keras中卷积层Conv2D的学习
关于卷积的具体操作不细讲,本文只是自己太懒了不想记手写笔记。
由于自己接触到的都是图像
处理相关的工作,因此,在这里只介绍2D卷积。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
keras.layers.convolutional.Conv2D(filters,kernel_size,strides(1,1),
padding='valid',
data_format=None,
dilation_rate=(1,1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None)
|
此操作将二维向量进行卷积,当使用该层作为第一层时,应提供input_shape参数。
参数
- filters:卷积核的数目(即输出的维度)。
- kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
- strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rata均不兼容。
- padding:补0策略,为“valid”, “same”。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)。
- dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rata均与任何不为1的strides均不兼容。
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
- use_bias:布尔值,是否使用偏置项。
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象。
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象。
- activity_regularizer:施加在输出上的正则项,为Regularizer对象。
- kernel_constraints:施加在权重上的约束项,为Constraints对象。
- bias_constraints:施加在偏置上的约束项,为Constraints对象。
keras中conv2d,conv2dTranspose的Padding详解
conv2d和conv2dTranspose属于最常用的层,但在keras的实现中关于padding的部分有点模糊,周末趁着空闲做了一些尝试,来实验padding的valid和same参数在实际过程中如何操作的。
conv2D演示代码
conv2D部分
|
1
2
3
4
5
6
7
8
9
10
11
|
v_input = np.ones([1,5,5,1])
kernel = np.ones([3,3])
stride = 1
model = Sequential()
model.add(Conv2D(1, kernel_size=(3, 3),
activation='relu',
padding="valid" , # "same"
strides = 1,
# dilation_rate = 1,
kernel_initializer = keras.initializers.Ones(),
input_shape=v_input.shape[1:]))
|
其中stride可以尝试多组测试
padding在valid 和 same 间切换测试
Conv2d演示结论
padding 为valid则不进行填充, 根据stride的滑动大小来做平移, 则:
|
1
|
output_shape = ceil( (input_shape - (kernel_size - 1)) / stride )
|
如果是same模式则 会进行左右上下的补齐, 其中左,上依次补齐 flood (kernel_size -1 ) / 2 , 右下补齐ceil (( kernel_size - 1) /2 ) ,补齐后进行的操作就是类似valid下的滑动卷积
|
1
|
output_shape = ceil (input_shape / stride)
|
CONV2Dtranspose演示代码
|
1
2
3
4
5
6
7
8
9
10
11
|
v_input = np.ones([1,5,5,1])
kernel = np.ones([3,3])
stride = 1
model = Sequential()
model.add(Conv2DTranspose(1, kernel_size=(3, 3),
activation='relu',
padding="valid" , # "same"
strides = 1,
# dilation_rate = 1,
kernel_initializer = keras.initializers.Ones(),
input_shape=v_input.shape[1:]))
|
如果padding的设置为valid则,保持最小相交的原则上下左右均填充kernel_size大小,如果stride设置为非1,起实际的作用和dilation_rate一样均是在矩阵中进行填充(实际滑动是永远都是1) 具体填充出来的矩阵大小是 (input_size -1) * stride + 1 + 2 * (kernel_size - 1)
之后就是按照这个矩阵做着类似conv2d valid的卷积 则:
|
1
|
output_shape = (input_size -1) * stride + 1 + 2 * (kernel_size - 1) - (kernel_size -1) = (input_size - 1) * stride + kernel_size
|
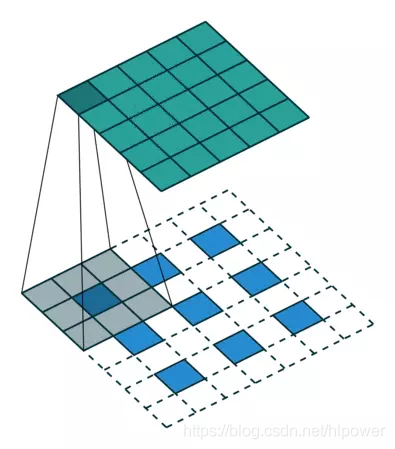
如果padding为same的话则output_shape = input_shape * stride
其中原始矩阵左上padding = ceil (( kernel_size ) /2 ) 右下补齐 flood (( kernel_size ) /2 ) 这里conv2d
|