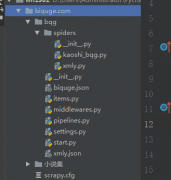
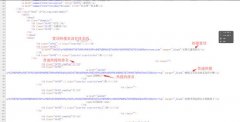
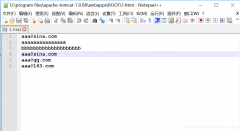
Windows系统下使用任务计划程序,Linux下可以使用crontab命令添加自启动计划。 这里写Windows 10 / windows Server 2016系统的设置方法。 首先编写一个.bat脚本。新建一个txt,将下面三行代码复制进去,main.py改成自己程序名字。保存为.bat文件,放在对应的
在爬虫百度地图的期间,就为它做了一个界面,运用的是PyQt5。 得到意想不到的结果: 代码如下: # -*- coding: utf-8 -*- # Form implementation generated from reading ui file E:\pycharm_workspase\sprider_baidumap\src\view\provinces.ui## Created by