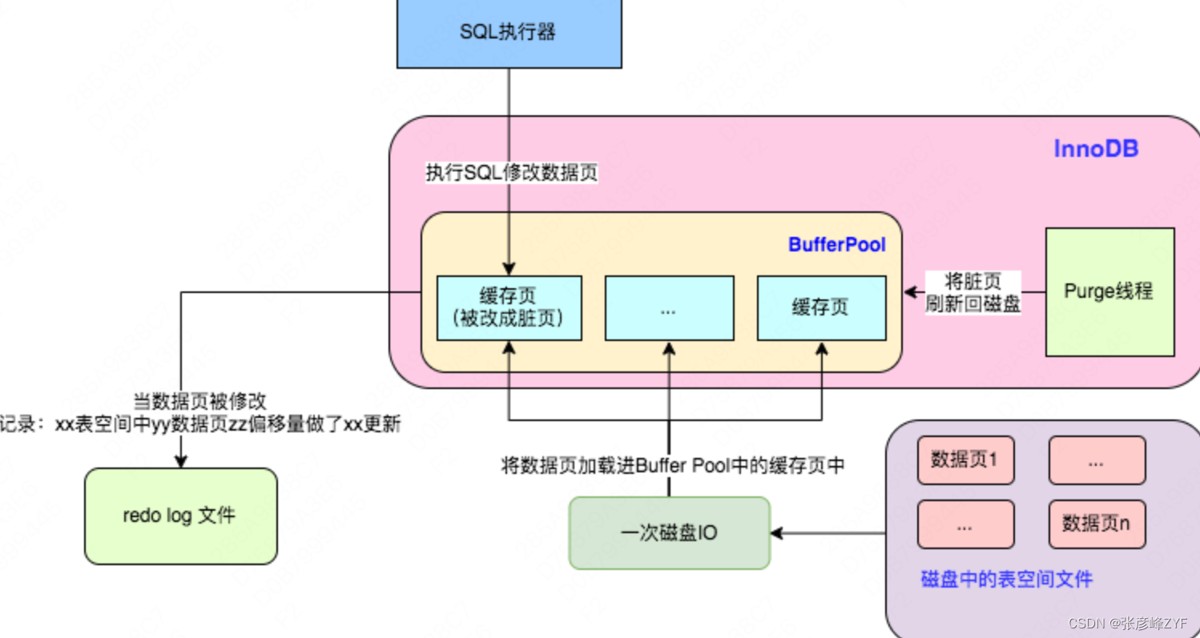
索引下推(Index Condition Pushdown, 简称 ICP)是一种数据库优化技术,旨在减少数据库查询过程中从存储引擎到数据库引擎的数据传输量,从而提升查询性能。通过在索引扫描阶段尽可能多地过滤不需要的数据,索引下推能够减少回表操作(即从索引到实际数据行的查找),提高查询效率。
一、索引下推的基本概念
1. 什么是索引下推?
索引下推是一种优化策略,它将更多的查询条件下推到索引扫描阶段进行过滤,而不仅仅依赖于索引本身来满足查询条件。通过在索引扫描过程中应用额外的过滤条件,数据库可以在更早的阶段排除不符合条件的行,减少后续的数据处理量。
2. 为什么需要索引下推?
