一、先搞清楚一件事:为什么会有这些概念?
大语言模型(LLM)本身是一个"有知识但没手脚"的东西。你给它一段 Prompt,它返回一段文本——仅此而已。
但真实的业务场景远比"一问一答"复杂得多:
- 你希望 AI 能自主完成多步骤任务,比如"帮我查一下线上报错,定位到代码,然后提交修复" → 这就需要 Agent
- 你希望 AI 的回答能基于你的私有数据,而不是胡编乱造 → 这就需要 RAG
- 你希望 AI 具备特定领域的标准化能力,可以复用、可以分享 → 这就需要 Skill
- 你希望 AI 能调用外部工具和服务,并且有一个统一的协议标准 → 这就需要 MCP
这四个概念不是互相替代的关系,而是互补的,分别解决 AI 工程化落地中的不同层面的问题。
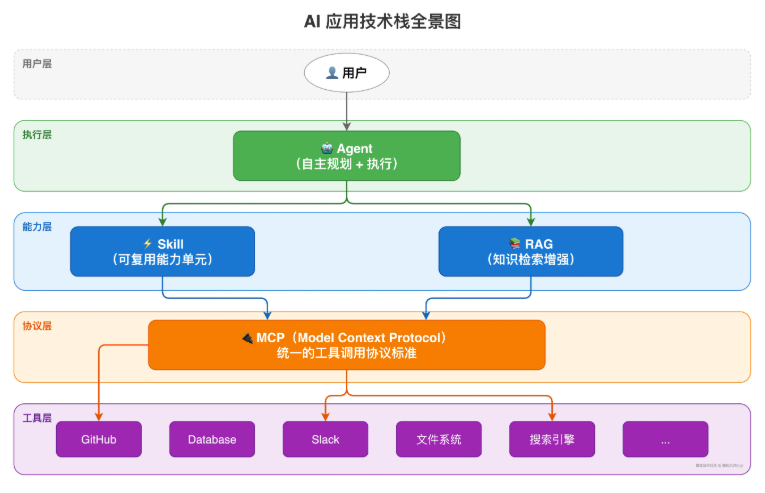
图1 展示了四个概念在 AI 应用技术栈中的定位。Agent 是最上层的"执行者",RAG 为其提供知识支撑,Skill 是可复用的能力单元,MCP 是连接外部世界的标准协议。
二、Agent:让 AI 从"应答机器"变成"自主员工"
2.1 一句话定义
Agent = LLM + 规划能力 + 记忆 + 工具调用。它不只是回答问题,而是能理解目标、拆解任务、调用工具、根据反馈调整行动,直到任务完成。
2.2 跟普通 LLM 调用有什么区别?
先看一个对比:
| 维度 | 普通 LLM 调用 | Agent |
|---|---|---|
| 交互模式 | 单轮问答,你问我答 | 多轮自主执行,目标驱动 |
| 任务拆解 | 不具备,需要人工拆解 | 自动将复杂任务分解为子任务 |
| 工具使用 | 不支持(纯文本生成) | 可调用搜索引擎、数据库、API 等 |
| 记忆能力 | 仅限当前上下文窗口 | 具备短期记忆和长期记忆 |
| 错误处理 | 无法自我纠正 | 能根据执行结果调整策略 |
| 执行模式 | 同步、一次性 | 异步、持续循环直到完成 |
举个实际的例子:你对一个普通的 ChatBot 说"帮我排查线上 OOM 问题",它只能给你一些通用的排查思路。但如果是一个 Agent,它可能会:
- 调用日志服务查询最近的 OOM 堆栈
- 分析堆栈信息定位到具体的代码路径
- 读取对应的源码文件
- 查询该服务最近的代码变更记录
- 结合以上信息给出根因分析和修复建议
整个过程中,每一步的输出会作为下一步的输入,Agent 自己决定下一步做什么。
2.3 Agent 的核心架构
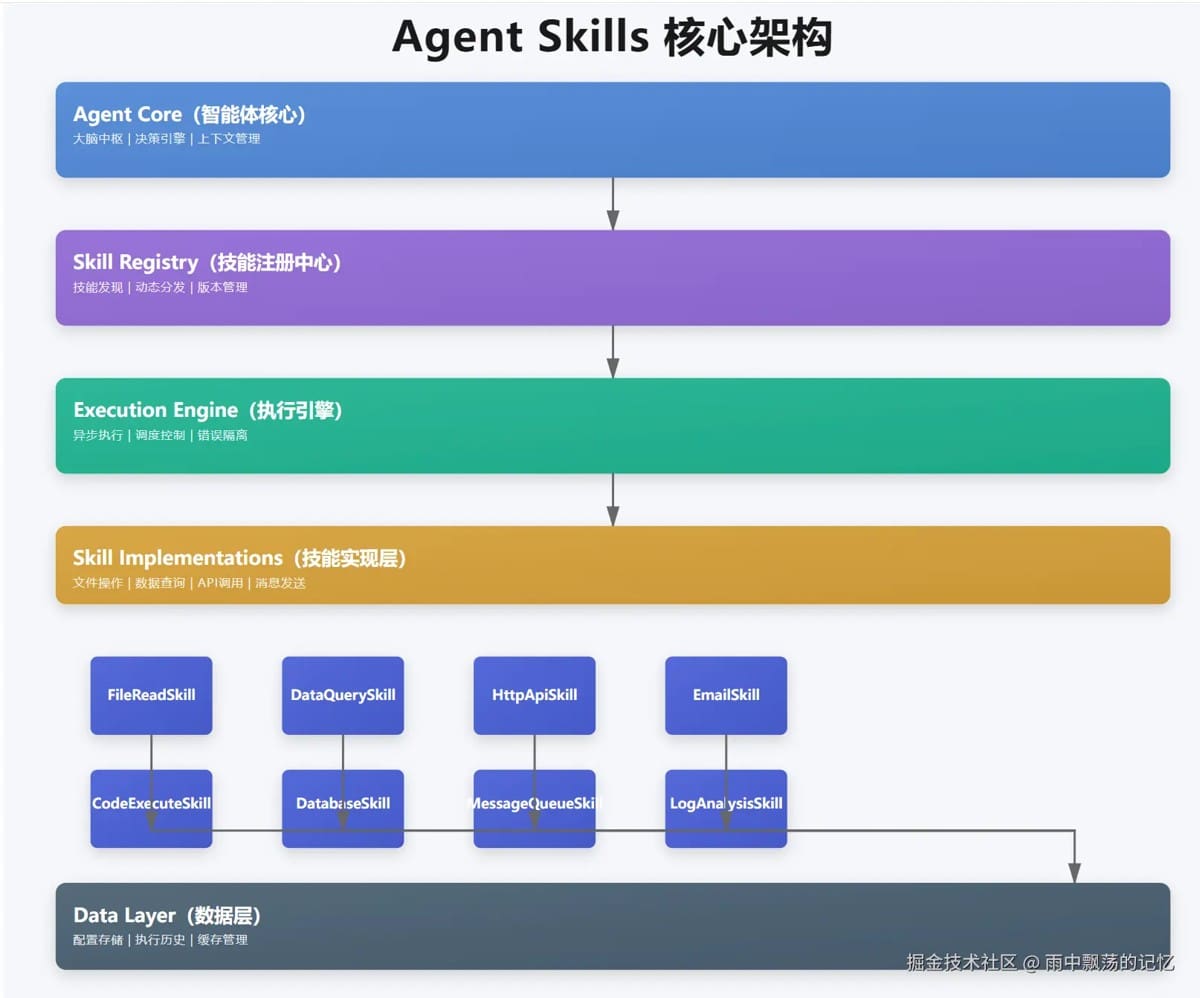
一个完整的 Agent 通常包含四个核心模块:
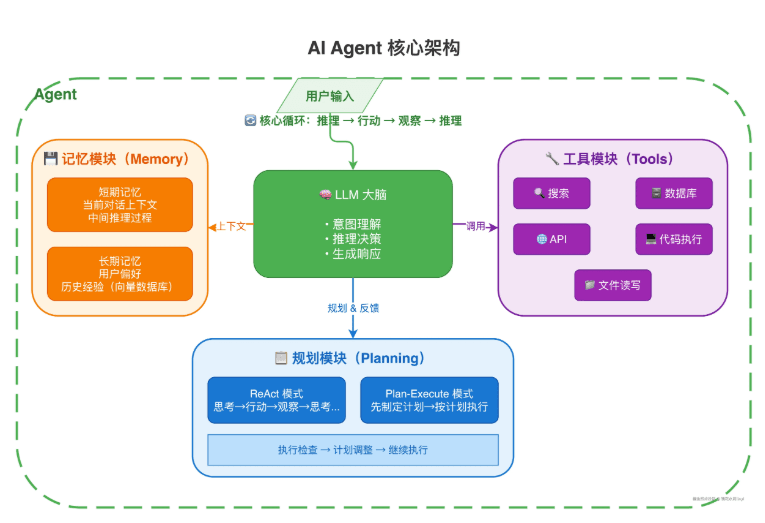
图2 展示了 Agent 的四大核心模块。LLM 作为"大脑"负责推理和决策;规划模块负责任务拆解和执行策略;记忆模块提供上下文管理;工具模块提供与外部世界交互的能力。
(1)LLM 大脑(Reasoning & Decision)
Agent 的核心是一个大语言模型,负责:
- 理解用户意图
- 推理和决策
- 生成工具调用指令
- 分析工具返回的结果
(2)规划模块(Planning)
负责将复杂任务拆解为可执行的步骤序列。常见的规划策略有两种:
ReAct(Reasoning + Acting)模式:交替进行"思考"和"行动",每一步都基于前一步的结果来决定下一步。
|
1 2 3 4 5 6 7 8 |
Thought: 用户想排查 OOM 问题,我需要先查看日志 Action: 调用 SLS 日志查询工具,搜索最近 1 小时的 OOM 日志 Observation: 找到 3 条 OOM 记录,堆栈指向 UserService.batchQuery() Thought: 定位到了具体方法,我需要看看这个方法的代码 Action: 读取 UserService.java 文件 Observation: batchQuery() 方法中有一个未分页的全量查询 Thought: 找到根因了——全量查询导致内存溢出 Action: 输出分析报告和修复建议 |
Plan-and-Execute 模式:先制定完整计划,然后按计划逐步执行。适合任务步骤比较确定的场景。
|
1 2 3 4 5 6 7 8 9 |
Plan: Step 1: 查询 OOM 日志 Step 2: 分析堆栈定位代码 Step 3: 读取相关源码 Step 4: 查询最近代码变更 Step 5: 生成分析报告
Execute: [按计划逐步执行,每步完成后检查是否需要调整计划] |
(3)记忆模块(Memory)
Agent 需要记住"自己干过什么"和"知道些什么":
- 短期记忆(Working Memory):当前对话的上下文,包括用户输入、中间推理过程、工具调用结果。受限于 LLM 的上下文窗口长度。
- 长期记忆(Long-term Memory):跨会话持久化的信息,通常存储在向量数据库中。比如用户的偏好、历史交互中学到的经验。
