
PyTorch张量操作指南(cat、stack、split与chunk)

在深度学习实践中,张量的维度变换是数据处理和模型构建的基础技能。无论是多模态数据的融合(如图像与文本),还是批处理数据的拆分重组,合理运用张量操作函数可显著优化计算流程
|
在深度学习实践中,张量的维度变换是数据处理和模型构建的基础技能。无论是多模态数据的融合(如图像与文本),还是批处理数据的拆分重组,合理运用张量操作函数可显著优化计算流程。PyTorch提供的cat、stack、split和chunk正是解决此类问题的利器。以下将逐一解析其原理与应用。 一、torch.cat: 沿指定维度拼接张量功能描述torch.cat(concatenate)沿已有的某一维度连接多个形状兼容的张量,生成更高维度的单一张量。要求除拼接维度外,其余维度的大小必须完全一致。 示例代码
二、torch.stack: 创建新维度堆叠张量功能描述torch.stack会将输入张量沿新创建的维度进行堆叠,所有参与堆叠的张量必须具有完全相同的形状。输出张量的维度比原张量多一维。 示例代码
三、torch.split: 按尺寸分割张量功能描述torch.split根据指定的尺寸将输入张量分割为多个子张量。支持两种参数形式:
示例代码
四、torch.chunk: 按数量均分张量功能描述torch.chunk将输入张量沿指定维度均匀划分为N份。若无法整除,剩余元素分配到前面的分片中。 示例代码
综合示例:图像数据的分割与合并处理以下是结合图像数据的完整操作示例,模拟图像预处理流程中的张量操作场景: 场景设定假设我们有一批RGB图像数据(尺寸为 3×256×256),需要完成以下操作:
代码实现
关键操作解析
扩展应用建议
通过这个完整的图像处理流程示例,可以清晰看到:
总结与对比
应用建议:
掌握这些工具后,您将能更灵活地操控张量维度,适应复杂模型的构建需求! |
您可能感兴趣的文章 :

-
python怎么调用java的jar包
一、安装包 1 pip3 install JPype1 二、使用步骤 1、导入jpype模块 2、python要调用的java的jar包路径 3、获取jvm.dll的文件路径 4、使用jpype开启虚拟机 -
PyTorch张量操作指南(cat、stack、split与chunk)
在深度学习实践中,张量的维度变换是数据处理和模型构建的基础技能。无论是多模态数据的融合(如图像与文本),还是批处理数据的拆 -

