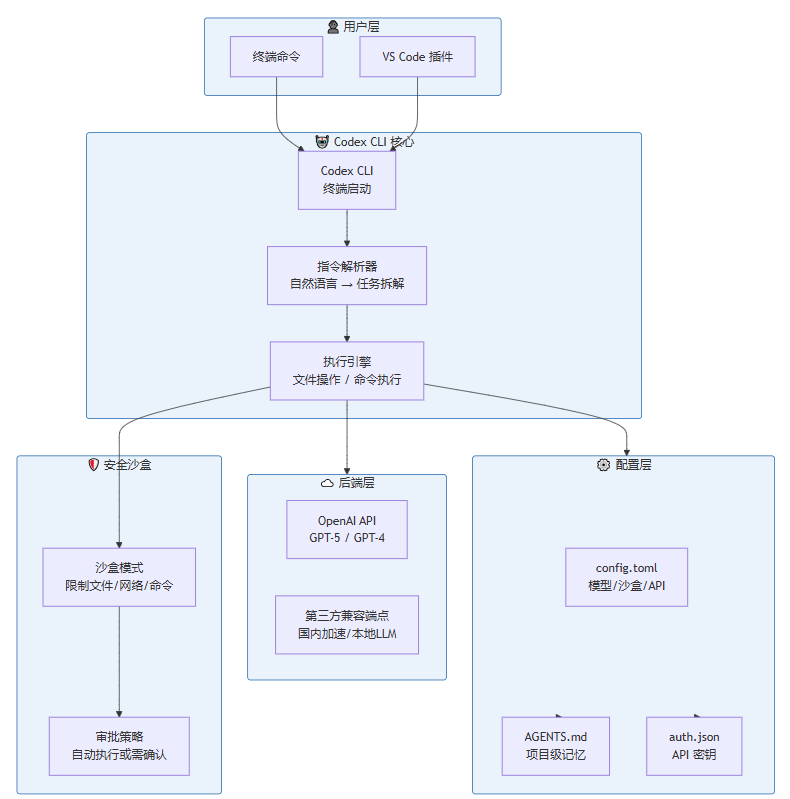
Claude Code 修改文件的方式不是传行号,也不是打 AST patch。它让模型输出一段要替换的原文 old_string 和替换后的文本 new_string,由 Edit 工具完成实际写入。
这个接口看起来简单——告诉工具"把这段文字换成那段文字"就行了。但真正要把它做稳定,需要回答两个问题:
- 模型看到的文件内容和执行编辑时的文件内容之间存在时间差。如果文件在这段时间里被改了,怎么办?
- 模型输出的文本和文件里的真实文本不完全一样,怎么办?
下面先看 Edit 的基本结构,然后围绕这两个问题展开。
Edit 工具的基本实现
Edit 通过 buildTool 注册为一个可被模型调用的工具。核心接口包括三部分:给模型看的 Prompt、约束参数的 schema、以及真正执行替换的 call。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
export const FileEditTool = buildTool({ name: FILE_EDIT_TOOL_NAME,
async prompt() { return getEditToolDescription(); },
get inputSchema() { return z.strictObject({ file_path: z.string().describe('The absolute path to the file to modify'), old_string: z.string().describe('The text to replace'), new_string: z.string().describe('The text to replace it with'), replace_all: semanticBoolean(z.boolean().default(false).optional()), }); },
async call(input, context, _, parentMessage) { const { file_path, old_string, new_string, replace_all = false } = input; const fileContent = readTextContent(file_path);
const updatedFile = replace_all ? fileContent.replaceAll(old_string, new_string) : fileContent.replace(old_string, new_string);
writeTextContent(file_path, updatedFile); return { updatedFile }; }, }); |
四个参数的语义:
| 字段 | 含义 |
|---|---|
| file_path | 要修改的文件绝对路径 |
| old_string | 要被替换的原文 |
| new_string | 替换后的文本 |
| replace_all | 是否替换所有匹配项,默认 false |
call 的逻辑很直接:读文件、找 old_string、替换成 new_string、写回磁盘。但 inputSchema 只能约束字段形状,不能告诉模型怎么写参数。所以同一个工具定义里还有 Prompt,把调用规则写清楚:先读文件、保留缩进、默认要求 old_string 唯一、需要全局替换时再使用 replace_all。
|
1 2 3 4 5 6 7 8 9 |
function getEditToolDescription(): string { return `Performs exact string replacements in files.