(4)工具模块(Tools)
Agent 的"手和脚"。通过工具,Agent 可以:
- 搜索互联网
- 查询数据库
- 调用 REST API
- 读写文件
- 执行代码
工具的定义通常包含名称、描述、参数 Schema。LLM 根据工具描述来决定何时调用哪个工具。
2.4 用代码感受一下
以下是一个简化的 Agent 循环,用 Python 伪代码展示核心逻辑:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
class Agent: def __init__(self, llm, tools, memory): self.llm = llm self.tools = tools # 可用工具列表 self.memory = memory # 记忆模块
def run(self, user_task: str) -> str: """Agent 的核心执行循环""" self.memory.add("user", user_task)
max_iterations = 10 # 防止无限循环 for i in range(max_iterations): # 1. LLM 根据当前上下文进行推理 response = self.llm.chat( messages=self.memory.get_messages(), tools=self.tools.get_schemas() # 告诉 LLM 有哪些工具可用 )
# 2. 如果 LLM 决定调用工具 if response.has_tool_call(): tool_name = response.tool_call.name tool_args = response.tool_call.arguments
# 3. 执行工具调用 result = self.tools.execute(tool_name, tool_args)
# 4. 将工具结果加入记忆,供下一轮推理使用 self.memory.add("tool_result", result) continue
# 5. 如果 LLM 认为任务已完成,直接返回结果 if response.is_final_answer(): return response.content
return "达到最大执行次数,任务未能完成" |
这段代码揭示了 Agent 的本质:一个由 LLM 驱动的循环。每一轮循环中,LLM 根据当前的上下文(记忆)决定下一步行动——要么调用工具获取更多信息,要么给出最终答案。
2.5 Agent 的技术挑战
Agent 听起来很美好,但工程落地时有几个绕不开的挑战:
可靠性问题:LLM 的输出具有随机性,Agent 可能走错路、调错工具、陷入死循环。生产环境中需要加入超时控制、异常兜底、人工审批等机制。
成本控制:Agent 的每一步推理都是一次 LLM 调用,复杂任务可能需要 10-20 次调用,Token 消耗和延迟都需要关注。
工具设计:工具的描述直接影响 LLM 能否正确选择和使用工具。描述写得不好,Agent 的表现会大打折扣。
安全边界:Agent 能执行操作意味着它也能"搞破坏"。权限控制、操作审计、沙箱隔离都是必须考虑的。
三、RAG:让 AI 说的每句话都有据可查
3.1 一句话定义
RAG(Retrieval-Augmented Generation)= 检索增强生成。核心思路是:先从知识库中检索相关文档,再把检索到的内容作为上下文喂给 LLM,让它基于这些"证据"来生成回答。
3.2 为什么需要 RAG?
LLM 有三个固有的局限性,RAG 正好可以弥补:
| LLM 的局限 | 具体表现 | RAG 如何解决 |
|---|---|---|
| 知识截止 | 训练数据有时间截止点,不知道最新信息 | 从实时更新的知识库中检索最新内容 |
| 幻觉问题 | 会一本正经地编造不存在的事实 | 基于检索到的真实文档生成,可溯源 |
| 缺乏私有知识 | 不了解你的公司文档、代码库、业务数据 | 将私有数据索引到知识库中 |
一个直观的例子:你问 LLM"我们公司的请假审批流程是什么?",LLM 只能瞎编。但如果用 RAG,系统会先从公司的规章制度文档中检索相关段落,然后 LLM 基于这些段落来回答——回答既准确又可以标注出处。
3.3 RAG 的完整工作流程
RAG 分为两个阶段:离线索引和在线检索生成。
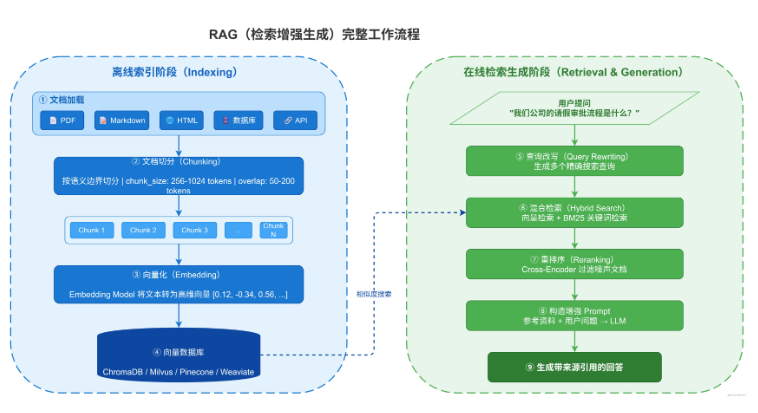
图3 展示了 RAG 的完整工作流程。左侧是离线索引阶段,负责将文档处理并存入向量数据库;右侧是在线检索生成阶段,负责根据用户查询检索相关文档并生成回答。
阶段一:离线索引(Indexing)
这个阶段的目标是把原始文档转换成可高效检索的格式,存入向量数据库。
Step 1:文档加载(Loading)
从各种数据源加载原始文档:PDF、Word、Markdown、HTML、数据库记录、API 返回等。
