词频统计是指在文本中计算每个词出现的次数。
在 Python 中,可以使用一些第三方库(如 jieba)来分词,然后使用字典等数据结构记录每个词的词频。
Python中文词频统计知识点
- 分词:需要对中文文本进行分词,分词的目的是将文本分解为独立的词语,便于后续的词频统计。
- 字典:使用字典存储每个词的词频。字典的键为词语,值为词频。
- 遍历:遍历分词后的结果,统计每个词出现的次数。
- 排序:对字典按照词频排序,以得到词频最高的词。
- 输出:最后,可以输出词频最高的词,也可以输出完整的词频字典。
Python中文词频分词
安装 jieba 库
使用 jieba.cut() 函数对中文文本进行分词
|
1
2
3
4
5
|
import jieba
text = "梦想橡皮擦的Python博客很不错"
seg_list = jieba.cut(text)
print(list(seg_list))
|
输出结果:
['梦想', '橡皮擦', '的', 'Python', '博客', '很', '不错']
使用字典可以很方便地存储每个词语的词频
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import jieba
text = "梦想橡皮擦的Python博客很不错"
seg_list = jieba.cut(text)
# print(list(seg_list))
word_dict = {}
for word in seg_list:
print(word)
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
print(word_dict)
|
再次整理Python词频统计的具体实现方法:
- 导入 jieba 库,使用 jieba.cut() 函数对中文文本进行分词。
- 遍历分词后的结果,统计每个词出现的次数。
- 使用字典记录每个词出现的次数。
- 对字典按照词频排序,并输出词频最高的词。
代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import jieba
def get_word_frequency(text):
seg_list = jieba.cut(text)
word_dict = {}
for word in seg_list:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
sorted_word_dict = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
return sorted_word_dict
text = "梦想橡皮擦的Python博客很不错"
result = get_word_frequency(text)
print(result)
|

停用词
在分词时,通常会忽略一些词语,这些词语被称为停用词。如常用的助词、介词等。
在 Python 中,可以预先加载停用词表,在分词时,如果词语是停用词,则忽略。
下面是一个简单的例子:
|
1
2
3
4
5
6
7
8
9
10
11
|
import jieba
stop_words = set()
with open("stop_words.txt", "r",encoding='utf-8') as f:
for line in f:
stop_words.add(line.strip())
text = "梦想橡皮擦的Python博客很不错"
seg_list = jieba.cut(text)
filtered_words = [word for word in seg_list if word not in stop_words]
print(filtered_words)
|
“stop_words.txt” 文件中是停用词表,每行一个词语。在代码中,通过 with open 语句读取文件,并将每个词语加入到 stop_words 集合中。在分词后,通过列表推导式,筛选出不是停用词的词语。文件中的内容如下:

词干提取
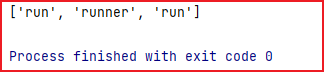
词干提取是将词语的不同形式提取为同一词干的过程。例如 “running” 和 “runner” 可以被提取为 “run”。
在 Python 中,可以使用词干提取工具来进行词干提取,常见的词干提取工具有 nltk 库的 PorterStemmer 和 SnowballStemmer 。
下面是一个简单的例子:
|
1
2
3
4
5
6
7
8
|
import nltk
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer("english")
words = ["run", "runner", "running"]
stemmed_words = [stemmer.stem(word) for word in words]
print(stemmed_words)
|
SnowballStemmer 函数的第一个参数是语言。 english 表示使用英语词干提取器。
其支持多种语言,可以指定不同的语言,以使用不同的词干提取器。例如,如果是法语文本,可以使用 SnowballStemmer("french") 。
stemmer.stem(word) 是 nltk 库的 SnowballStemmer 函数的一个方法,用于提取词干。
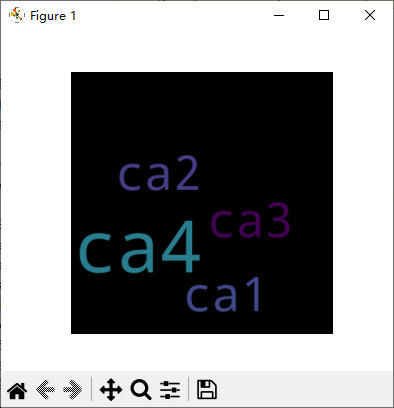
词云图
词云图是一种展示词频的可视化图形,其中词语的大小代表词频的多少。
在 Python 中,可以使用词云库 wordcloud 来生成词云图。
以下是一个使用 wordcloud 库创建词云图的简单示例:
|
1
2
3
4
5
6
7
8
9
|
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = "ca1 ca2 ca3 ca4 ca4 ca4"
wordcloud = WordCloud(width=400, height=400, random_state=21, max_font_size=110).generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
|
首先使用 WordCloud 函数创建一个词云图对象,并设置图片的宽度、高度、随机状态、字体大小等参数。
然后,使用 generate() 方法生成词云图,并将其作为参数传递给 matplotlib 的 imshow() 函数。
最后,使用 show() 方法显示词云图。
Python 中文词频分词其它库
thulac:thulac 是一个中文分词库,支持动态词性标注。
snownlp:snownlp 是一个基于 SnowNLP 的中文自然语言处理库,支持中文分词、情感分析、关键词提取等功能。