Usage: - You must use your \`Read\` tool at least once in the conversation before editing. - When editing text from Read tool output, ensure you preserve the exact indentation. - The edit will FAIL if \`old_string\` is not unique in the file. - Use \`replace_all\` for replacing and renaming strings across the file.`; } |
这个最小版本能工作,但它默认了两件事:文件不会在读写之间被改,模型输出的文本一定能和文件内容精确匹配。真实环境里,这两个默认都不成立。
文件在生成过程中被改了怎么办
模型读文件和实际执行编辑之间存在时间窗口。在这个窗口里,用户可能手动改了代码,linter 可能自动格式化了文件,编辑器可能保存了新的内容。如果 Edit 工具不做任何检查,它会基于过时的文件内容执行替换,把用户或 linter 的改动覆盖掉。
readFileState:记住每个文件的最后读取状态
Edit 工具用一个 LRU 缓存 readFileState 跟踪每个文件的最后读取状态:
|
1 2 3 4 5 6 7 |
type FileState = { content: string; // 读取时的文件内容 timestamp: number; // Math.floor(mtimeMs) offset: number | undefined; // 读取范围起始(全文读取时为 undefined) limit: number | undefined; // 读取范围长度(全文读取时为 undefined) isPartialView?: boolean; // 自动注入的内容与磁盘不一致时为 true }; |
Read 工具读取文件后会写入这个缓存,Edit 工具写入成功后也会更新它。这个缓存是后续所有过期检测的基础。
第一道防线:validateInput 执行前检查
validateInput 在编辑执行之前运行,不写文件,只判断这次编辑是否满足安全执行条件。它同时检查两个问题:
- 文件有没有被改过
- old_string 能不能匹配上。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
async function validateInput(input, toolUseContext) { const { file_path, old_string, replace_all } = input; const fullFilePath = expandPath(file_path); const fileContent = readCurrentTextFile(fullFilePath);
// 1. 文件必须被读过(不能编辑模型没见过的文件) const readTimestamp = toolUseContext.readFileState.get(fullFilePath); if (!readTimestamp || readTimestamp.isPartialView) { return { result: false, message: 'File has not been read yet.', errorCode: 6, }; }
// 2. 文件自读取后不能被改过 const lastWriteTime = getFileModificationTime(fullFilePath); if (lastWriteTime > readTimestamp.timestamp) { const isFullRead = readTimestamp.offset === undefined && readTimestamp.limit === undefined; const contentUnchanged = isFullRead && fileContent === readTimestamp.content; if (!contentUnchanged) { return { result: false, message: 'File has been modified since read.', errorCode: 7, }; } }
// 3. old_string 必须能匹配到文件内容 const actualOldString = findActualString(fileContent, old_string); if (!actualOldString) { return { result: false, message: 'String to replace not found in file.', errorCode: 8, }; }
// 4. 默认只允许唯一匹配 const matches = fileContent.split(actualOldString).length - 1; if (matches > 1 && !replace_all) { return { result: false, message: `Found ${matches} matches.`, errorCode: 9, }; } } |
前两步检查文件是否被改过。有几个细节值得注意:
- 时间戳比较用的是 Math.floor(mtimeMs),去掉亚毫秒精度,减少时间戳抖动造成的误报。
- Windows 上云同步、杀毒软件等可能只改时间戳不改内容。所以即使时间戳变了,如果文件是完整读取的且内容没变,仍然允许编辑。
- isPartialView 标记自动注入的内容(如 CLAUDE.md)与磁盘文件不一致的情况,强制用户先 Read 再编辑。
第三步检查 old_string 能不能匹配上——这里用的 findActualString 会先试精确匹配,失败后把弯引号转成直引号再试,因为 Claude 只能输出直引号但文件里可能用弯引号。 如果引号规范化后仍然匹配不到,直接拒绝。匹配成功后返回的是原始文件里的实际文本,后续替换用真实字符。如果文件用的是弯引号,preserveQuoteStyle 会把 new_string 里的直引号转回弯引号,保持风格一致。
四步检查,每一步失败都有明确的错误码和错误消息,模型可以根据错误信息决定下一步行动:
| 错误码 | 含义 | 模型的下一步 |
|---|---|---|
| 6 | 文件没读过 | 先 Read 文件 |
| 7 | 文件被改过了 | 重新 Read 文件 |
| 8 | old_string 找不到 | 换更准确的 old_string |
| 9 | 匹配到多处 | 扩大上下文或使用 replace_all |
第二道防线:call 写入前再检查一次
validateInput 通过不代表文件就安全了。校验通过到真正写入之间仍然有时间窗口。所以 call 在写入前会重新读取文件并再次检查:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
async function call(input, { readFileState }) { const { file_path, old_string, new_string, replace_all } = input; const absoluteFilePath = expandPath(file_path);
// 重新读取磁盘上的当前内容 const { content: originalFileContents, encoding, lineEndings, } = readFileForEdit(absoluteFilePath);
// 写入前再次做过期检测 const lastRead = readFileState.get(absoluteFilePath); const lastWriteTime = getFileModificationTime(absoluteFilePath); if (!lastRead || lastWriteTime > lastRead.timestamp) { const isFullRead = lastRead?.offset === undefined && lastRead?.limit === undefined; const contentUnchanged = isFullRead && originalFileContents === lastRead.content; if (!contentUnchanged) { // 'File has been unexpectedly modified. Read it again before attempting to write it.' throw new Error(FILE_UNEXPECTEDLY_MODIFIED_ERROR); } }
// 执行替换并写入... } |
call 把文件读取、过期检查、替换计算、磁盘写入放在一个同步段里,不允许任何异步操作插入到检查和写入之间。目录创建、文件历史备份等需要 await 的步骤全部安排在这个段之前完成。 检查通过之后如果让出事件循环(比如 await 一个异步操作),别的代码就有机会在这段时间里修改文件,第二道防线就白做了。
为什么只有第一道防线不够?
