说到机器学习,大家首先想到的可能就是Python和算法了,其实光有Python和算法是不够的,数据才是进行机器学习的前提。
大多数的数据都会存储在文件中,要想通过Python调用算法对数据进行相关学习,首先就要将数据读入程序中,本文介绍两种加载数据的方式,在之后的算法介绍中,将频繁使用这两种方式将数据加载到程序。
下面我们将以Logistic Regression模型加载数据为例,分别对两种不同的加载数据的方式进行介绍。
一、利用open()函数进行加载
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def load_file(file_name): ''' 利用open()函数加载文件 :param file_name: 文件名 :return: 特征矩阵、标签矩阵 ''' f = open(file_name) # 打开训练数据集所在的文档 feature = [] # 存放特征的列表 label = [] #存放标签的列表 for row in f.readlines(): f_tmp = [] # 存放特征的中间列表 l_tmp = [] # 存放标签的中间列表 number = row.strip().split("\t") # 按照\t分割每行的元素,得到每行特征和标签 f_tmp.append(1) # 设置偏置项 for i in range(len(number) - 1): f_tmp.append(float(number[i])) l_tmp.append(float(number[-1])) feature.append(f_tmp) label.append(l_tmp) f.close() # 关闭文件,很重要的操作 return np.mat(feature), np.mat(label) |
二、利用Pandas库中的read_csv()方法进行加载
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def load_file_pd(path, file_name): ''' 利用pandas库加载文件 :param path: 文件路径 :param file_name: 文件名称 :return: 特征矩阵、标签矩阵 ''' feature = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[0, 1]) feature.columns = ["a", "b"] feature = feature.reindex(columns=list('cab'), fill_value=1) label = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[2]) return feature.values, label.values |
三、示例
我们可以使用上述的两种方法加载部分数据进行测试,数据内容如下:
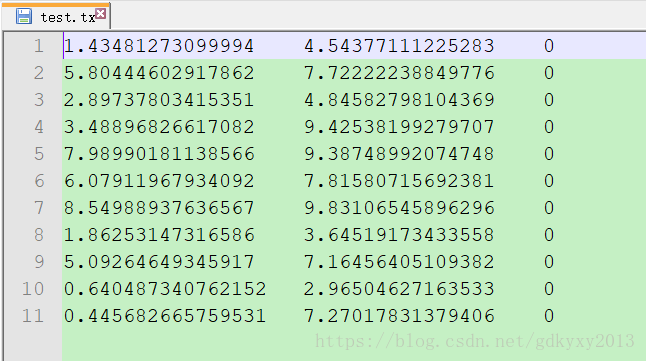
数据分为三列,前两列是特征,最后一列是标签。
加载数据代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
''' 两种方式加载文件 '''
import pandas as pd import numpy as np
def load_file(file_name): ''' 利用open()函数加载文件 :param file_name: 文件名 :return: 特征矩阵、标签矩阵 ''' f = open(file_name) # 打开训练数据集所在的文档 feature = [] # 存放特征的列表 label = [] #存放标签的列表 for row in f.readlines(): f_tmp = [] # 存放特征的中间列表 l_tmp = [] # 存放标签的中间列表 number = row.strip().split("\t") # 按照\t分割每行的元素,得到每行特征和标签 f_tmp.append(1) # 设置偏置项 for i in range(len(number) - 1): f_tmp.append(float(number[i])) l_tmp.append(float(number[-1])) feature.append(f_tmp) label.append(l_tmp) f.close() # 关闭文件,很重要的操作 return np.mat(feature), np.mat(label)
def load_file_pd(path, file_name): ''' 利用pandas库加载文件 :param path: 文件路径 :param file_name: 文件名称 :return: 特征矩阵、标签矩阵 ''' feature = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[0, 1]) feature.columns = ["a", "b"] feature = feature.reindex(columns=list('cab'), fill_value=1) label = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[2]) return feature.values, label.values
if __name__ == "__main__": path = "C://Users//Machenike//Desktop//xzw//" feature, label = load_file(path + "test.txt") feature_pd, label_pd = load_file_pd(path, "test.txt") print(feature) print(feature_pd) print(label) print(label_pd) |
测试结果:
[[ 1. 1.43481273 4.54377111]
[ 1. 5.80444603 7.72222239]
[ 1. 2.89737803 4.84582798]
[ 1. 3.48896827 9.42538199]
[ 1. 7.98990181 9.38748992]
[ 1. 6.07911968 7.81580716]
[ 1. 8.54988938 9.83106546]
[ 1. 1.86253147 3.64519173]
[ 1. 5.09264649 7.16456405]
[ 1. 0.64048734 2.96504627]
[ 1. 0.44568267 7.27017831]]
[[ 1. 1.43481273 4.54377111]
[ 1. 5.80444603 7.72222239]
[ 1. 2.89737803 4.84582798]
[ 1. 3.48896827 9.42538199]
[ 1. 7.98990181 9.38748992]
[ 1. 6.07911968 7.81580716]
[ 1. 8.54988938 9.83106546]
[ 1. 1.86253147 3.64519173]
[ 1. 5.09264649 7.16456405]
[ 1. 0.64048734 2.96504627]
[ 1. 0.44568267 7.27017831]]
[[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]]
[[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]]
从测试结果来看可知两种加载数据的方法得到的数据结果是一样的,故两种方法均适用于加载数据。
注意:
此处是以Logistic Regression模型加载数据为例,数据与数据本身或许会有差异,但加载数据的方式都是大同小异的,要灵活变通。



