
正则表达式的整理与归纳

正则表达式是由普通字符(a-z)和特殊字符(元字符)组成的文本模式。例如,在正则表达式[a-z]*描述了所有仅包含小写字母的字符串,其中a,z为普通字符,连字符、左右中括号及星号则为元字符
|
正则表达式是由普通字符(a-z)和特殊字符(元字符)组成的文本模式。例如,在正则表达式“[a-z]*”描述了所有仅包含小写字母的字符串,其中a,z为普通字符,连字符、左右中括号及星号则为元字符 正则表达式中的元字符的类别1. 点号 点号可以匹配除“\n”之外的任何单字符 。 2. 中括号 可以在中括号([])内指定需要匹配的若干字符,表示仅使用这些字符参与匹配。 3. 竖线 竖线(|)可以匹配其左侧或右侧的符号。 4. ^符号 ^符号可以匹配一行的开始。 5. 美元符号 美元符号($)可以匹配一行的结束。 6. 反斜线 反斜线()表示其后的字符是普通字符而非元字符。 常用的匹配次数元符号
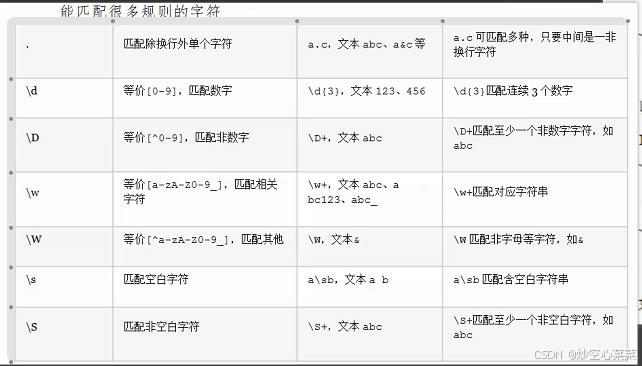
预定义字符(只匹配一个字符)
自定义字符(只匹配一个字符)
举例如下
运行结果
其它方面的细节及注意事项
|
您可能感兴趣的文章 :

-
正则表达式IP地址合法性判断
一、正则表达式常见匹配字符快速回顾 符号 描述 . 匹配处换行符\n之外任意1个字符 [] 匹配[]中任意一个 \d 一个0-9数字 \D 匹配非数字 \w 匹配 -
正则表达式中的特殊符号的介绍
正则表达式中的特殊符号 如: 1 preg_match(/.+?hxx/is, hxx)); 返回,0,表示没有匹配,这是因为.+?的作用,具体讲一下。 .的作用 作用:匹配除换 -
S3标签字符清洗的正则表达式实践记录
深入理解 S3 标签字符清洗的正则表达式实践 在构建与 AWS S3 相关的服务时,尤其是使用 S3 标签(Tag)作为资源标识或元数据时,确保标签值 -
正则表达式高级应用与性能优化记录
第6章:正则表达式的高级应用 6.1 模式匹配与文本处理 正则表达式不仅可以用于简单的搜索和替换,还可以用于复杂的文本处理任务,比如 -
scala中正则表达式的使用介绍
基本概念 在 Scala 中,正则表达式是用于处理文本模式匹配的强大工具。它通过java.util.regex.Pattern和java.util.regex.Matcher这两个 Java 类来实现( -
正则表达式中的test和 /[^A-Za-z0-9]/ ?(推荐)介绍
一、什么是 test 方法? 1. 方法概述 test是 JavaScript 正则表达式对象 (RegExp) 提供的一种方法,用于测试字符串是否匹配特定的正则表达式模式 -
@Pattern用于校验字符串是否符合特定正则表达式的
@Pattern是一个用于校验字符串是否符合特定正则表达式的注解,它在 Java 中常用于验证输入数据的格式。以下是@Pattern注解的详解和使用方法



-
Java正则表达式里隐藏的陷阱
2021-06-04
-
Python中正则表达式的巧妙使用一文包
2019-05-27
-
如何使用正则表达式对输入数字进行
2022-10-12
-
最实用的正则表达式的整理
2022-10-12
-
正则表达式去除中括号(符号)及里
2019-06-26

