
S3标签字符清洗的正则表达式实践记录

深入理解 S3 标签字符清洗的正则表达式实践 在构建与 AWS S3 相关的服务时,尤其是使用 S3 标签(Tag)作为资源标识或元数据时,确保标签值符合 AWS 的字符规范是非常重要的。否则,你可能会
深入理解 S3 标签字符清洗的正则表达式实践在构建与 AWS S3 相关的服务时,尤其是使用 S3 标签(Tag)作为资源标识或元数据时,确保标签值符合 AWS 的字符规范是非常重要的。否则,你可能会在上传对象、设置标签或调用 SDK 时遇到 InvalidTag 或 ValidationError 等问题。 本文将结合一个具体的 Python 方法,剖析如何使用正则表达式 [^a-zA-Z0-9 äöüÄÖÜß\+\-=\._:/@] 对标签值进行有效的字符清洗。 一、背景:S3 标签字符限制根据 AWS 官方文档,S3 标签值必须仅包含:
二、Python 示例代码
这段代码的核心在于 re.sub 函数,它通过正则表达式替换掉字符串中所有非法字符,只保留符合 S3 要求的字符。 三、正则表达式解析让我们逐段分析这个正则表达式: [^...]:否定字符集合 表示匹配所有不属于该集合的字符,是我们用来“过滤”的核心机制。 [a-zA-Z0-9 ]:基本字母与数字 允许所有的英文大小写字母和数字,以及空格。 äöüÄÖÜß:德语扩展字符 AWS 的字符集对于欧洲语种的支持,允许常见的德语变音字符和 ß。 特殊符号部分:
这些符号是 AWS 允许在标签中出现的元字符,用于分隔或传递业务信息。 四、使用示例
可以看到:
五、应用场景建议
六、结语正则表达式虽小,却是高质量系统开发中不可忽视的细节。通过合理使用 re.sub 和字符集白名单策略,我们可以确保在 AWS S3 这类对格式要求严格的服务中稳健运行,避免不必要的线上 bug。 |
您可能感兴趣的文章 :

-
正则表达式中的特殊符号的介绍
正则表达式中的特殊符号 如: 1 preg_match(/.+?hxx/is, hxx)); 返回,0,表示没有匹配,这是因为.+?的作用,具体讲一下。 .的作用 作用:匹配除换 -
S3标签字符清洗的正则表达式实践记录
深入理解 S3 标签字符清洗的正则表达式实践 在构建与 AWS S3 相关的服务时,尤其是使用 S3 标签(Tag)作为资源标识或元数据时,确保标签值 -
正则表达式高级应用与性能优化记录
第6章:正则表达式的高级应用 6.1 模式匹配与文本处理 正则表达式不仅可以用于简单的搜索和替换,还可以用于复杂的文本处理任务,比如 -
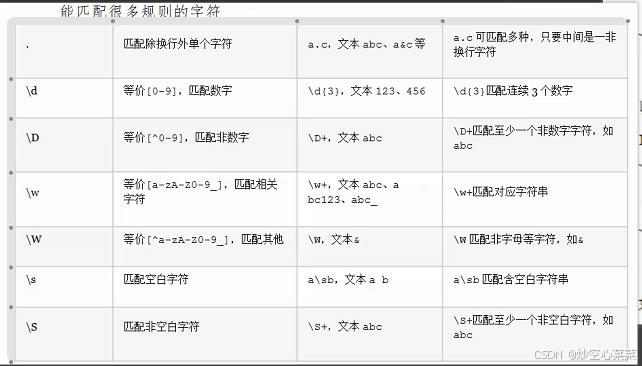
scala中正则表达式的使用介绍
基本概念 在 Scala 中,正则表达式是用于处理文本模式匹配的强大工具。它通过java.util.regex.Pattern和java.util.regex.Matcher这两个 Java 类来实现( -
正则表达式中的test和 /[^A-Za-z0-9]/ ?(推荐)介绍
一、什么是 test 方法? 1. 方法概述 test是 JavaScript 正则表达式对象 (RegExp) 提供的一种方法,用于测试字符串是否匹配特定的正则表达式模式 -
@Pattern用于校验字符串是否符合特定正则表达式的
@Pattern是一个用于校验字符串是否符合特定正则表达式的注解,它在 Java 中常用于验证输入数据的格式。以下是@Pattern注解的详解和使用方法 -
使用正则去掉html中标签与标签之间的空格
要使用正则表达式去除 HTML 标签之间多余的空格,需要考虑几种情况: 多个空格压缩成一个空格:这可以使用\s+匹配一个或多个空格字符,并




-
Java正则表达式里隐藏的陷阱
2021-06-04
-
Python中正则表达式的巧妙使用一文包
2019-05-27
-
如何使用正则表达式对输入数字进行
2022-10-12
-
最实用的正则表达式的整理
2022-10-12
-
正则表达式去除中括号(符号)及里
2019-06-26