Step 2:文档切分(Chunking)
原始文档通常很长,需要切分成适当大小的片段(Chunk)。这是 RAG 效果的关键环节之一。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 常见的切分策略 class ChunkingStrategy: """文档切分策略"""
@staticmethod def fixed_size(text: str, chunk_size=512, overlap=50) -> list: """固定大小切分 —— 简单但可能切断语义""" chunks = [] for i in range(0, len(text), chunk_size - overlap): chunks.append(text[i:i + chunk_size]) return chunks
@staticmethod def semantic_split(text: str) -> list: """语义切分 —— 按段落、章节等自然边界切分""" # 优先按标题、段落切分,保持语义完整性 sections = split_by_headers(text) chunks = [] for section in sections: if len(section) > MAX_CHUNK_SIZE: # 超长段落再按句子切分 chunks.extend(split_by_sentences(section)) else: chunks.append(section) return chunks |
切分时的几个关键参数:
- chunk_size:每个块的大小。太大会引入噪声,太小会丢失上下文。通常 256-1024 Token 之间。
- overlap:相邻块的重叠部分。确保切分边界处的信息不会丢失。通常 50-200 Token。
- 切分策略:按固定大小、按语义(段落/句子)、按文档结构(标题/章节)。实践中语义切分效果更好。
Step 3:向量化(Embedding)
使用 Embedding 模型将每个文本块转换为高维向量。语义相近的文本在向量空间中距离也相近。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from openai import OpenAI
client = OpenAI()
def embed_chunks(chunks: list[str]) -> list[list[float]]: """将文本块批量转换为向量""" response = client.embeddings.create( model="text-embedding-3-small", # OpenAI 的 Embedding 模型 input=chunks ) # 返回每个 chunk 对应的向量(1536 维) return [item.embedding for item in response.data] |
常用的 Embedding 模型对比:
| 模型 | 维度 | 特点 |
|---|---|---|
| OpenAI text-embedding-3-small | 1536 | 性价比高,英文效果好 |
| OpenAI text-embedding-3-large | 3072 | 精度更高,成本也更高 |
| BGE-large-zh | 1024 | 中文效果好,可本地部署 |
| M3E-base | 768 | 轻量级,适合中文场景 |
Step 4:存入向量数据库
将向量和原始文本一起存入向量数据库,建立索引。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import chromadb
# 初始化向量数据库(以 ChromaDB 为例) client = chromadb.Client() collection = client.create_collection("company_docs")
# 存入文档块及其向量 collection.add( ids=[f"chunk_{i}" for i in range(len(chunks))], documents=chunks, # 原始文本 embeddings=embed_chunks(chunks), # 向量 metadatas=[{ # 元数据(用于过滤) "source": "employee_handbook.pdf", "chapter": "leave_policy", "updated_at": "2025-03-01" } for _ in chunks] ) |
阶段二:在线检索生成(Retrieval & Generation)
用户提问时,实时检索相关文档并生成回答。
Step 1:查询向量化
将用户的查询文本也转换为向量。
Step 2:向量检索(Retrieval)
在向量数据库中找到与查询向量最相似的 Top-K 个文档块。
|