Python osgeo库安装失败问题的解决方案
Osgeo(Open Source Geospatial Foundation)是一个支持开源地理空间数据处理的基金会,我们可以在python中使用osgeo库来访问其提供的高效地理空间数 -
python ftplib上传文件名乱码的解决办法
公司安排我用RPA把各电商平台昨天直播和视频相关的曝光、销售等数据下载下来,我用rpa基本一个星期完成了,最后用影刀RPA自带的ftp文件 -
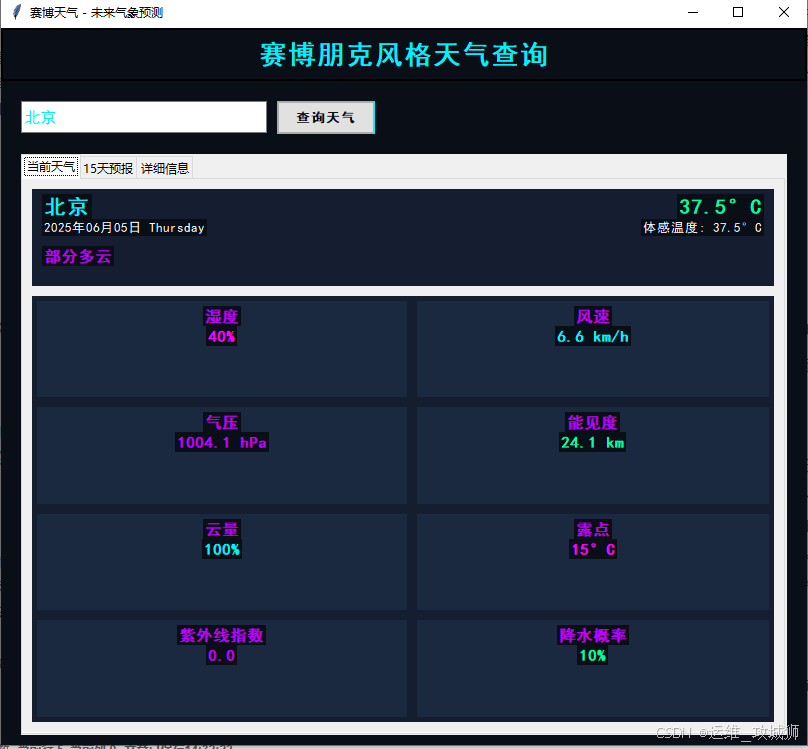
python编写朋克风格的天气查询程序
这个天气查询工具是一个基于 Python 的桌面应用程序,使用了tkinter库来创建图形用户界面(GUI),并通过requests库调用 Open - Meteo API 获取天气 -
Python处理大量Excel文件的十个技巧
一、批量读取多个Excel文件 在实际工作中,经常要处理多个Excel文件。用Python批量读取特别方便: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 2 -
Python f-string实现高效字符串格式化
f-string,称为格式化字符串常量(formatted string literals),是Python3.6新引入的一种字符串格式化方法,该方法源于PEP 498 Literal String Interpolati -
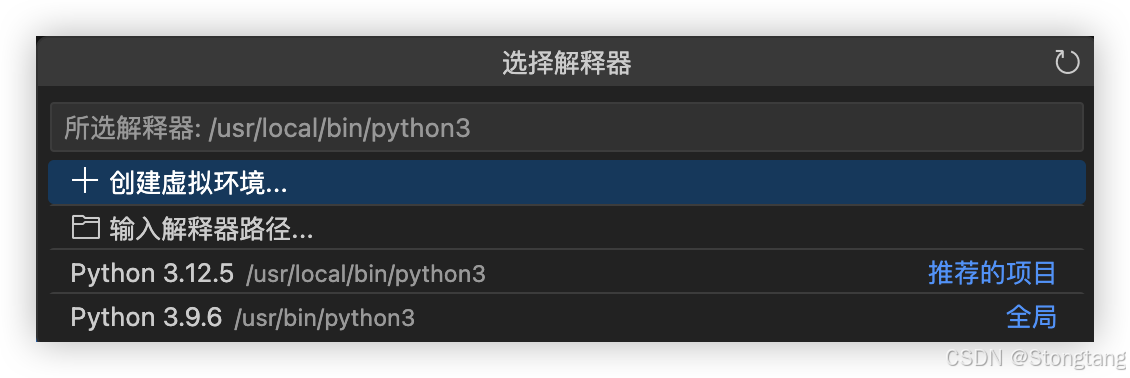
无法找到VS Code Python解释器的几种解决办法
在编写和运行 Python 代码之前,需要确保 VS Code 知道使用哪个 Python 解释器。 打开刚才创建的 Python 文件(如hello_world.py)。 点击 VS Code 窗口 -
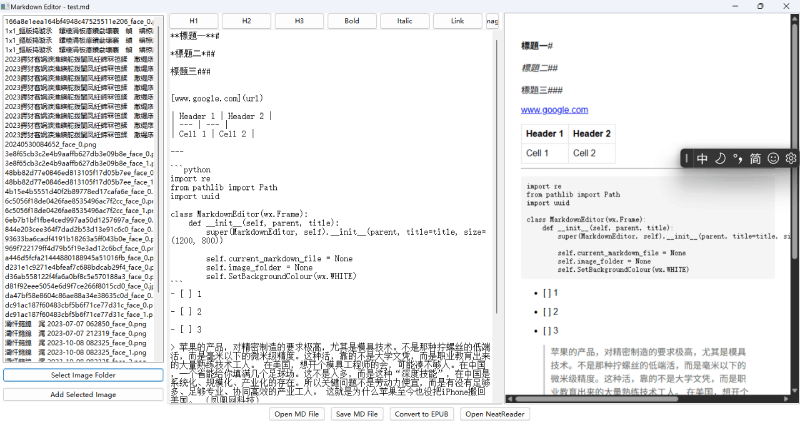
使用Python开发一个带EPUB转换功能的Markdown编辑器
Markdown因其简单易用和强大的格式支持,成为了写作者、开发者及内容创作者的首选格式。想象一下,如果你不仅能编辑Markdown,还能实时预



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

