1. 下载darknet源码 在命令窗口(terminal)中进入你想存放darknet源码的路径,然后在该路径下输入依次输入以下命令: git clone https://github.com/pjreddie/darknet cd darknet 上述命令首先从darknet的源
|
1. 下载darknet源码 在命令窗口(terminal)中进入你想存放darknet源码的路径,然后在该路径下输入依次输入以下命令:
上述命令首先从darknet的源码地址复制一份源码到本地,下载下来的是一个名为darknet的文件。然后进入这个名为darknet的文件夹。 2. 修改darknet的Makefile文件Note:如果不需要darknet在GPU上运行,则略过此步骤,只需执行make命令。 在命令窗口输入以下命令打开Makefile文件:
将Makefile文件开头的GPU=0改为GPU=1,如下所示:
修改完之后,需要执行make命令才可以生效。
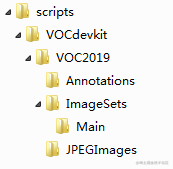
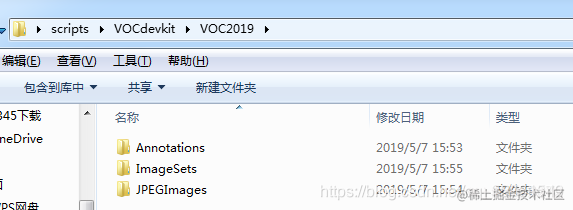
3. 准备数据集在./darknet/scripts文件夹下创建文件夹,命名为VOCdevkit,然后再在VOCdevkit文件夹下创建一系列文件夹,整个目录结构如下所示:
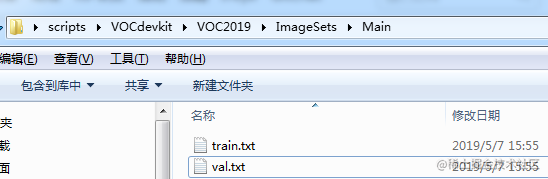
上述文件及文件夹创建好之后,下面来对我们的数据集生成train.txt和val.txt,这两个文件中存放训练图像和测试图像的文件名(不含.jpg后缀)。 新建一个creat_train_val_txt.py文件(名字可以自己随便取),然后将以下代码复制进去(注意相应路径的修改)
制作好creat_train_val_txt.py文件后,在命令行执行该文件:
执行完毕之后可以看到刚刚我们新建的train.txt和val.txt文件中被写进了我们的数据集图片的文件名。
4. 修改voc_label.py打开scripts文件夹下的 voc_label.py 文件,修改信息:#要修改的地方 共三处
保存修改后,运行该文件:
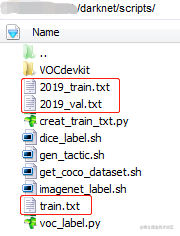
执行完毕之后,会生成2018_train.txt、2018_val.txt、train.txt 三个文件,如下图:
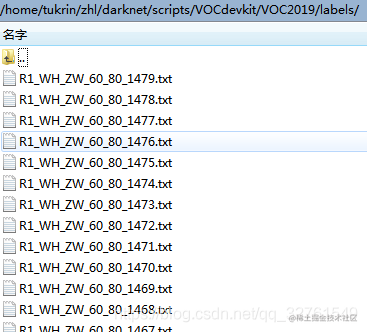
在labels文件夹下会生成图片对应的txt形式的图片标注信息
5. 下载预训练模型为了加速训练过程,可以在darknet官网上下载预训练模型,在该预训练模型上再进行训练。 在命令窗口输入以下命令:
文件保存在script文件夹下即可 6. 修改./darknet/cfg/voc.data文件
7. 修改./darknet/data/voc.name文件将voc.name文件做如下修改:
内容为你的数据集的类别名称,注意和xml文件中的类别名称一致。 8. 修改./darknet/cfg/yolov3-voc.cfg文件该文件为网络结构文件。 首先修改开头处如下:
即,将训练模式打开,将测试模式的语句注释掉。 其中subdivisions为将一个batch(此处为64)分成多大的小batch。如果训练时提示超出内存,则可以相应的改小这两个参数的值。 接着视情况修改开头处的超参数(学习率,迭代次数等):
然后再该文件的底部部分,找到如下语句进行如下修改:
有三处[yolo]的上面的[convolutional]的filters要改 和[yolo]的classes要改开始训练 9. 开始训练在 ./darknet 目录下,在命令窗口中执行以下命令,其中 -gpus 0, 1 用来指定参与训练的GPU编号,可以省略。填0 或1
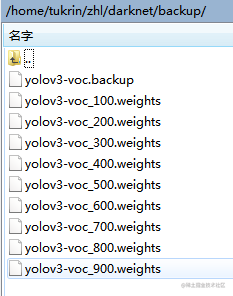
10.训练终止后继续训练方法假如训练由于意外情况,如显存不够终止了,可以通过加载中间权重文件,进而继续训练 中间权重文件在backup文件夹中
把9步权重文件的路径换为backup中文件即可
backup里文件保存规则: 训练1000次之前每100次保存一次。所以上面图片出现了100~900的权重中间文件。 训练1000次之后每10000次保存一次。 yolov3-voc.backup 会保持100整数倍的训练结果。 所以在1000次之后想继续训练的话应该加载 yolov3-voc.backup文件。注意此文件不能作为检查模型使用。 |






2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27