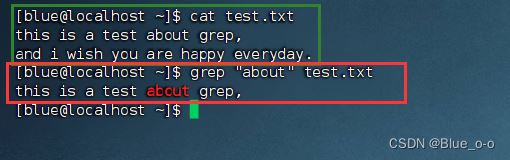
脚本:本质是一个文件,文件里面存放的是特定格式的指令,系统可以使用脚本解析器翻译或解析指令并执行(它不需要编译)
- shell 既是一个用 C 语言编写的应用程序,又是一种脚本语言(应用程序 解析 脚本语言)
- Shell 提供了一个界面,用户通过这个界面访问操作系统内核的服务。
- Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
- Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 命令解析器种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)(大多数Linux 系统默认的 Shell)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
本文档关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。查看自己linux系统的默认解析器命令:echo $SHELL
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
语法详解
编写 shell 脚本文件的时候,最前面要加上一行:#!/bin/bash,因为linux里面不仅仅只有bash一个解析器,还有其它的,它们之间的语法会有一些不同,所以最好加上这一句话,告诉系统要用这个解析器。
#! 是一个约定的标记,告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
注意:
- shell脚本中将多条命令换行时,命令是从上向下执行,写在上面的命令即使执行错误,下面的命令也会继续执行。
- shell脚本中将多条命令写在同一行时,使用分号( ; )分隔,写在前面的命令即使执行失败,写在后面的命令也会继续执行。
数学运算表达式
(( ))是 Shell 数学计算命令,和 C++、C#、Java 等编程语言不同,在 Shell 中进行数据计算不那么方便,必须使用专门的数学计算命令,(( ))就是其中之一。
|
1
2
3
4
5
6
|
+ # 加
- # 减
* # 乘
/ # 除
% # 取余
** # 幂
|
Shell变量
变量分类
根据用途可以分为四种变量(变量的划分,每本书都不相同):
环境变量:一组为系统内核、系统命令和应用程序提供运行环境而设定的变量的统称
内部变量:特定为shell设定的一组变量的统称
参数变量:传参的数据。位置参数是传给函数,语句块等等的数据,可以通过$1 $2… $N 以及配合shell内部变量(如$? $@等)进行引用
用户自定义变量:用户自己设置的变量。又可分为:局部变量和全局变量
局部变量:
- 只在代码块或函数有效,出了代码块或函数,就消失的变量;
- 在代码块或函数中声明的局部变量,必须通过 local 声明,否则它也是对当前shell进程都可见的。
全局变量:
- 在脚本中定义,仅在当前Shell脚本中有效,其他Shell脚本进程不能访问,其作用域从定义的位置开始,到脚本结束或被显示删除的地方为止。
- 全局变量可以升级成为临时环境变量;通过export进行声明,使当前进程的子进程也能使用这一变量。
- 临时环境变量只对该运行环境有效,如果执行另外一个shell脚本,这个临时环境变量无能为力
环境变量和内部变量的区别和使用:
相同:
- 均为shell一启动就加载
- 都是配合 $ 引用,并且在脚本中都是一开始就有的,不需要用户再设定
不同:
- 环境变量可以添加、修改,用户可以重新定义(详细:https://blog.csdn.net/LLZK_/article/details/53813266)
- shell内部变量是固定不变的。
环境变量
环境变量是在操作系统中一个具有特定名字的对象,它包含了一个或多个应用程序将使用到的信息。
Linux是一个多用户的操作系统,每个用户登录系统时都会有一个专用的运行环境,通常情况下每个用户的默认的环境都是相同的。这个默认环境就是一组环境变量的定义。每个用户都可以通过修改环境变量的方式对自己的运行环境进行配置。
环境变量是和shell紧密相关的,用户登录系统后就启动了一个shell,对于Linux来说一般是bash(Bourne Again shell,Bourne shell(sh)的扩展),也可以切换到其他版本的shell。
bash有两个基本的系统级配置文件:/etc/bashrc和/etc/profile。这些配置文件包含了两组不同的变量:shell变量和环境变量。shell变量是局部的,而环境变量是全局的。环境变量是通过shell命令来设置。设置好的环境变量又可以被所以当前用户的程序使用。
环境变量的分类
- 根据环境变量的生命周期可以将其分为 永久性环境变量 和 临时性变量
- 根据用户等级的不同又可以将其分为 系统级变量 和 用户级变量
对所有用户生效的永久性变量(系统级):
这类变量对系统内的所有用户都生效,所有用户都可以使用这类变量。作用范围是整个系统。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 设置方式:
# 使用 vi 命令打开 /etc/profile 文件,用export指令添加环境变量
# 步骤示例:
# 1.打开配置文件,并按 i ,进入编辑模式
vi /etc/profile
# 2.在配置文件末尾添加环境变量
export 环境变量名(一般大写)="值"
