本篇文章介绍python创建属于自己的单词词库 便于背单词
基本思路:以COCA两万单词表为基础,用python爬取金山词霸的单词词性,词义,音频分别存入sqllite。背单词的时候根据需要自定义数据的选择方式。
效果如下:
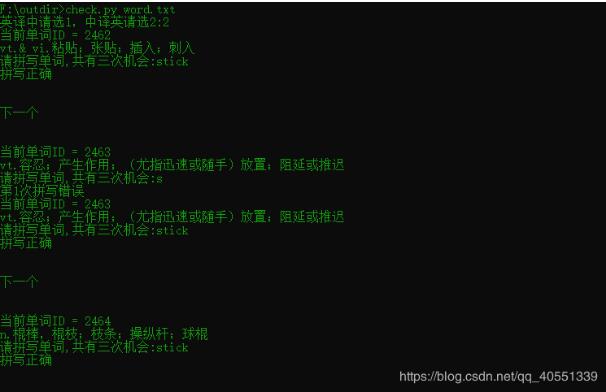
自定义背单词: 根据需要可以将单词放入txt文件中进行测试,可以输出词义拼写单词,也可以输出单词,选择对应释义。 当然还可以给每个单词词义加两个属性值,分别表示学习次数和答错次数,然后可以根据这两个值来选择单词,如果有兴趣的话,可以尝试一下。
基本思路:以COCA两万单词表为基础,用python爬取金山词霸的单词词性,词义,音频分别存入sqllite。背单词的时候根据需要自定义数据的选择方式。
效果如下:
代码写的比较随意,还请见谅。
创建数据库
cu.execute('create table test (id INTEGER PRIMARY KEY AUTOINCREMENT,dc varchar(20),cx varchar(20),cy varchar(50),mp3 varchar(50));')
完整代码,效率不高,不过够用了
import requests
from bs4 import BeautifulSoup
import re
import traceback
import sqlite3
import time
import sys
def ycl(word):
try:
url = "http://www.iciba.com/{}".format(word)
headers = { 'Host': 'www.iciba.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'Referer': 'http://www.baidu.com', 'Connection': 'keep-alive', 'Cache-Control': 'max-age=0', }
response = requests.get(url = url,headers = headers)
soup = BeautifulSoup(response.text,"lxml")
#输出单词词性
cx = soup.find(class_='base-list switch_part')(class_='prop')
#输出词性词义
mp3 = soup.find_all(class_='new-speak-step')[1]
pattern = re.compile(r'http://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+.mp3')
mp3url = re.findall(pattern,mp3['ms-on-mouseover'])
mp3url = '.'.join(mp3url)
r = requests.get(mp3url)
#单词音频输出路径
dress = "E:\\sound\\"
mp3path = dress +word+".mp3"
with open(mp3path, 'wb') as f:
f.write(r.content)
#获取词性个数
meanings =soup.find_all(class_='prop')
#实行每个词性的词义同行输出
for i in range(len(meanings)):
s = soup.find(class_='base-list switch_part')('li')[i]('span')
c = cx[i].text
a = ''
for x in range(len(s)):
b = s[x].text
a = a + b
print(word)
print(c)
print(a)
# 存入数据库的方法
conn = sqlite3.connect("word.db")
cu = conn.cursor()
sql =cu.execute("INSERT INTO test (id,dc,cx,cy,mp3)VALUES(NULL,'%s','%s','%s','%s');"%(word,c,a,mp3path))
print(sql)
conn.commit()
print('\n')
except Exception as e:
print(e)
print("error")
with open("log.txt",'a') as f:
f.write(word+'\n')
def duqudanci(file):
wordcount = 0
for line in open(file):
word = line.strip('\n')
wordcount += 1
print(wordcount)
ycl(word)
if __name__ == '__main__':
conn = sqlite3.connect("word.db")
cu = conn.cursor()
word = ""
#需要爬取的单词
duqudanci(sys.argv[1])
print('下载完成')
conn.commit()
conn.close()
|
自定义背单词: 根据需要可以将单词放入txt文件中进行测试,可以输出词义拼写单词,也可以输出单词,选择对应释义。 当然还可以给每个单词词义加两个属性值,分别表示学习次数和答错次数,然后可以根据这两个值来选择单词,如果有兴趣的话,可以尝试一下。
import sqlite3
import random
import sys
from playsound import playsound
# 中译英
def CtoE():
for j in list1:
sql =cu.execute('select id,dc,cx,cy,mp3 from wordinfo where id = ?',(j,))
for it in sql:
# 返回的是元组,直接对元组查询
c=0
while c<3:
print("当前单词ID = "+str(it[0]))
print("释义:"+it[3])
# 播放音频
playsound(it[4])
a = input("请拼写单词,共有三次机会:")
if a == it[1]:
print("拼写正确")
break;
c += 1
print('第%d次拼写错误'%c)
print('\n')
print("下一个")
print('\n')
# 英译中
def EtoC():
for j in list1:
sql =cu.execute('select id,dc,cx,cy,mp3 from wordinfo where id = ?',(j,))
d =0
for it in sql:
# 返回的是元组,直接对元组查询
c=0
while c<3:
# 释放list2
list2 = []
sql =cu.execute('select cy from wordinfo where id !=? order by random() limit 3',(j,))
for t in sql:
for o in range(len(t)):
#将随机取出的数据放入列表
list2.append(t[o])
# 加入正确答案
p = random.randint(0,3)
list2.insert(p,it[3])
print("当前单词ID = "+str(it[0]))
print("选择单词的对应释义:----"+it[1])
playsound(it[4])
dict1 = {'A':list2[0],'B':list2[1],'C':list2[2],'D':list2[3]}
print("A:"+dict1.get('A')+'\n')
print("B:"+dict1.get('B')+'\n')
print("C:"+dict1.get('C')+'\n')
print("D:"+dict1.get('D')+'\n')
answer1 = input("请选择,共有三次机会(大写):")
if dict1.get(answer1)== it[3]:
print("正确")
break;
c += 1
print('第%d次拼写错误'%c)
d += 1
print('\n')
print("下一个")
print('\n')
def main(file):
for line in open(file):
word = line.strip('\n')
sql =cu.execute('select id from wordinfo where dc = ?',(word,))
for x in sql:
list1.append(x[0])
cho = input("英译中请选1,中译英请选2:")
if cho =="1":
EtoC()
elif cho =="2":
CtoE()
else:
print("错误,请重试")
if __name__ == '__main__':
conn = sqlite3.connect("word.db")
cu = conn.cursor()
list1 = []
word = ""
main(sys.argv[1])
conn.commit()
conn.close()
|
原文链接:https://blog.csdn.net/qq_40551339/article/details/88880899
相关文章