因为 validateInput 和 call 之间不是连续执行的。validateInput 返回通过之后,运行时还要做权限检查、等待用户确认、执行 hook 等操作,这些步骤可能耗时数百毫秒甚至更长。在这个窗口里,用户的编辑器可能自动保存了文件,linter 可能格式化了代码,甚至另一个 Claude Code 会话可能刚刚写入了同一个文件。如果只靠 validateInput 的检查结果就直接写入,这些并发修改会被静默覆盖。第二道防线的意义在于:真正写入之前,用同步读取拿到最新的文件内容,再做一次判断——文件变了就拒绝,没变才写入。
写入后更新 readFileState
编辑成功后,call 会更新 readFileState,把文件内容和时间戳设为写入后的值:
|
1 2 3 4 |
readFileState.set(absoluteFilePath, { content: updatedFile, timestamp: getFileModificationTime(absoluteFilePath), }); |
这一步容易被忽略,但很关键:如果不更新,下一次连续编辑会把自己刚写入的文件误判为"外部修改",导致所有连续编辑都失败。
文件历史:最后一道恢复线
即使所有检查都通过了,写入仍然可能不是用户期望的。Edit 工具在真正写入之前会调用文件历史机制备份编辑前的内容:
|
1 |
await fileHistoryTrackEdit(absoluteFilePath); |
备份使用 fs.copyFile() 而不是把文件读内存,存储在 ~/.claude/file-history/ 下。这不是校验机制的一部分,而是恢复机制:前面尽量避免错误写入,后面仍然保留回滚能力。
小结
| 阶段 | 检查 | 失败行为 |
|---|---|---|
| 执行前 | validateInput 检查 mtime、匹配和唯一性 | 拒绝编辑,返回对应错误码 |
| 写入前 | call 重新读取文件并再次比较 mtime | 抛出 FILE_UNEXPECTEDLY_MODIFIED_ERROR |
| 写入后 | 更新 readFileState | 后续编辑基于新内容继续 |
| 写入前(备份) | fileHistoryTrackEdit 备份原文件 | 保留恢复能力 |
总结
Edit 工具的实现揭示了一个更一般的道理:写一个让 LLM 使用的工具,不能信任模型的输出,也要考虑环境的变化,最终靠验证来保证正确性。
不能信任模型的输出,因为模型天然不稳定。它可能记错文件内容,可能输出和原文不完全一致的文本,可能在不该加空格的地方加了空格。Prompt 可以引导它,但无法保证它每次都对。
要考虑环境的变化,因为模型读取文件和执行工具之间存在时间差。在这个窗口里,用户可能改了代码,linter 可能格式化了文件,甚至另一个会话可能刚刚写入了同一个文件。工具执行的时候,世界已经不是模型看到的样子了。工具必须意识到这一点,在关键操作前重新确认环境状态。
最终靠验证来保证正确性。工具层拿到模型的输出后,可以检查文件是否被改过,可以规范化文本后再匹配,可以在写入前再读一次最新内容。能确认安全的,执行;不能确认的,拒绝。已经完成的写入,更新状态并保留恢复入口。
Edit 工具的每一层机制——readFileState 跟踪、mtime 检查、引号规范化、二次读取、文件历史备份——都是这个原则的具体体现。不是让模型永远不犯错,而是在模型输出不可靠、环境随时可能变化的前提下,通过验证保证最终结果的正确性。