# 3.使配置文件立即生效
source /etc/profile
# 注意:
# 1. /etc/profile 只有root(超级用户)才能修改。可以在etc目录下使用 ls -l 查看这个文件的用户及权限
# 2. 添加新的环境变量并退出配置文件后,需要执行命令 source /etc/profile 后才会立即生效。否则在下次重进此用户时才能生效
|
对单一用户生效的永久性变量(用户级)
该类环境变量只对当前的用户永久生效。也就是说假如用户A设置了此类环境变量,这个环境变量只有A可以使用。而对于其他的B,C,D,E….用户等等,这个变量是不存在的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 设置方法:在用户主目录”~”下的隐藏文件 “.bashrc”中添加自己想要的环境变量
# 步骤示例:
# 1.打开配置文件,并按 i ,进入编辑模式
vi ~/.bashrc
# 2.在配置文件末尾添加环境变量
export 环境变量名(一般大写)="值"
# 3.使配置文件立即生效
source ~/.bashrc
# 注意:
# 系统中可能存在两个文件,.bashrc和.bash_profile(有些系统中只有其中一个)
# 原则上来说设置此类环境变量时在这两个文件任意一个里面添加都是可以的。二者设置大致相同
# ~/.bash_profile 是交互式login方式进入bash shell运行。即 .bash_profile 只会在用户登录的时候读取一次
# ~/.bashrc 是交互式non-login方式进入bash shell运行。即 .bashrc 在每次打开终端进行一次新的会话时都会读取
# 查看隐藏文件(.XXX):
# 方式1:命令 ls -al
# 方式2:命令 echo .*
|
临时有效的环境变量(只对当前shell有效)
临时环境变量作用域是当前shell脚本以及当前进程的子进程shell。退出当前shell脚本就消失了
环境变量的常用指令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 查看显示环境变量:echo,变量使用时要加上符号“$”
#例:
echo $PATH
# 设置新的临时环境变量 export
export 新临时环境变量名=内容
# 例:
export MYNAME=”LLZZ”
# 修改环境变量没有指令,可以直接使用环境变量名进行修改。
# 例:
MYNAME=”ZZLL”
# 查看所有环境变量
env
# 查看本地定义的所有shell变量
set
# 删除一个环境变量
unset 变量名
# 例:
unset MYNAME
|
常用的环境变量(都为大写)
PATH:查看命令的搜索路径。通过设置环境变量PATH可以让我们运行程序或指令更加方便。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 查看环境变量PATH
echo $PATH
# 说明:
# 每一个冒号都是一个路径,这些搜索路径都是一些可以找到可执行程序的目录列表。
# 当输入一个指令时,shell会先检查命令是否是内部命令,不是的话会再检查这个命令是否是一个应用程序。
# 然后shell会试着从搜索路径,即PATH中寻找这些应用程序。
# 如果shell在这些路径目录里没有找到可执行文件。则会报错。
# 若找到,shell内部命令或应用程序将被分解为系统调用并传给Linux内核。
# 示例:
# 现在有一个c程序test.c通过gcc编译生成的可执行文件a.out(功能:输出helloworld)。平常执行这个a.out的时候是使用
# 方式1:相对路径调用:./a.out (”.”代表当前目录,”/”分隔符)
# 方式2:绝对路径调用:/home/lzk/test/a.out
# 方式3:通过设置PATH环境变量,直接用文件名调用: a.out (只要可以通过PATH中路径找得到这个可执行文件)
# 使用export指令添加PATH中的路径
# 示例:将a.out的路径添加到搜索路径当中
export PATH=$PATH:路径 # PATH中路径是通过冒号“:”进行分隔的,把新的路径加在最后就OK
|
HOME:指定用户的主工作目录,即为用户登录到Linux系统中时的默认目录,即“~”
HISTSIZE:保存历史命令记录的条数。
- 用户输入的指令都会被系统保存下来,这个环境变量记录的就是保持指令的条数。一般为1000
- 这些历史指令都被保存在用户工作主目录 “~” 下的隐藏文件 .bash_profile 中
- 可以通过指令 history 来查看
LOGNAME:指当前用户的登录名
HOSTNAME:指主机的名称
SHELL:指当前用户用的是哪种shell
LANG/LANGUGE:和语言相关的环境变量,使用多种语言的用户可以修改此环境变量
MAIL:指当前用户的邮件存放目录
PS1:第一级Shell命令提示符,root用户是#,普通用户是$
PS2:第二级Shell命令提示符,默认是“>”
PS3:第三级Shell命令提示符。主要用于select循环控制结构的菜单选择提示符
TMOUT:用户和系统交互过程的超时值,系统与用户进行交互时,系统提示让用户进行输入,但用户迟迟没有输入,时间超过TMOUT设定的值后,shell将会因超时而终止执行。
Shell内部变量
位置变量(参数变量)