传统的索引扫描通常只利用索引本身满足查询条件,例如在使用条件 WHERE a = 1 AND b = 2 时,索引可能仅根据 a 列进行查找。如果需要进一步过滤 b = 2,则可能需要回表获取完整数据行,再进行过滤。这种方式可能导致大量的回表操作,尤其是当查询条件的选择性较低时,会显著影响查询性能。
索引下推通过在索引扫描阶段应用更多的过滤条件,可以减少甚至避免回表操作,从而提高查询效率。
二、索引下推的工作原理
1. 传统索引扫描流程
以一个包含复合索引 (a, b, c) 的表为例,执行以下查询:
|
1 |
SELECT c FROM table_name WHERE a = 1 AND b = 2 AND d = 3; |
传统的索引扫描流程如下:
- 使用索引 (a, b, c) 查找 a = 1 和 b = 2 的索引条目。
- 回表获取 d 列的值。
- 应用 d = 3 的过滤条件。
- 返回符合条件的 c 列值。
在这个流程中,即使 d 列的过滤条件非常严格,索引扫描仍然需要回表获取所有符合 a 和 b 的记录,再进行 d 列的过滤。
2. 启用索引下推后的扫描流程
启用索引下推后,扫描流程如下:
- 使用索引 (a, b, c) 查找 a = 1 和 b = 2 的索引条目。
- 在索引扫描过程中,直接读取索引条目中的 c 列和存储引擎中的 d 列(如果 d 列包含在索引中,则无需回表)。
- 应用 d = 3 的过滤条件。
- 返回符合条件的 c 列值。
通过在索引扫描阶段应用 d = 3 的过滤条件,数据库可以减少需要回表的数据量,从而提高查询效率。
3. 索引下推的条件
索引下推的有效性依赖于以下几个条件:
- 覆盖索引(Covering Index):如果查询只涉及索引中的列,则可以避免回表操作,进一步提升性能。
- 支持索引下推的数据库:并非所有数据库都支持索引下推,具体取决于数据库的实现和优化器的能力。
- 查询条件的复杂性:适用于能够在索引扫描阶段应用的简单或中等复杂度的过滤条件。
三、索引下推的优势
- 减少回表操作:通过在索引扫描阶段应用额外的过滤条件,可以显著减少需要回表获取完整数据行的次数。
- 降低I/O开销:减少不必要的数据读取,降低磁盘I/O开销,提高查询性能。
- 提高查询速度:整体上提升查询的响应速度,特别是在处理大规模数据集时效果显著。
- 优化资源利用:减少CPU和内存的占用,提高系统的资源利用率。
四、不同数据库中的索引下推
1. MySQL
-
支持情况:从 MySQL 5.6 开始,InnoDB 存储引擎支持索引下推。
-
实现方式:InnoDB 在执行索引扫描时,会将部分过滤条件下推到存储引擎层面进行处理,减少需要返回给数据库引擎的数据量。
-
覆盖索引优化:在使用覆盖索引时,InnoDB 能充分利用索引下推,避免回表操作。
-
示例:
1
2
3
4
5
6
7
8
9
10
11
-- 创建表和索引
CREATE TABLE employees (
id INT PRIMARY KEY,
department INT,
salary INT,
age INT,
INDEX idx_dept_salary_age (department, salary, age)
);
-- 查询
SELECT salary FROM employees WHERE department = 5 AND age > 30;
在上述查询中,索引 idx_dept_salary_age 包含了 department 和 salary,但查询中还包含 age > 30。启用索引下推后,InnoDB 可以在索引扫描阶段应用 age > 30 的过滤条件,减少需要回表的数据量。
2. PostgreSQL
- 支持情况:PostgreSQL 12 及以上版本引入了索引下推(称为 Index-Only Scan),可以在特定条件下利用索引下推。
- 实现方式:PostgreSQL 通过 Bitmap Index Scan 和 Index-Only Scan 实现索引下推,减少不必要的数据访问。
- 覆盖索引优化:如果查询只涉及索引中的列,PostgreSQL 可以完全通过索引满足查询,避免回表。
3. Oracle
- 支持情况:Oracle 一直支持类似索引下推的优化技术,如 索引过滤(Index Filtering) 和 索引组访问(Index Fast Full Scans)。
- 实现方式:Oracle 优化器会在索引扫描阶段应用尽可能多的过滤条件,减少回表操作。
- 位图索引:Oracle 的位图索引在处理复杂查询时,尤其是涉及多个过滤条件的查询时,能够高效利用索引下推。
4. SQL Server
- 支持情况:从 SQL Server 2012 开始,支持 Columnstore 索引 的索引下推。