1 2 3 4 5 6 7 8 9 10 |
def retrieve(query: str, top_k=5) -> list[str]: """检索与查询最相关的文档块""" query_embedding = embed_chunks([query])[0]
results = collection.query( query_embeddings=[query_embedding], n_results=top_k, where={"updated_at": {"$gte": "2025-01-01"}} # 可选:元数据过滤 ) return results["documents"][0] |
Step 3:构造增强 Prompt
将检索到的文档块拼接到 Prompt 中,作为 LLM 的参考资料。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def generate_answer(query: str, retrieved_docs: list[str]) -> str: """基于检索结果生成回答""" context = "\n\n---\n\n".join(retrieved_docs)
prompt = f"""基于以下参考资料回答用户的问题。 如果参考资料中没有相关信息,请明确说明"根据现有资料无法回答"。 请在回答中标注信息来源。
## 参考资料 {context}
## 用户问题 {query}
## 回答"""
response = client.chat.completions.create( model="gpt-4", messages=[{"role": "user", "content": prompt}] ) return response.choices[0].message.content |
Step 4:返回带来源的回答
回答中附带引用的文档来源,方便用户验证。
3.4 RAG 进阶:不只是"检索 + 生成"
基础版 RAG 的效果往往不够理想,实际工程中需要多种优化手段:
(1)查询改写(Query Rewriting)
用户的原始查询可能表述模糊,直接拿去检索效果不好。可以用 LLM 先改写查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def rewrite_query(original_query: str) -> list[str]: """将原始查询改写为多个更精确的检索查询""" prompt = f"""请将以下查询改写为 3 个更具体的搜索查询,以提高检索效果:
原始查询:{original_query}
改写后的查询(每行一个):"""
# 例如 "请假怎么操作" 会被改写为: # 1. "员工请假审批流程步骤" # 2. "年假事假病假申请方式" # 3. "OA系统请假操作指南" ... |
(2)混合检索(Hybrid Search)
单纯的向量检索在精确匹配(如搜错误码、方法名)时效果不佳。混合检索结合了向量检索和关键词检索:
|
1 2 3 4 5 6 7 8 9 10 11 |
def hybrid_search(query: str, top_k=5) -> list[str]: """混合检索:向量相似度 + BM25 关键词匹配""" # 向量检索结果 vector_results = vector_search(query, top_k=top_k)
# 关键词检索结果(BM25 算法) keyword_results = bm25_search(query, top_k=top_k)
# 用 RRF(Reciprocal Rank Fusion)融合两路结果 merged = reciprocal_rank_fusion(vector_results, keyword_results) return merged[:top_k] |
(3)重排序(Reranking)
检索出的文档不一定都相关。使用 Cross-Encoder 模型对检索结果重新排序,过滤掉噪声文档:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank(query: str, documents: list[str], top_k=3) -> list[str]: """使用 Cross-Encoder 对检索结果重排序""" pairs = [(query, doc) for doc in documents] scores = reranker.predict(pairs)
# 按相关性分数排序,只保留 top_k ranked = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True) return [doc for doc, score in ranked[:top_k] if score > 0.5] # 过滤低分文档 |
