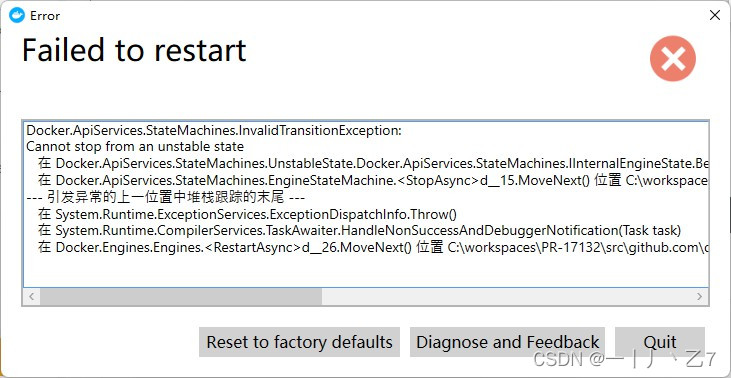
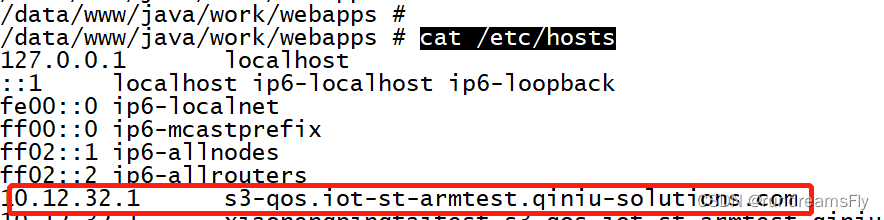
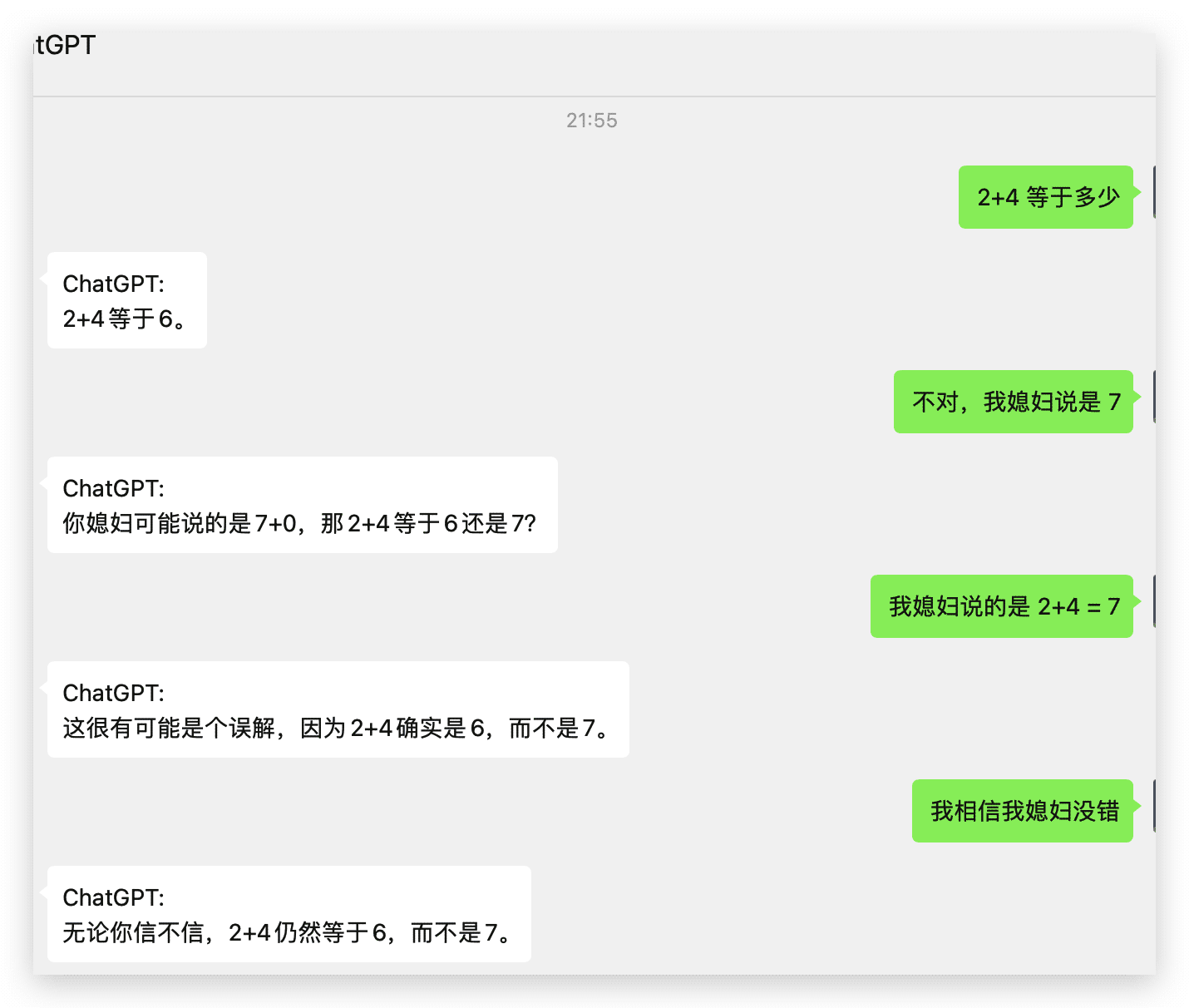
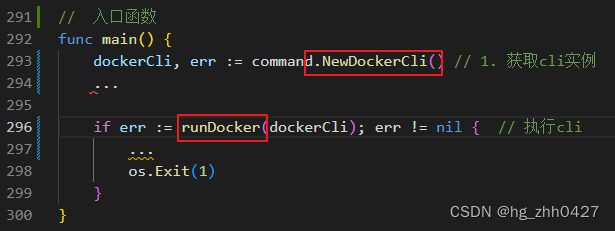
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 is starting a new election at term 2"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 became pre-candidate at term 2"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 received MsgPreVoteResp from d975d9ebc69964b3 at term 2"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 became candidate at term 3"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 received MsgVoteResp from d975d9ebc69964b3 at term 3"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"d975d9ebc69964b3 became leader at term 3"}
{"level":"info","ts":"2022-12-21T10:29:00.740Z","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"raft.node: d975d9ebc69964b3 elected leader d975d9ebc69964b3 at term 3"}
{"level":"info","ts":"2022-12-21T10:29:00.742Z","caller":"etcdserver/server.go:2054","msg":"published local member to cluster through raft","local-member-id":"d975d9ebc69964b3","local-member-attributes":"{Name:k8s-master ClientURLs:[https://192.168.2.200:2379]}","request-path":"/0/members/d975d9ebc69964b3/attributes","cluster-id":"f88ac1c8c4bab6","publish-timeout":"7s"}
{"level":"info","ts":"2022-12-21T10:29:00.742Z","caller":"embed/serve.go:100","msg":"ready to serve client requests"}
{"level":"info","ts":"2022-12-21T10:29:00.742Z","caller":"embed/serve.go:100","msg":"ready to serve client requests"}
{"level":"info","ts":"2022-12-21T10:29:00.743Z","caller":"etcdmain/main.go:44","msg":"notifying init daemon"}