当执行一个Shell脚本的时候,如果希望命令行的到传递的参数信息,就要使用位置变量进行如:./myshell.sh 100 200 可以理解为shell脚本的传参方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 预定义变量 # 功能描述
$n # n为数字
# $0表示命令本身(执行脚本的命令)
# $1-9代表第一个参数到第九个参数
# 10以上的参数需要使用大括号进行包裹如:${10}
$* # 传递给函数或脚本的所有参数
$@ # 传递给函数或脚本的所有参数
$# # 代表参数的个数
# 注:
# $* 和 $@ 都表示传递给函数或脚本的所有参数,不被双引号(" ")包含时,都以"$1" "$2" … "$n" 的形式输出所有参数。
# 但是当它们被双引号(" ")包含时,
# "$*" 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;
# "$@" 会将各个参数分开,以"$1" "$2" … "$n" 的形式输出所有参数
|
预定义变量
预定义变量:shell 设计者事先已经定义好的变量,可以直接在 shell 脚本中使用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 预定义变量 # 功能描述
$? # 命令执行后返回的状态
$$ # 当前进程的进程号(PID)
$! # 最近运行的一个后台进程的进程号(PID)
$? # 最后一次执行的命令的返回状态
# 若返回 0 :则上一个命令正确执行;若返回 非0(具体数值由命令自己决定),则上一个命令未正常执行
$LINENO # 调测用。用于显示脚本中当前执行的命令的行号
$OLDPWD # 配合cd命令改换到新目录之前所在的工作目录
# 用法:cd $OLDPWD (切换到之前的工作目录,和cd - 功能一样)
$PPID # 当前进程的父进程的PID
$PWD # 当前工作目录。等同于命令pwd的输出
$RANDOM # 随机数变量。每次引用这个变量会得到一个0~32767的随机数
$REPLY # 通过read命令读入的数据,如果没有被赋值指定变量,则默认赋值到 REPLY 变量中
$SECONDS # 脚本已经运行的时间(以秒为单位)
|
自定义变量:定义、赋值
变量是任何一种编程语言都必不可少的组成部分,变量用来存放各种数据。脚本语言在定义变量时通常不需要指明类型,直接赋值就可以,Shell 变量也遵循这个规则。
在 Bash shell 中,每一个变量的值都是字符串,无论变量赋值时有没有使用引号,值都会以字符串的形式存储。
shell变量和一些编程语言不同,一般shell的变量赋值的时候不用带“$”,而使用或者输出的时候要带“$”。加减乘除的时候要加两层小括号。括号外面要有一个“$”,括号里面的变量可以不用“$”。
定义变量
Shell 支持以下三种定义变量的方式:
|
1
2
3
|
variable=value
variable='value'
variable="value"
|
说明:
- variable 是变量名,value 是赋给变量的值
- 如果 value 不包含任何空白符(例如空格、Tab 缩进等),那么可以不使用引号
- 如果 value 包含了空白符,那么就必须使用单、双引号包围起来。
- 分析:读完命令之后,会对字符串或关键字按照空格切割,切割之后,分为了两个部分:c=he和llo,c=he被理解为一个变量赋值,而llo却找不到匹配的项,并且检索不到相关的命令,所以就会输出这个llo的报错。
- shell脚本中的变量类型只有整型和字符串
注意:
- 赋值号=的周围不能有空格,否则会被解析成命令,报错无此命令。这可能和常见的大部分编程语言都不一样。
Shell 变量的命名规范:
- 变量名由数字、字母、下划线组成;
- 必须以字母或者下划线开头;
- 不能使用 Shell 里的关键字(通过 help 命令可以查看保留关键字)。
单引号和双引号赋值的区别:
定义变量时,变量的值时使用单引号' '包围和双引号" "包围的区别:
- 以单引号' '包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。这种方式比较适合定义显示纯字符串的情况,即不希望解析变量、命令等的场景。
- 以双引号" "包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义。
建议:
- 如果变量的内容是数字,可以不加引号
- 如果需要原样输出就加单引号
- 其他没有特别要求的字符串等最好都加上双引号。定义变量时加双引号是最常见的使用场景
示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#!/bin/bash
a=10
b=20
c="this is a test"
d=$((a+b))
f=test # 变量赋值的时候如果只有一个单词可以不用加引号
time=`date` # date 命令用来获得当前的系统时间
date=`date +%s` # data 命令的 %s 格式控制符可以得到当前的 UNIX 时间戳,可以用于计算脚本的运行时间
# UNIX 时间戳是指从 1970 年 1 月 1 日 00:00:00 到目前为止的秒数
echo $c
echo "a = "$a # 输出a的
echo "a+b = "$((a+b)) # 输出a+b的值
echo $((a+b*a-b/a+a%b+a**2)) #表达式可以很长
|
变量的赋值
|
1
2
3
4
5
6
7
8
|
# 方式1:“=”并初始化
var=value # 注意:如果value是带有空格的字符串,需要加单或双引号