3.5 RAG vs. 微调:什么时候该用哪个?
这是一个高频问题,简单总结:
| 维度 | RAG | 微调(Fine-tuning) |
|---|---|---|
| 知识更新 | 实时更新,修改文档即可 | 需要重新训练模型 |
| 实现成本 | 较低,不需要 GPU | 较高,需要训练资源 |
| 幻觉控制 | 好,回答可溯源 | 较差,可能过拟合 |
| 适用场景 | 知识密集型问答、文档检索 | 风格适配、特定任务格式 |
| 数据量要求 | 无明确下限 | 通常需要千级以上样本 |
| 响应延迟 | 多一步检索,略慢 | 与基础模型相同 |
一句话建议:如果你的需求是"让 AI 知道更多东西",用 RAG;如果你的需求是"让 AI 用特定方式说话或做事",用微调;如果两者都需要,可以 RAG + 微调一起上。
四、Skill:给 AI 装上"可插拔的专业技能"
4.1 一句话定义
Skill = 预定义的、可复用的 AI 能力单元。它封装了特定任务的 Prompt 模板、工具组合、执行流程,使 AI 在某个领域的表现从"泛泛而谈"变成"专业精准"。
4.2 为什么需要 Skill?
直接跟 LLM 对话完成任务有一个很大的问题:不稳定。
同一个任务,不同的 Prompt 写法、不同的对话上下文、甚至不同的时间点,LLM 给出的结果质量都可能差异很大。在生产环境中,这种不确定性是不可接受的。
Skill 的价值在于将最佳实践固化下来:
- 精心调试过的 Prompt 模板 → 保证输出质量和格式的稳定性
- 预绑定的工具集合 → 确保 AI 用对工具
- 明确的输入输出规范 → 像调用 API 一样可预期
- 可独立测试和迭代 → 不影响其他能力
用一个类比来理解:如果 Agent 是一个"全能员工",那 Skill 就是这个员工掌握的"标准作业流程(SOP)"。员工再聪明,没有 SOP 也容易出错;有了 SOP,新手也能高效执行。
4.3 Skill 的结构解剖
一个典型的 Skill 由以下部分组成:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# 一个 Skill 的结构描述(以代码审查 Skill 为例) name: "code-review" description: "对代码变更进行安全性、性能、可维护性审查" version: "1.2.0"
# 触发条件:什么时候激活这个 Skill triggers: - "review this code" - "代码审查" - "帮我 review"
# 输入参数定义 inputs: - name: "code_diff" type: "string" required: true description: "需要审查的代码变更(diff 格式)" - name: "language" type: "string" required: false default: "auto-detect" - name: "focus_areas" type: "list" required: false default: ["security", "performance", "maintainability"]
# Prompt 模板(核心) prompt_template: | 你是一位资深的 {{language}} 代码审查专家。 请对以下代码变更进行审查,重点关注:{{focus_areas}}
## 审查标准 1. 安全性:是否存在注入、XSS、敏感信息泄露等风险 2. 性能:是否有 N+1 查询、内存泄漏、不必要的循环 3. 可维护性:命名是否清晰、是否符合项目规范
## 代码变更 {{code_diff}}
## 输出格式 按严重程度(Critical/Warning/Info)分类列出问题, 每个问题给出具体的行号、问题描述和修复建议。
# 绑定的工具 tools: - "file_reader" # 读取完整文件上下文 - "git_log" # 查看变更历史 - "grep" # 搜索相关代码
# 输出格式定义 output_format: type: "structured" schema: issues: list[{severity, line, description, suggestion}] summary: string approval: boolean |
4.4 Skill 与 Plugin / Function Calling 的区别
这三个概念经常被混淆,澄清一下:
| 维度 | Skill | Plugin | Function Calling |
|---|---|---|---|
| 粒度 | 完整的任务流程 | 单个工具或服务的封装 | 单次函数调用 |
| 包含内容 | Prompt + 工具 + 流程 + 约束 | 工具定义 + API 接口 | 函数签名 + 参数 |
| 智能程度 | 高,内置领域知识和最佳实践 | 低,只是工具的壳 | 无,只是调用机制 |
| 类比 | 一套完整的 SOP | 一把螺丝刀 | 拧螺丝这个动作 |
换句话说:Function Calling 是最底层的调用机制,Plugin 是对工具的封装,Skill 是在 Plugin 之上加入了领域知识和执行策略的完整能力单元。
4.5 Skill 在 Agent 中的应用
在 Agent 架构中,Skill 通常作为 Agent 的"能力模块"被组装进来:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