{"level":"info","ts":"2022-12-21T10:29:00.743Z","caller":"etcdmain/main.go:50","msg":"successfully notified init daemon"}
{"level":"info","ts":"2022-12-21T10:29:00.744Z","caller":"embed/serve.go:198","msg":"serving client traffic securely","address":"192.168.2.200:2379"}
{"level":"info","ts":"2022-12-21T10:29:00.745Z","caller":"embed/serve.go:198","msg":"serving client traffic securely","address":"127.0.0.1:2379"}
{"level":"info","ts":"2022-12-21T10:30:20.624Z","caller":"osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminated"}
{"level":"info","ts":"2022-12-21T10:30:20.624Z","caller":"embed/etcd.go:373","msg":"closing etcd server","name":"k8s-master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://192.168.2.200:2380"],"advertise-client-urls":["https://192.168.2.200:2379"]}
{"level":"info","ts":"2022-12-21T10:30:20.636Z","caller":"etcdserver/server.go:1465","msg":"skipped leadership transfer for single voting member cluster","local-member-id":"d975d9ebc69964b3","current-leader-member-id":"d975d9ebc69964b3"}
{"level":"info","ts":"2022-12-21T10:30:20.637Z","caller":"embed/etcd.go:568","msg":"stopping serving peer traffic","address":"192.168.2.200:2380"}
{"level":"info","ts":"2022-12-21T10:30:20.639Z","caller":"embed/etcd.go:573","msg":"stopped serving peer traffic","address":"192.168.2.200:2380"}
{"level":"info","ts":"2022-12-21T10:30:20.639Z","caller":"embed/etcd.go:375","msg":"closed etcd server","name":"k8s-master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://192.168.2.200:2380"],"advertise-client-urls":["https://192.168.2.200:2379"]}
|