# 方式2:“=”不初始化
var= # 未赋值变量,值为null
# 方式3:read命令
# read命令是读取标准输入的数据,然后存储到指定的变量中。注意:read接收的是标准输入而不是参数,read命令是不接收参数的。
|
自定义变量:引用、修改、删除
变量的引用
|
1
2
3
4
5
6
7
8
9
|
# 方式1
$variable
# 方式2(变量名外面的花括号 { }是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界)。推荐
${variable}
# 方式3
“$variable”或“${variable}”
# 注:引用变量后,双引号会对于引用结果中空格和一些特殊符号进行的解析或者不解析。而引用结果用的空格在命令中的分隔作用会完全改变一个命令的输出,而特殊符号的是否解析也会影响最终的输出结果。
|
|
1
2
3
|
skill="Java"
echo "I am good at ${skill}Script"
# 如果不给 skill 变量加花括号,写成`echo "I am good at $skillScript"`,解释器就会把 $skillScript 当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
|
修改变量的值
已定义的变量,可以被重新赋值,如:
|
1
2
3
4
5
|
url="http://c.biancheng.net"
echo ${url}
# 第二次对变量赋值时不能在变量名前加 $,只有在使用变量时才能加 $
url="http://c.biancheng.net/shell/"
echo ${url}
|
删除变量
使用 unset 命令可以删除变量。
语法:
注意:
- 变量被删除后不能再次使用
- unset 命令不能删除只读变量
示例:
|
1
2
3
4
|
#!/bin/sh
myUrl="http://c.biancheng.net/shell/"
unset myUrl
echo $myUrl # 会没有任何输出
|
自定义变量:设置只读
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
|
1
2
3
4
5
|
#!/bin/bash
myUrl="http://c.biancheng.net/shell/"
readonly myUrl
myUrl="http://c.biancheng.net/" # 会报错
|
Shell命令替换:将命令的结果赋值变量
Shell 也支持将命令的执行结果赋值给变量,常见的有以下两种方式:
|
1
2
3
4
5
6
|
# 两种方式可以完成命令替换,一种是$(),一种是反引号` `
variable=$(commands)
variable=`commands`
# 说明:
# 1.variable 是变量名,commands 是要执行的命令
# 2.commands 可以只有一个命令,也可以有多个命令,多个命令之间以分号;分隔
|
注意:
如果被替换的命令的输出内容包括多行(也即有换行符),或者含有多个连续的空白符,那么在输出变量时应该将变量用双引号包围,否则系统会使用默认的空白符来填充,这会导致换行无效,以及连续的空白符被压缩成一个,出现格式混乱的情况。
两种变量替换的形式是等价的,可以随意使用
反引号和单引号非常相似,容易产生混淆,所以不推荐使用这种方式;
使用 $() 相对清晰,有些情况也必须使用 $(),比如$() 支持嵌套,反引号不行
$() 仅在 Bash Shell 中有效,而反引号可在多种 Shell 中使用。
Shell变量表达式
|
1
2
3
4
5
6
7
8
9
10
|
# 表达式 # 说明
${#string} # 计算$string的长度
${string:position} # 从pos位置开始提取字符串
${string:position:len} # 从pos位置开始提取长度为len的字符串
${string#substr} # 从开头删除最短匹配子串
${string##substr} # 从开头删除最长匹配子串
${string%substr} # 从结尾删除最短匹配子串
${string%%substr} # 从结尾删除最长匹配子串
# 注意:字符串的长度包括空格,但是没有像C语言中那种'\0'字符
|
示例
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
str="a b c d e f g h i j"
echo "the source string is "${str} #源字符串
echo "the string length is "${#str} #字符串长度
echo "the 6th to last string is "${str:5} #截取从第五个后面开始到最后的字符
echo "the 6th to 8th string is "${str:5:2} #截取从第五个后面开始的2个字符
echo "after delete shortest string of start is "${str#a*f} #从开头删除a到f的字符
echo "after delete widest string of start is "${str##a*} #从开头删除a以后的字符
echo "after delete shortest string of end is "${str%f*j} #从结尾删除f到j的字符