class SkillBasedAgent: """基于 Skill 的 Agent"""
def __init__(self, llm): self.llm = llm self.skills = {} # 已注册的 Skills
def register_skill(self, skill: Skill): """注册一个 Skill""" self.skills[skill.name] = skill
def run(self, user_input: str) -> str: # 1. 意图识别:判断应该使用哪个 Skill matched_skill = self.match_skill(user_input)
if matched_skill: # 2. 提取 Skill 所需的参数 params = matched_skill.extract_params(user_input) # 3. 使用 Skill 的专业 Prompt 和工具来执行 return matched_skill.execute(self.llm, params) else: # 4. 没有匹配的 Skill,走通用对话 return self.llm.chat(user_input)
def match_skill(self, user_input: str) -> Skill | None: """匹配最适合的 Skill""" for skill in self.skills.values(): if skill.can_handle(user_input): return skill return None |
这种模式的好处是:通用对话和专业任务分离。Agent 遇到它有 Skill 的任务,就用 Skill 的高质量流程来处理;遇到没有 Skill 覆盖的任务,就用通用能力兜底。
4.6 实际案例:Claude Code 中的 Skill 体系
Claude Code(Anthropic 的 CLI 编程助手)中的 Skill 是一个很好的实际案例。它的 Skill 系统有以下特点:
- 声明式定义:每个 Skill 有名称、描述、触发词、执行指令
- 自动触发:用户输入匹配触发词时自动激活对应 Skill
- 可组合:一个 Skill 可以调用其他 Skill,形成链式执行
- 可独立迭代:修改一个 Skill 不影响其他 Skill
比如一个"生成博客文章"的 Skill,它内置了:
- 文章结构模板(引言、正文、总结的标准框架)
- 写作风格约束(避免 AI 套话、保持技术深度)
- 图表生成流程(自动调用 draw.io Skill 生成配图)
- 质量检查清单(自动检查技术准确性、代码可运行性)
如果没有这个 Skill,你每次都要在 Prompt 中把这些要求重复一遍,效果还不稳定。有了 Skill,一句"帮我写一篇关于 Redis 的文章"就能触发整套高质量流程。
五、MCP:AI 世界的"USB 接口"
5.1 一句话定义
MCP(Model Context Protocol)= 模型上下文协议。它是 Anthropic 在 2024 年底推出的一个开放标准,定义了 AI 应用与外部数据源、工具之间的通信协议。简单说,MCP 就是 AI 世界的"USB 接口"——有了这个标准,任何工具都可以用统一的方式接入任何 AI 应用。
5.2 MCP 要解决什么问题?
在 MCP 出现之前,AI 应用接入外部工具的方式是这样的:
- 接 GitHub?写一套 GitHub 的适配代码
- 接 Slack?再写一套 Slack 的适配代码
- 接数据库?再写一套……
- 换一个 AI 框架?所有适配代码全部重写
这就是经典的 M×N 问题:M 个 AI 应用 × N 个工具,需要 M×N 个适配器。
MCP 的解决方案是:定义一个统一的协议标准。工具只需要实现一次 MCP Server,就能被所有支持 MCP 的 AI 应用调用。AI 应用只需要实现一次 MCP Client,就能接入所有 MCP Server。M×N 变成了 M+N。
这跟 USB 的故事一模一样——USB 出现之前,每个外设都有自己的接口;USB 出现之后,一个接口走天下。
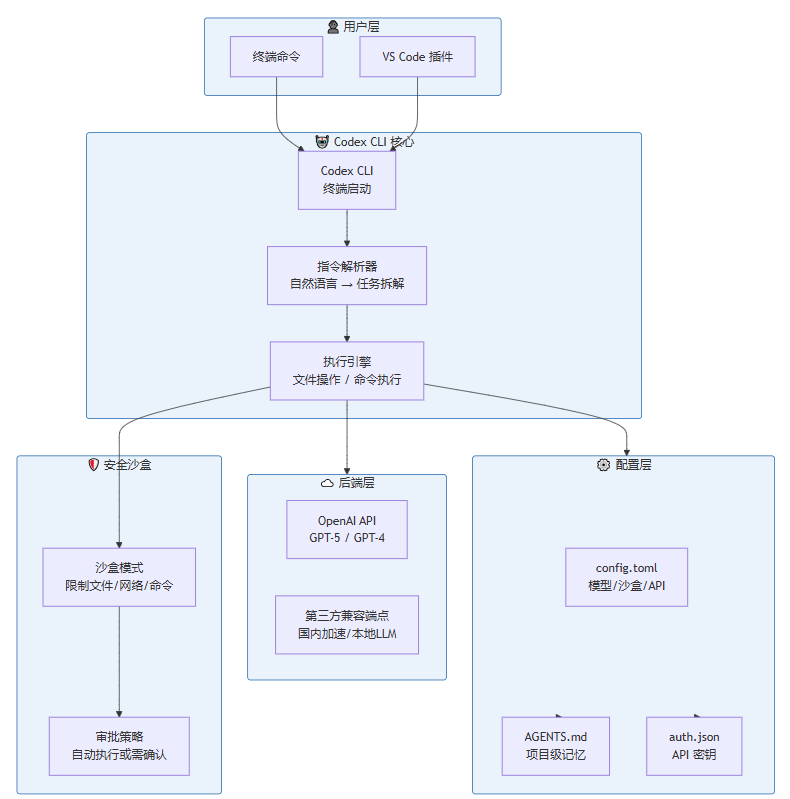
5.3 MCP 的架构
MCP 采用经典的客户端-服务器(Client-Server)架构:
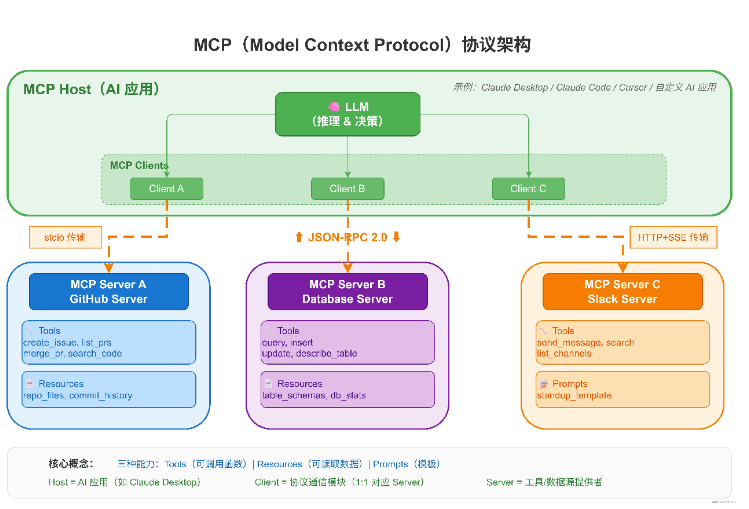
图4 展示了 MCP 的三层架构。Host 是面向用户的 AI 应用,Client 负责协议通信,Server 封装了具体的工具和数据源。一个 Host 可以连接多个 Server,每个 Server 提供不同的能力。
三个核心角色
MCP Host(宿主):面向用户的 AI 应用,比如 Claude Desktop、IDE 插件、自定义的 AI 应用。Host 内部包含 LLM,负责理解用户意图并决定调用哪些工具。
MCP Client(客户端):Host 中负责与 MCP Server 通信的模块。每个 Client 与一个 Server 保持一对一的连接。
MCP Server(服务端):工具和数据源的提供者。每个 Server 封装一个或一组相关的能力,通过 MCP 协议暴露给 Client。
三种核心能力
MCP Server 可以向 Client 暴露三种类型的能力:
| 能力类型 | 说明 | 示例 |
|---|---|---|
| Tools(工具) | 可以被 LLM 调用的函数 | 查询数据库、发送消息、创建文件 |