- 实现方式:SQL Server 通过列存储的方式,能够在扫描索引时应用过滤条件,减少不必要的数据访问。
- 列存储优化:特别适用于分析型查询和大规模数据处理。
五、索引下推的实际示例
示例场景
假设有一个 students 表,结构如下:
|
1 2 3 4 5 6 7 |
CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(100), age INT, grade INT, INDEX idx_age_grade (age, grade) ); |
查询1:满足索引下推
|
1 |
SELECT grade FROM students WHERE age = 20 AND grade > 85; |
-
分析:
- 查询涉及的列:age 和 grade。
- 索引 idx_age_grade 包含 age 和 grade。
- 查询只需要返回 grade 列。
-
索引下推:
- 数据库可以使用索引 idx_age_grade 进行索引扫描。
- 在扫描过程中,直接应用 grade > 85 的过滤条件。
- 由于查询只需要 grade 列,且 grade 已包含在索引中,可以避免回表。
-
执行计划(以 MySQL 为例):
1
EXPLAIN SELECT grade FROM students WHERE age = 20 AND grade > 85;
输出可能显示使用 idx_age_grade 索引,并且为 使用覆盖索引(Covering Index),无需回表。
查询2:不满足索引下推
|
1 |
SELECT name FROM students WHERE age = 20 AND grade > 85; |
-
分析:
- 查询涉及的列:name、age 和 grade。
- 索引 idx_age_grade 包含 age 和 grade,但不包含 name。
-
索引下推限制:
- 由于 name 列不在索引中,需要回表获取 name 的值。
- 此时,索引下推可以在索引扫描阶段应用 age = 20 和 grade > 85 条件,但仍需回表获取 name。
查询3:仅部分条件应用索引下推
|
1 |
SELECT grade FROM students WHERE age = 20 AND grade > 85 AND name LIKE 'A%'; |
-
分析:
- 查询涉及的列:grade、age、name。
- 索引 idx_age_grade 包含 age 和 grade。
-
索引下推:
- 可以在索引扫描阶段应用 age = 20 和 grade > 85 的过滤条件。
- 对于 name LIKE 'A%',需要回表获取 name 列进行进一步过滤。
- 索引下推减少了需要回表的数据量,但仍需部分回表操作。
六、索引下推的局限性
- 复杂查询条件:对于包含复杂表达式、子查询或非简单比较的查询条件,索引下推可能难以应用。
- 非覆盖索引:如果查询需要的列不完全包含在索引中,仍需回表操作,限制了索引下推的效果。
- 数据库支持:不同数据库对索引下推的支持程度不同,某些高级特性可能仅在特定版本或存储引擎中可用。
- 索引结构限制:某些索引类型(如哈希索引)可能不支持高效的索引下推操作。
七、优化索引下推的建议
-
设计覆盖索引:
- 尽量使查询所需的所有列都包含在索引中,避免回表需求。
- 例如,对于频繁查询的列,可以在复合索引中包含这些列。
-
优化查询条件:
- 尽可能使用简单的相等条件和范围条件,使索引下推更容易应用。
- 避免在查询条件中使用复杂的函数或表达式,除非这些函数已经应用在索引上。
-
选择合适的索引类型:
- 根据查询模式选择合适的索引类型,如 B-Tree 索引适用于大多数范围和等值查询,位图索引适用于低基数列等。
-
维护索引和统计信息:
- 定期重建或重组索引,保持索引的高效性。
- 确保统计信息的准确性,帮助查询优化器做出正确的决策。
-
使用查询分析工具:
- 利用数据库提供的查询分析工具(如 MySQL 的 EXPLAIN、PostgreSQL 的 EXPLAIN ANALYZE)来检查查询执行计划,确认索引下推的应用情况。
- 根据分析结果调整索引设计和查询结构。
-
分离高基数和低基数列:
- 在复合索引中,通常将高基数列放在前面,低基数列放在后面,以提高索引的选择性和过滤效果。
八、结论
索引下推作为一种强大的查询优化技术,能够显著提升数据库查询性能,尤其是在处理复杂查询条件和大规模数据时。通过在索引扫描阶段尽量多地应用过滤条件,减少回表操作和I/O开销,索引下推有助于提高整体数据库系统的效率。然而,索引下推的效果依赖于索引设计、查询条件复杂性以及数据库系统的支持程度。因此,合理设计索引、优化查询结构以及利用数据库的查询分析工具,是充分利用索引下推优势的关键。