
十个Claude实用的Token节省方案分享

十个 Claude实用的Token 节省方案 1、在已发送的消息上修改,而不是另发一条消息 当 AI 回答不符合我们的预期时,尽量不要发一条「不对,我是指」来跟进。 因为每发一条新消息,大模型都要
十个 Claude实用的Token 节省方案1、在已发送的消息上修改,而不是另发一条消息当 AI 回答不符合我们的预期时,尽量不要发一条「不对,我是指……」来跟进。 因为每发一条新消息,大模型都要把前面的所有聊天记录重新读一遍,导致 Token 消耗成倍翻滚。正确的做法是:直接点击原消息的「编辑」按钮,修改提示词,然后重新生成。
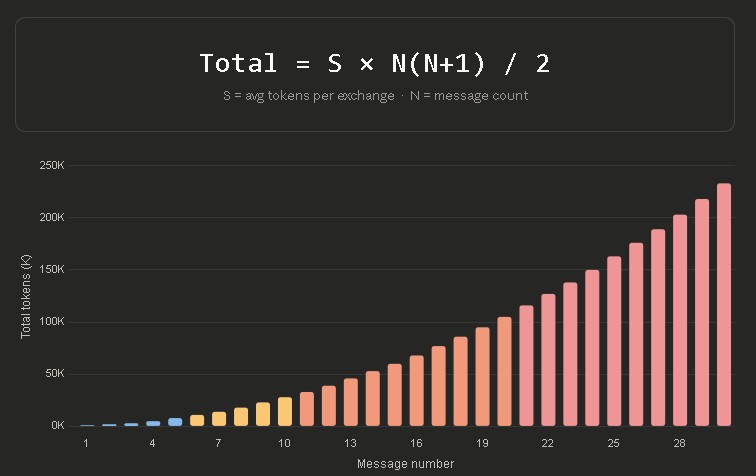
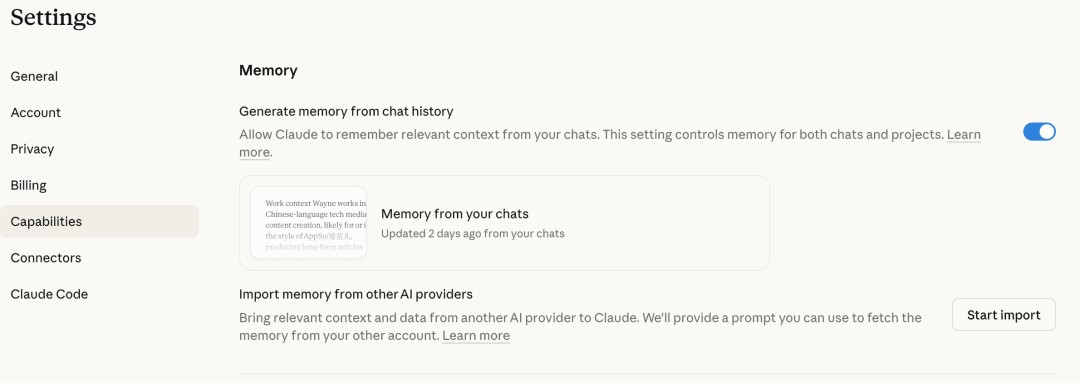
消息越多,消耗的 token 也越多。原文来源:https://x.com/0x_kaize/status/2038286026284667239 2、每 15–20 条消息就开启一个新对话长对话是 Token 的无底洞,在一百多条消息的对话中,可能有 98.5% 的 Token 都浪费在让 AI 重读历史记录上。 当对话变长时,我们可以让 AI 先总结一下当前进度,然后拿着这段总结去开一个新的对话。 3、将所有问题都集中到一个消息里面发送不要把「总结这篇文章」、「列出这篇文章的要点」、「给这篇文章想个标题」分成三条消息发送。 把它们合并成一段完整的提示词,不仅能减少系统加载上下文的次数,还能让 AI 因为看到了全貌而给出更高质量的回答。 4、把反复使用的文件上传到 Projects 中如果我们在多个聊天窗口里反复上传同一份长文档,每次上传都会重新消耗大量的 Token。 这个时候我们可以利用 Projects 的缓存功能,文件只需上传一次,后续在这个项目里怎么问关于这份文件的内容,都不会再重复烧 Token 了。 5、提前设置好「记忆」与用户偏好大多数时候,我们会按照以前的提示词技巧,在发每次开新对话时,都会「浪费额度」去写「现在你是一个文案策划,用轻松的语气写……」。
现在 AI 都有用户偏好和记忆功能,我们可以把职业、行文风格、项目信息等偏好保存在设置里,它就会自动生效,帮我们省下大量重复交代背景的 Token。 6、关掉不需要的附加功能联网搜索(Web search)和高级思考(Advanced Thinking)等功能只要开着,每一轮都会额外消耗 Token。 除非我们对初步的回答不满意,或者明确需要这些功能,平时在简单地聊天时,可以关闭这些附加功能。 7、用不同的模型解决不同的问题一些简单的任务,像检查语法、简单排版、快速翻译这些基础活,完全可以使用成本最低的 Haiku 模型。把节省下来 50%–70% 的额度,留给那些真正需要深度思考的复杂任务,交给 Sonnet 或 Opus。
8、把工作分散到全天的不同时段Claude 的使用限制是基于「滚动 5 小时」窗口来计算的,而不是半夜统一清零。 如果我们早上把额度耗光了,下午就会很难受。建议把工作分成早、中、晚几个时段,这样额度会不断自动恢复。 9、尽量避开高峰时段从 2026 年 3 月 26 日开始,如果在工作日的高峰期(太平洋时间早上 5 点到 11 点)使用,同样的请求会更快地消耗限额。如果把重度耗费算力的任务挪到非高峰期(比如晚上或周末),额度会经用得多。
这是基于 Claude 之前推出的错峰双倍福利,一方面是 Anthropic 的尖峰服务器压力大,给一些福利希望用户在平谷时候使用 Claude,另一方面也确实给北京时间的用户实实在在的优惠。 目前在 Cursor 等应用内使用大模型,有时候还是会碰到请求过多的提示,尤其是在晚上的时间。 10、开启超额使用 (Extra Usage)作为安全网如果是 Claude 付费用户,可以在设置里开启超额功能并设定预算上限。 这个方法虽然不省 Token,但可以保证当我们的额度耗尽时,系统会自动切换到按量计费,防止在十万火急的工作关头突然被强制阻断。 无论是靠 Skills 还是我们自己调整提示词,这些方案的底层逻辑都是要减少毫无意义的上下文重读。从千禧年按字算钱的短信,到如今按 Token 计费的大模型,人类追求沟通效率的本质其实从未改变。 在使用 AI 的过程中,逐渐养成这些习惯,用「山顶洞人」的语言,只说重点,把 Token 用在刀刃上,或许是这个 Token 堪比真金白银的时代,最顶级的提示词技巧。 |
您可能感兴趣的文章 :
- Claude Code效率翻倍的秘密武器:8大核心Skill介绍
- Claude Code最强代码清理神器code-simplifier的完全使用
- Claude Code CLI无缝切换Gemini 2.5 Pro实战介绍
- Claude Code Loop快速入门指南:从一行命令到自动迭代
- Claude Code中自动更新安装介绍
- Claude Code安装并切换DeepSeek大模型的操作方法
- Git Worktrees入门之Claude Code中多任务隔离方案
- 通过两个例子帮你快速理解什么是Token
- Claude Code Router实现一键接入多种AI模型的智能路由器
- OpenClaw从单机Docker部署迁移到Kubernetes集群的完整方案