echo "after delete widest string of end is "${str%%*j} #从结尾删除j前面的所有字符包括j
|
shell测试判断:test 、 [ ] 、[[ ]]
Shell中的 test 命令和 [ ] 用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
[[ ]] 是 bash 程序语言的关键字。并不是一个命令,[[ ]] 结构比[ ]结构更加通用。在 [[ 和 ]] 之间所有的字符都不会发生文件名扩展或者单词分割,但是会发生参数扩展和命令替换。支持字符串的模式匹配,使用 =~ 操作符时甚至支持shell的正则表达式。字符串比较时可以把右边的作为一个模式,而不仅仅是一个字符串,比如 [[ hello == hell? ]] ,结果为真。[[ ]] 中匹配字符串或通配符,不需要引号。
使用 [[ ]] 条件判断结构,而不是 [ ],能够防止脚本中的许多逻辑错误。比如:&&、||、<、> 操作符能够正常存在于 [[ ]] 条件判断结构中,但是如果出现在 [ ] 结构中的话,会报错。比如可以直接使用 if [[ $a !=1 && $a != 2 ]],如果不使用双括号, 则为 if [ $a -ne 1] && [ $a != 2 ] 或者 if [ $a -ne 1 -a $a != 2 ]。
bash把双中括号中的表达式看作一个单独的元素,并返回一个退出状态码。
注意:使用 [ ] 的时候必须要每个变量之间都要有空格,和左右中括号也要有空格,否则报错。
数值测试
| 参数 |
说明 |
| -eq |
等于则为真 |
| -ne |
不等于则为真 |
| -gt |
大于则为真 |
| -ge |
大于等于则为真 |
| -lt |
小于则为真 |
| -le |
小于等于则为真 |
字符串测试
| 参数 |
说明 |
| = |
等于则为真 |
| != |
不相等则为真 |
| -z 字符串 |
字符串的长度为零则为真 |
| -n 字符串 |
字符串的长度不为零则为真 |
文件测试
| 参数 |
说明 |
| -e 文件名 |
如果文件存在则为真 |
| -f 文件名 |
如果文件存在且为普通文件则为真 |
| -d 文件名 |
如果文件存在且为目录则为真 |
| -r 文件名 |
如果文件存在且可读则为真 |
| -w 文件名 |
如果文件存在且可写则为真 |
| -x 文件名 |
如果文件存在且可执行则为真 |
| -s 文件名 |
如果文件存在且至少有一个字符则为真 |
| -c 文件名 |
如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 |
如果文件存在且为块特殊文件则为真 |
示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#!/bin/bash
# 文件测试
echo "Please input two numbers:"
read num1
read num2
echo "num1 = "${num1}
echo "num2 = "${num2}
echo -e "by test\n"
test $num1 -eq $num2 && echo "num1 == num2" || echo "num1 != num2"
echo -e "by []\n"
[ $num1 -eq $num2 ] && echo "num1 == num2" || echo "num1 != num2"
# 数值测试
echo "Please input a filename: "
# 从标准输入获取一个文件名,并存入filename变量中
read filename
echo -e "by test\n"
test -f $filename && echo "这是一个普通文件" || echo "这不是一个普通文件"
echo -e "by []\n"
[ -f $filename ] && echo "这是一个普通文件" || echo "这不是一个普通文件"
|
逻辑操作符:与、或、非
Shell 还提供了 与( -a )、或( -o )、非( ! ) 三个逻辑操作符用于将测试条件连接起来,其优先级为: ! 最高, -a 次之, -o 最低。
示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
# 逻辑操作符和字符串测试
echo "Please input a city name: "
# 从标准输入获取一个值,并存入city变量中
read city
if "成都" = $city -o "南京" = $city
then
echo '城市是成都或南京'
else
echo '城市既不是成都也不是南京'
fi
|
shell条件分支结构语句
单分支判断语句
格式:
|
1
2
3
|
if 条件 ; then 结果; fi
# 最后面一定要有fi,在shell脚本里面,控制分支结构结束都要和开头的单词相反,例如,if <–> fi,case <–> esac
|
示例
|
1
2
3
4
5
6
7
8
9
|
#!/bin/bash
echo "Please input a filename"
# read filename:表示从标准输入获取一个文件名,并存入felename变量中
read filename
if [ -f $filename ]
then
echo "this file is a ordinary file."
