具体的修改代码如下:
同样我们也可以验证得知,的确是因为brokenhotchains导致的indcheckxmin被设置为true。 场景二:old_snapshot_threshold 先来看例子: 最简单的场景,完全的一张空表,在事务中创建索引indcheckxmin就会被设置为true,果然索引也是不可用。
那么为什么old_snapshot_threshold会产生这样的影响呢? 经过跟踪发现,当开启该参数时,在事务中创建索引的snapshotdata结构如下:
而禁用该参数呢?
可以看到,区别在于不使用该参数时,创建snapshotdata不会设置whenTaken和lsn,那么这两个参数是干嘛的呢? 先来看看snapshotdata的结构:
如上所示,TimestampTz表示snapshot何时产生的,为什么启用old_snapshot_threshold时会设置该值呢? 因为该值正是用来判断快照是否过旧的:
这样我们也比较好理解为什么设置了该参数时创建的索引在当前事务中不可用: 因为我们不设置该参数时,在事务中创建索引是可以保证MVCC的一致性,那么索引便是安全可用的。 而使用参数时,由于TimestampTz被设置,数据库会对其进行判断该行数据是否已经过期,如果过期了那便会被清理掉,这样对于索引来说便是不安全的,没法保证数据的一致性,对于不是hot-safe的索引,自然要将其indcheckxmin设置为true,防止在事务中创建索引后数据实际已经过期被删除的情况。
总结 当pg_index的indcheckxmin字段被设置为true时,直到此pg_index行的xmin低于查询的TransactionXmin视界之前,查询都不能使用此索引。 而产生这种现象主要有两种情况: 1. 表上在当前事务中存在broken HOT chains; 2. old_snapshot_threshold被设置时。 |

您可能感兴趣的文章 :

-
六大主流数据同步工具对比:DataX、Airbyte、Cana
当数据量变大、数据源复杂、实时需求提高,很多团队在选数据同步工具时犯难。本文对 DataX、Airbyte、Canal、Debezium、Fivetran 与 Apache SeaTun -
解读SQL生成工具
SQL 生成工具可用于测试Parser与其他数据库产品的兼容性,通过解析YACC语法文件中的产生式,生成对应的SQL语句,再使用数据库执行该SQL,根 -
Sqlite3基本语句及安装过程
SQLite3简介 SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据 -
在SQLite中进行批量操作的有效实现方法
SQLite 是一个轻量级的关系型数据库管理系统,因其高效性和易用性而广受欢迎。在许多应用场景中,批量操作的需求是不可避免的,例如在 -
一文介绍在Hive中NULL的理解
在 Hive 中,NULL 是一个特殊的值,表示未知或缺失。任何与NULL的比较操作(如=,,,=,=,)都会返回NULL,而不是TRUE或FALSE。 1.NULL 的比较规则 在 -
Navicat Premium 12数据库管理解决方案
Navicat Premium 12是一款全面的数据库管理工具,支持多种数据库系统如MySQL、MariaDB、Oracle、SQL Server、PostgreSQL等。它提供了多数据库连接、数据 -
sqlite3命令行工具使用介绍
一、启动与退出 启动数据库连接 1 2 3 sqlite3 [database_file] # 打开/创建数据库文件(如 test.db) sqlite3 # 启动临时内存数据库 (:memory:) sqlite3 :m



-
通过SQL进行分布式死锁的检测与消除
2021-05-19
-
DB2数据库中常见的堵塞问题分析与处
2021-07-26
-
一篇文章带你掌握SQLite3基本用法
2022-08-26
-
MariaDB Spider数据库分库分表实践记录
2022-08-12
-
sQlite常用语句以及sQlite developer的使用
2022-08-26