-
Codex API网关迁移与流量优化的实战介绍
最近我将一个自建的 AI API 网关从旧服务器迁移到新服务器,期间遇到了一些典型的运维问题,包括: 数据库从 3.3GB 压缩到 30MB 日均流量从 -
Claude Code效率翻倍的秘密武器:8大核心Skill介绍
Claude Code 效率翻倍的秘密武器:8 大核心 Skill 详细解析 从设计智审到代码重构,一文看懂 Claude Code 最强的 8 个技能,让你的 AI 编程助手不 -
Claude Code最强代码清理神器code-simplifier的完全使用
Claude Code 最强代码清理神器:code-simplifier 完全使用指南 Anthropic 团队内部自用的代码简化 Agent,现已开源。不改变任何功能,只让你的代码 -

AI编程助手Codex + DeepSeek接入详细指南
为什么要用 Codex.app? Codex.app 是 OpenAI 出品的 AI 编程助手,对标 Cursor / Claude Code。选它的理由很简单: 原生 Responses API 不依赖 Chat Completio -
Qoder添加使用自定义模型deepseek,小米mimo,智普
1. 什么是 Qoder? Qoder 是一款面向专业开发者与现代技术团队的高效编程协作平台,它将智能代码辅助、项目管理与实时协同编辑深度融合, -
Gemini CLI中使用Gemini3.0的方法
最近Gemini 3.0想当火爆,但是墙内使用存在各种阻碍,今天教大家无需魔法免费白嫖.在Gemini CLI中用上Gemini 3.0. 安装 Gemini CLI 安装教程网上很多 -
Claude Code CLI无缝切换Gemini 2.5 Pro实战介绍
1. 项目概述:为什么这个方案值得你花一小时认真读完 Claude Code(CC)这东西,用过的人心里都有数它不是能写代码,而是像一个坐在我工位 -
Gemini CLI 自定义命令的妙用
1. 前言 Gemini CLI 是 Google 推出的一个命令行工具,可以让你通过命令行与 Gemini 模型进行交互。 现在,我的很多编程场景都在使用 Gemini CLI -
Codex不听话?一文带你搞懂5大Codex的核心概念
Codex 核心概念:Agent、Sandbox、Approval、AGENTS.md、Memory 与 Chronicle 本文主要面向刚开始使用 Codex 的开发者。本文不讲安装流程,重点解释几个



-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
Claude Code配置Skills的三种方法
2026-05-31