| Resources(资源) | 可以被读取的数据 | 文件内容、数据库记录、API 响应 |
| Prompts(提示模板) | 预定义的 Prompt 模板 | 代码审查模板、翻译模板 |
5.4 MCP 的通信机制
MCP 基于 JSON-RPC 2.0 协议进行通信,支持两种传输方式:
(1)Stdio(标准输入输出):Server 作为子进程运行,通过 stdin/stdout 与 Client 通信。适合本地工具。
(2)HTTP + SSE(Server-Sent Events):Server 作为独立的 HTTP 服务运行,Client 通过 HTTP 请求发送命令,Server 通过 SSE 推送响应和通知。适合远程服务。
一次典型的 MCP 交互流程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
1. Client → Server: initialize(初始化握手) Client 发送自己支持的协议版本和能力
2. Server → Client: initialize response Server 返回自己的能力列表(支持哪些 Tools/Resources/Prompts)
3. Client → Server: tools/list(查询可用工具) 获取 Server 提供的所有工具的名称、描述、参数 Schema
4. [用户提问,LLM 决定需要调用某个工具]
5. Client → Server: tools/call(调用工具) { "method": "tools/call", "params": { "name": "query_database", "arguments": { "sql": "SELECT * FROM users WHERE status = 'active'" } } }
6. Server → Client: tool result(返回工具执行结果) { "content": [ { "type": "text", "text": "查询到 42 条记录..." } ] }
7. [LLM 基于工具返回结果继续推理或回复用户] |
5.5 实现一个 MCP Server
下面用 Python 实现一个简单的 MCP Server,它提供两个工具:查询天气和查询汇率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from mcp.server import Server from mcp.types import Tool, TextContent import mcp.server.stdio
# 创建 MCP Server 实例 server = Server("weather-exchange-server")
# 定义工具列表 @server.list_tools() async def list_tools() -> list[Tool]: """声明这个 Server 提供哪些工具""" return [ Tool( name="get_weather", description="查询指定城市的当前天气", inputSchema={ "type": "object", "properties": { "city": { "type": "string", "description": "城市名称,如 '北京'、'上海'" } }, "required": ["city"] } ), Tool( name="get_exchange_rate", description="查询货币汇率", inputSchema={ "type": "object", "properties": { "from_currency": {"type": "string", "description": "源货币,如 USD"}, "to_currency": {"type": "string", "description": "目标货币,如 CNY"} }, "required": ["from_currency", "to_currency"] } ) ]
# 实现工具的具体逻辑 @server.call_tool() async def call_tool(name: str, arguments: dict) -> list[TextContent]: """处理工具调用请求""" if name == "get_weather": city = arguments["city"] # 实际项目中这里会调用真实的天气 API weather = fetch_weather_api(city) return [TextContent(type="text", text=f"{city}当前天气:{weather}")]
elif name == "get_exchange_rate": rate = fetch_exchange_rate( arguments["from_currency"], arguments["to_currency"] ) return [TextContent( type="text", text=f"1 {arguments['from_currency']} = {rate} {arguments['to_currency']}" )]
raise ValueError(f"未知工具: {name}")