fi
|
双分支判断语句
格式:
|
1
|
if 条件 ; then 结果; else 结果; fi
|
示例
|
1
2
3
4
5
6
7
8
9
10
|
#!/bin/bash
echo "Please input a filename"
read filename
if [ -f $filename ]
then
echo "this file is a ordinary file."
else
echo "this file is not a ordinary file."
fi
|
多分支判断语句
多分支判断有两种(和C语言的一样 ):if-else if 和 case
语法:
|
1
|
if 条件 ; then 结果; elif 条件; then 结果; else 结果; fi
|
if-else if 示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#!/bin/bash
echo "Please input your math grades"
read grades
if [ $grades -gt 100 ] || [ $grades -lt 0 ];then
echo "Please input the number range in 0 - 100"
fi
if [ $grades -ge 90 ] && [ $grades -le 100 ]
then
echo "Your grade is excellent."
elif [ $grades -ge 80 ] && [ $grades -le 89 ];then
echo "Your grade is good."
elif [ $grades -ge 70 ] && [ $grades -le 79 ];then
echo "Your grade is middle."
elif [ $grades -ge 60 ] && [ $grades -le 69 ];then
echo "Your grade is passing."
else
echo "Your grade is badly."
fi
|
case 示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#!/bin/bash
echo "Please input a command"
read cmd
case $cmd in
cpu) echo "The cpu information is"
cat /proc/cpuinfo;;
mem) echo "The mem information is"
cat /proc/meminfo;;
device) echo "The device information is"
cat /proc/scsi/device_info;;
CD-ROM) echo "The CD-ROM information is"
cat /proc/sys/dev/cdrom/info;;
*) echo "Your input command is invalid"
esac
|
shell循环语句
for语句
格式:
|
1
2
3
4
|
for 变量 in 列表
do
语句
done
|
示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#!/bin/bash
arr=("0" "1" "2" "3" "4" "5" "6" "7" "8" "9" "a" "b" "c" "e" "e" "f")
# 遍历(不带数组下标。* 和 @ 均可)
for value in ${arr[*]}
do
echo $value
done
# 遍历(带数组下标)
for (( i = 0 ; i < ${#arr[@]} ; i++ ))
do
echo ${arr[$i]}
done
|
while语句
while语句是只要条件为真就执行下面语句。
格式:
|
1
2
3
4
|
while 条件
do
语句
done
|
需要注意的是,这里的条件除了 while true 可以这样写,其它的条件都要用 test或者 []来判断
示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# -----------文件名为test.sh-----------
#!/bin/bash
# $1 为调用脚本时的第1个传参
i=$1
while [ $i -gt 0 ]
do
echo $i
((i--))
done
# -----------调用-----------
sh test.sh 10 # 文件名test.sh 后面跟的是参数,$0代表文件名,$1代表第一个参数...
|
until语句
until语句是只要条件为假就执行下列语句
格式:
|
1
2
3
4
|
until 条件
do
语句
done
|
示例
|
1
2
3
4
5
6
7
8
|
#!/bin/bash
i=$1
until [ $i -le 0 ]
do
echo $i
((i--))
done
|
Shell函数
格式:
|
1
2
3
4
5
|
[function] funcName()
{undefined
语句
[return 返回值]
}
|
说明:
- Shell 函数 return的返回值只能是整数,一般用来表示函数执行成功与否,0表示成功,其他值表示失败。如果 return 其他数据,比如一个字符串,报错提示:“numeric argument required”。
- return 返回值是可选的;如果没有return,则默认返回最后一条语句执行成功与否的状态值
- 传参到函数中使用位置参数;位置参数在函数中的使用:从$1到$n,$0 是文件名
函数调用方式:
|
1
2
3
4
5
6
7
|
# 方式1:调用函数,然后再使用预定义变量 $? 获取函数返回值
function_name [arg1 arg2 ......]
$?
