第6章:正则表达式的高级应用
6.1 模式匹配与文本处理
正则表达式不仅可以用于简单的搜索和替换,还可以用于复杂的文本处理任务,比如拆分、合并和验证数据。
6.1.1 文本拆分
在编程中,我们经常需要根据特定的模式将文本拆分成多个部分。例如,使用正则表达式拆分日志文件:
|
1 2 3 4 5 |
import re log_data = "2023-12-01 12:00:00 INFO User logged in\n2023-12-01 12:05:00 ERROR Database connection failed" log_entries = re.split(r'\n', log_data) for entry in log_entries: print(entry) |
6.1.2 文本合并
有时我们需要将多个字符串合并成一个字符串,同时插入特定的分隔符:
|
1 2 3 |
items = ['apple', 'banana', 'cherry'] result = ', '.join(items) print(result) # 输出: apple, banana, cherry |
6.2 正则表达式与XML/HTML解析
正则表达式可以用来解析XML和HTML文档,但通常不推荐这样做,因为XML和HTML的结构复杂,正则表达式难以处理嵌套和属性。不过,对于简单的任务,正则表达式可以提供快速的解决方案。
6.2.1 提取标签内容
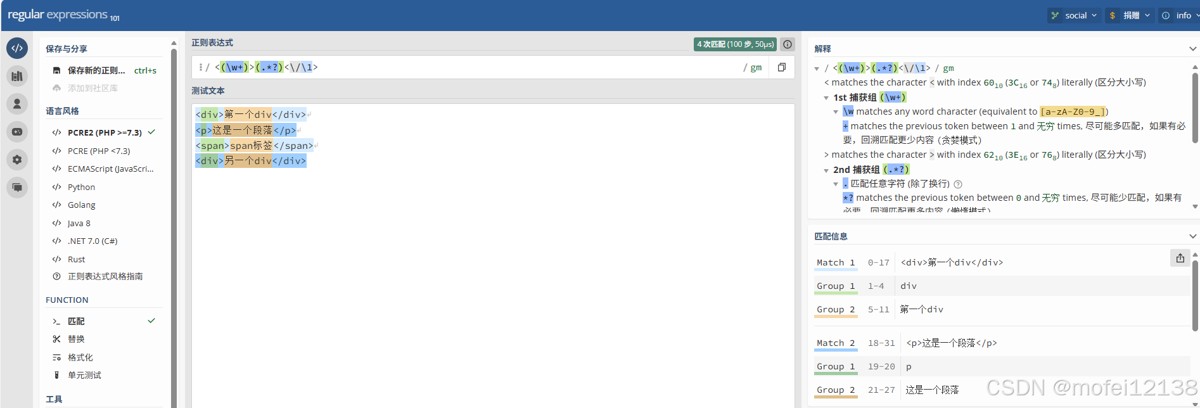
|
1 2 3 4 |
html = "<html><body><h1>Header</h1><p>Paragraph</p></body></html>" tags = re.findall(r'<(\w+)>(.*?)</\1>', html, re.DOTALL) for tag, content in tags: print(f"Tag: {tag}, Content: {content.strip()}") |
6.3 正则表达式在数据分析中的应用
在数据分析中,正则表达式可以用来清洗和验证数据,比如去除字符串中的非法字符或验证数据格式。
6.3.1 数据清洗
|
1 2 3 |
data = ["user1@example.com", "user2@.com", "user3@example..com"] cleaned_data = [re.sub(r'@\.com', '@.com', email) for email in data] print(cleaned_data) # 输出: ['user1@example.com', 'user2@.com', 'user3@example.com'] |
6.3.2 数据验证
|
1 2 3 4 5 6 7 8 |
import re def validate_email(email): pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$' if re.match(pattern, email): return True return False email = "user@example.com" print(validate_email(email)) # 输出: True |
第7章:正则表达式性能优化
7.1 避免复杂的正则表达式
复杂的正则表达式可能会导致性能问题。尽量避免使用过多的嵌套和回溯,这可能会导致“灾难性的回溯”问题。
7.2 使用非捕获分组
非捕获分组(?:)不会保存匹配的文本,这可以减少内存的使用,提高性能。
(?:ab) # 比 (ab) 更高效
7.3 预编译正则表达式
在编程中,如果需要多次使用同一个正则表达式,预编译可以提高效率。
|
1 2 3 4 5 |
import re pattern = re.compile(r'\d+') # 预编译 text = "123 abc 456" matches = pattern.findall(text) print(matches) # 输出: ['123', '456'] |
7.4 避免全局搜索
全局搜索(如re.findall)可能会消耗大量资源,特别是在大型文本上。如果可能,使用局部搜索(如re.search)。
7.5 使用编译的正则表达式
在某些编程语言中,使用编译的正则表达式可以提高匹配速度。
|
1 2 3 4 5 |
let regex = /ab/g; // 使用g标志进行全局搜索 let str = 'ababab'; for (let match of str.matchAll(regex)) { console.log(match[0]); } |
结语
正则表达式是一种强大的文本处理工具,但也需要谨慎使用。通过掌握正则表达式的高级应用和性能优化技巧,我们可以更有效地利用这一工具。希望本文能帮助你深入理解正则表达式的高级用法,并在实际工作中提高效率。