# 启动 Server(使用 stdio 传输) async def main(): async with mcp.server.stdio.stdio_server() as (read, write): await server.run(read, write)
if __name__ == "__main__": import asyncio asyncio.run(main()) |
要在 Claude Desktop 中使用这个 Server,只需在配置文件中添加:
|
1 2 3 4 5 6 7 8 |
{ "mcpServers": { "weather-exchange": { "command": "python", "args": ["path/to/weather_server.py"] } } } |
配置完成后,Claude 就可以在对话中调用 get_weather 和 get_exchange_rate 这两个工具了——整个过程不需要修改 Claude 的任何代码。
5.6 MCP 的生态现状
截至 2025 年,MCP 生态已经有了相当的规模:
官方支持的 Host:
- Claude Desktop
- Claude Code(CLI)
- Cursor、Windsurf 等 AI IDE
社区 MCP Server:
- 文件系统操作(读写本地文件)
- GitHub / GitLab(仓库管理、PR、Issue)
- 数据库(PostgreSQL、MySQL、SQLite)
- Slack / Discord(消息发送和查询)
- 浏览器自动化(Puppeteer)
- 搜索引擎(Brave Search)
MCP vs. OpenAI Function Calling:
| 维度 | MCP | OpenAI Function Calling |
|---|---|---|
| 定位 | 开放标准协议 | 特定厂商的 API 特性 |
| 跨模型 | 是,任何 LLM 都可以用 | 仅限 OpenAI 模型 |
| 运行方式 | 独立的 Server 进程 | 嵌入在 API 调用中 |
| 能力范围 | Tools + Resources + Prompts | 仅 Tools |
| 有状态 | 是,支持持久连接和会话 | 否,每次调用独立 |
| 标准化 | 有完整的协议规范 | API 接口约定 |
MCP 的野心更大——它不是要替代 Function Calling,而是要成为 AI 工具生态的通用标准,就像 HTTP 之于 Web、SQL 之于数据库。
六、四者的关系:一张图讲清楚
到这里,四个概念都讲完了。最后用一张图把它们的关系串起来:
| 概念 | 角色定位 | 解决的核心问题 | 类比 |
|---|---|---|---|
| Agent | 自主执行者 | AI 如何自主完成复杂任务 | 一个能干的员工 |
| RAG | 知识供给 | AI 如何获取准确的领域知识 | 员工的参考资料库 |
| Skill | 能力单元 | AI 的能力如何标准化和复用 | 员工的标准作业流程 |
| MCP | 连接协议 | AI 如何统一地调用外部工具 | USB 接口标准 |
它们的协作方式:
|
1 2 3 4 5 6 |
用户下达任务 ↓ Agent(自主规划和执行) ├── 需要知识 → 调用 RAG 检索相关文档 ├── 匹配到专业任务 → 激活对应的 Skill 执行 └── 需要调外部工具 → 通过 MCP 协议调用 MCP Server |
一个具体的场景:用户说"帮我排查 JIRA-1234 这个线上问题"。
- Agent 接收任务,规划执行步骤
- Agent 激活 oncall-dispatcher Skill(线上问题排查的标准流程)
- Skill 内部通过 MCP 协议调用 JIRA Server 获取问题详情
- Skill 通过 MCP 协议调用日志查询 Server 搜索相关日志
- Agent 利用 RAG 从代码知识库中检索相关源码和文档
- Agent 综合所有信息,输出根因分析报告
四个概念各司其职,共同完成了一个完整的工作流。
七、技术选型指南:实际工程中怎么选?
场景一:企业知识问答机器人
核心需求:员工可以用自然语言查询公司规章制度、技术文档等。
推荐方案:RAG 为主。将公司文档索引到向量数据库,通过 RAG 管道实现知识问答。不需要 Agent(单轮问答就够了),不需要 MCP(不需要调用外部工具)。
场景二:AI 编程助手
核心需求:辅助开发者编写代码、排查问题、做 Code Review。
推荐方案:Agent + Skill + MCP 的完整组合。Agent 负责理解意图和编排执行;Skill 封装各类编程任务的最佳实践(代码审查 Skill、单元测试 Skill 等);MCP 连接 IDE、Git、数据库、日志服务等外部工具。如果需要参考项目文档,再加上 RAG。
场景三:智能客服系统
核心需求:自动回答客户问题,必要时执行操作(查订单、退款等)。
推荐方案:Agent + RAG + MCP。RAG 提供产品知识和FAQ;Agent 判断什么时候需要查询系统、执行操作;MCP 连接订单系统、CRM 等后端服务。可以用 Skill 封装常见操作的流程(查订单、申请退款等)。
场景四:数据分析助手
核心需求:用户用自然语言描述分析需求,AI 自动生成 SQL 并执行。
推荐方案:Agent + MCP。Agent 负责理解分析需求、生成 SQL、解读结果;MCP 连接数据库执行查询。可以用 RAG 存储表结构和业务术语的映射关系,帮助 Agent 生成更准确的 SQL。