# 方式2:调用函数并将函数的标准输出赋值到一个变量中。注意:不是返回值
value=`function_name [arg1 arg2 ......]`
value=$(function_name [arg1 arg2 ......])
|
示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
#打印数字
printNum()
{
echo $1 # 位置参数的使用
}
for i in `seq 2 8` # seq是一个命令,顺序生成一串数字或者字符
do
printNum $i # 位置参数的传参
done
|
函数输出字符串的方式:
使用反引号`` 调用的方式将函数的标准输出赋值到一个变量中,脚本在需要的时候访问这个变量来获得函数的输出值。
注意:若函数内进行了多次标准输出,则会将所有的输出值一起赋值到变量中。推荐函数内只进行一次标准输出。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
# 函数输出字符串
getString()
{
echo "abc"
return 0
}
# 函数输出赋值
value=`getString`
# 使用
echo ${value}-xxxx
|
Shell脚本的执行方式
(以下方式,指定脚本可以使用绝对路径,也可以使用相对路径)
路径/xxx.sh:先按照文件中 #! 指定的解析器解析,如果 #! 指定指定的解析器不存在 才会使用系统默认的解析器。
注意:
- 这种方式需要被执行文件有可执行权限(x)(chmod +x 文件名:给文件的所有身份都加上执行权限),否则报错
- 该方式,即使脚本就在当前路径,也必须指定:./xxx.sh
bash xxx.sh:指明先用bash解析器解析,如果bash不存在才会使用默认解析器
sh xxx.sh:直接使用默认解析器解析。可以使用相对路径,也可以使用绝对路径
. xxx.sh:直接使用默认解析器解析注意:.(点)和文件名直接有一个空格
拓展
获取本机ip地址脚本命令
方法一:ip addr
多网卡情况也是返回第一个IP
|
1
|
ip addr | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}' | sed -n '1p'
|
shell方法二:ifconfig -a
|
1
2
3
4
5
6
7
8
9
|
ifconfig -a | grep inet | grep -v 127.0.0.1 | grep -v inet6 | awk '{print $2}' | tr -d "addr:"
# 命令解析
- ifconfig -a 和window下执行此命令一样道理,返回本机所有ip信息
- grep inet 截取包含ip的行
- grep -v 127.0.0.1 去掉本地指向的那行
- grep -v inet6 去掉包含inet6的行
- awk { print $2} $2 表示默认以空格分割的第二组 同理 $1表示第一组
- tr -d "addr: 删除"addr:"这个字符串
|
多网卡情况
倘若有多个网卡,可能会出现多个不同网段的IP,这个时候如果还是执行上述命令就会返回多个IP,如下:
假设某个机器有192...8和10...*网段的IP,现在要实现不同网段的IP地址打印不同的输出,shell脚本如下
|
1
2
3
4
5
6
7
8
9
|
#!/bin/sh
ip=`ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"?`
echo $ip
if[[ $ip =="10."*]]
then
echo "该网段是10.*.*.*网段"
else
echo "该网段是192.*.*.*网段"
fi
|
jq命令:操作 JSON
jq命令允许直接在命令行下对JSON进行操作,包括分片、过滤、转换等
jq是用C编写。
jq的预编译的二进制文件可以直接在Linux、OS X和windows系统上运行,在linux系统中可以直接用yum安装。
准备json串:kumufengchun.json
|
1
2
3
4
5
6
7
8
9
|
{
"name":"kumufengchun",
"age":"18",
"city":"beijing",
"email":"kumufengchun@gmail.com",
"date":"Thursday",
"country":"China",
"company":["baidu","google","alibaba"]
}
|
准备json串:
|
1
2
3
4
5
6
7
8
9
10
|
[
{
"name":"JSON",
"good":true
},
{
"name":"XML",
"good":false
}
]
|
jq基本使用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
# 用jq .直接查看json文件内容
# 方式1
jq . kumufengchun.json
# 方式2
cat kumufengchun.json | jq .
# 输出某个字段或者某个索引的值
# 语法:
jq '.<key>' # 这里key是字段名称
# 实例
jq .name kumufengchun.json
# 输出:"kumufengchun"
# 使用 -r 参数,不含双引号输出结果
jq -r .name kumufengchun.json
# 输出: kumufengchun
# 输出数组的值
# 语法:
jq '.<key>[<value>]' # 这里value是数组的索引整数值
# 实例
jq '.company[0]' kumufengchun.json
# 输出列表、数组的一部分,对其进行切片
# 语法:
jq '.<list-key>[s:e]' # 返回的是数组或者列表的index从s开始(包括s)到e结束(不包括e)
# 实例
jq '.company[0:2]' kumufengchun.json
# 也可以省略开始的index,只有结束的index,如下,仍然是不包括结束index的值
jq '.company[:3]' kumufengchun.json
# 也可以省略结束的index,只有开始的index,如下,输出到最后
jq '.company[1:]' kumufengchun.json
# 开始的索引也可以是负数,表示从后边倒着数,从-1开始数
jq '.company[-2:]' kumufengchun.json
# 循环输出所有的值,如数组嵌套
# 语法:
jq '.[]'
# 实例
jq '.[]' test.json
# 输出多个索引的值,可以用逗号分割
# 语法:
jq '.key1,.key2'
# 实例
jq '.name,.age' kumufengchun.json
# 如果是数组,用中括号括起来要输出的键值,键值先写谁,先输出谁
jq '.company[2,0]' kumufengchun.json
# 用管道符号|可以对其进行再次处理
# 语法:
jq .[] | .<key1>
# 实例
jq '.[]|.name' test.json
# 括号的作用
echo 1 | jq '(.+2)*5'
# 输出:
15
echo {1,2,3} | jq '(.+2)*5'
# 输出:
15
20
25
# length求长度,如果是字符串是求的字符串的长度,如果是数组则求得是数组的长度
cat kumufengchun.json | jq '.[] | length'
# 输出所有的keys
# 语法:
jq keys
# 实例
cat kumufengchun.json | jq 'keys'
# 输出数组的keys(索引)
cat kumufengchun.json | jq '.company | keys'
# 判断存不存在某个键
cat kumufengchun.json | jq 'has("email")'
# 输出:
true
|
获取 tee 前一个命令返回值
管道中的命令,使用 $? 只能获取管道中最后一条命令的返回值
PIPESTATUS[n],获取管道中第n个命令的返回值
示例:
|
1
2
3
|
cp abc def 2>&1 | tee a.log
# ${PIPESTATUS[0]} 获取的是 cp 命令的返回值
test ${PIPESTATUS[0]} -ne 0 && exit
|
eval:执行字符串命令
|
1
2
3
|
#!/bin/bash
cmd="mkidr aaa"
eval $cmd
|
字符串截取
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
var=http://www.aaa.com/123.htm
# 1. # 号截取,删除左边字符,保留右边字符
echo ${var#*//}
# 其中 var 是变量名,# 号是运算符,*// 表示从左边开始删除第一个 // 号及左边的所有字符
# 即删除 http://
# 结果是 :www.aaa.com/123.htm
# 2. ## 号截取,删除左边字符,保留右边字符。
echo ${var##*/}
# ##*/ 表示从左边开始删除最后(最右边)一个 / 号及左边的所有字符
# 即删除 http://www.aaa.com/
# 结果是 123.htm
# 3. %号截取,删除右边字符,保留左边字符
echo ${var%/*}
# %/* 表示从右边开始,删除第一个 / 号及右边的字符
# 结果是:http://www.aaa.com
# 4. %% 号截取,删除右边字符,保留左边字符
echo ${var%%/*}
# %%/* 表示从右边开始,删除最后(最左边)一个 / 号及右边的字符
# 结果是:http:
# 5. 从左边第几个字符开始,及字符的个数
echo ${var:0:5}
# 其中的 0 表示左边第一个字符开始,5 表示字符的总个数。
# 结果是:http:
# 6. 从左边第几个字符开始,一直到结束。
echo ${var:7}
# 其中的 7 表示左边第8个字符开始,一直到结束。
# 结果是 :www.aaa.com/123.htm
# 7. 从右边第几个字符开始,及字符的个数
echo ${var:0-7:3}
# 其中的 0-7 表示右边算起第七个字符开始,3 表示字符的个数。
# 结果是:123
# 8. 从右边第几个字符开始,一直到结束
echo ${var:0-7}
# 表示从右边第七个字符开始,一直到结束。
# 结果是:123.htm
# 注:(左边的第一个字符是用 0 表示,右边的第一个字符用 0-1 表示)
|
父脚本捕捉子脚本(子进程)的中止
- exit 0:正常运行程序并退出程序;
- exit 1:非正常运行导致退出程序;exit 后面数值大于0,均为非正常退出
子脚本手动进行中止操作
|
1
2
3
|
#!/bin/bash
# 子脚本
echo aaa && exit 1
|
父脚本通过 $?(有 tee 命令时,使用${PIPESTATUS[0]}`)命令获取子脚本的返回值
Shell脚本加载另一个脚本
|
1
2
3
4
5
6
7
|
#!/bin/bash
# 方式1:source # 注意:被加载的脚本,不能缺省路径
source ./first.sh
# 方式2:点号(.) # 注意:1.被加载的脚本,不能缺省路径。2.点号与脚本文件之间记得要有空格
. ./first.sh
|
- 使用source命令和点号(.)是等价的,类似于C/C++中的#include预处理指令,都是将指定的脚本内容加载至当前的脚本中,由一个Shell进程来执行。
- 使用sh命令来调用另外的脚本,会开启新的Shell进程来执行指定的脚本,父进程中的变量在子进程中无法被访问到。
启用子shell线程
子shell在linux脚本中使用()实现,即在()中的代码会在子shell中执行