
一篇带你搞定Ollama模型的安装到生产级调优

一、Ollama 概述与核心价值 Ollama 是一个轻量级、可扩展的本地大语言模型运行框架,旨在简化 LLM 的部署、管理和使用流程。它将复杂的模型下载、环境配置、API 服务封装为简单的命令行操作
一、Ollama 概述与核心价值Ollama 是一个轻量级、可扩展的本地大语言模型运行框架,旨在简化 LLM 的部署、管理和使用流程。它将复杂的模型下载、环境配置、API 服务封装为简单的命令行操作,让开发者能在个人电脑、服务器甚至边缘设备上快速运行 Llama、Mistral、Gemma、Qwen 等主流开源模型。 为什么需要配置与优化?尽管 Ollama 开箱即用,但默认设置往往不能发挥硬件的最佳性能。例如,CPU 推理时内存带宽利用率低、GPU 显存分配不合理、并发请求处理能力弱、模型量化精度与响应速度的平衡等问题,都需要通过细致的配置调优来解决。合理的配置可以显著降低延迟、提升吞吐量、减少资源占用,使本地模型部署达到生产可用级别。 二、环境准备与基础安装2.1 系统要求
2.2 安装步骤Linux/macOS(一键脚本)
手动安装(以 Ubuntu 为例)
Windows WSL2 方式
2.3 验证安装
三、核心配置详细步骤3.1 配置文件的定位与结构Ollama 使用分层配置机制:
默认数据目录:
核心配置文件位置(需手动创建):
3.2 服务端性能优化配置步骤 1:调整系统服务参数 编辑 Ollama 的系统服务配置:
写入以下优化内容:
保存后重载并重启:
步骤 2:NUMA 架构优化(多 CPU 插槽服务器)
3.3 模型下载与缓存优化设置代理加速下载(国内环境必须):
使用 ModelScope 镜像下载(替代 HuggingFace):
3.4 Modelfile 自定义配置创建自定义 Modelfile 优化推理行为:
创建并测试自定义模型:
3.5 GPU 显存与并发优化混合精度与显存管理:
多 GPU 负载均衡(手动分片):
Flash Attention 手动验证:
3.6 API 网关与反向代理配置使用 Nginx 作为 Ollama 前端,实现负载均衡和速率限制:
启动多实例:
四、性能基准测试与监控4.1 基本性能测试脚本
4.2 监控 OLLAMA 资源占用
五、生产环境优化检查清单5.1 硬件层优化
5.2 系统层优化
5.3 Ollama 特定优化
六、常见问题与解决方案问题 1:Ollama 运行一段时间后内存不断增长解决:设置内存回收机制
问题 2:GPU 显存不足(OOM)解决:启用 CPU 卸载或减小批大小
问题 3:首次 token 延迟过高(TTFT > 2s)解决:预热模型 + 优化提示词缓存
七、总结7.1 核心优化原则回顾Ollama 的配置与优化本质是资源与需求的精准匹配。通过本文的详细步骤,我们实现了以下关键提升:
7.2 配置文件最佳实践总结
7.3 优化效果数据参考基于单张 NVIDIA RTX 4090(24GB 显存)+ AMD Ryzen 9 7950X 的实测数据:
7.4 进阶优化对于更高要求的生产场景,可进一步探索:
7.5 避坑指南
通过系统性地应用上述配置与优化策略,Ollama 可以从一个“能运行”的状态升级为“高效稳定运行”的生产级 LLM 服务框架。每一个环境(硬件、网络、负载模式)都是独特的,结合实际的监控数据(如 Prometheus + Grafana)进行迭代调优。最终目标是在延迟、吞吐、成本、稳定性的四维平衡中找到最适合自己场景的最优解。 |
您可能感兴趣的文章 :

-
Claude Code接入本地大模型Qwen3.6 进行代码开发(vL
Claude Code 是 Anthropic 推出的智能编码命令行工具,默认使用 Claude 系列模型。但我们可以通过指定自定义 API 端点,将其连接到本地部署的 -

在Windows上优雅地启动Hermes Agent Web Dashboard
Hermes Agent 是 Nous Research 开发的 AI 智能体,可以在 WSL2 中运行并提供 Web Dashboard 界面。但每次启动都需要打开 WSL2 终端,运行命令,然后手动 -
一篇带你搞定Ollama模型的安装到生产级调优
一、Ollama 概述与核心价值 Ollama 是一个轻量级、可扩展的本地大语言模型运行框架,旨在简化 LLM 的部署、管理和使用流程。它将复杂的模型 -
penClaw到底能做什么?有什么用?推荐你先装这几
OpenClaw之所以能从众多AI助手中脱颖而出,核心原因在于它的Skills生态系统。如果说大语言模型是OpenClaw的大脑,那么Skills就是它的双手和专 -
macOS系统下安装与配置Hermes Agent的完整教程
Hermes Agent 支持 macOS,但安装过程有几个点需要注意。本文是 macOS 专属安装指南,覆盖从零配置到运行的全流程,以 MiniMax 为例演示 AI 提供 -
Hermes Agent接入DeepSeek V4的完整介绍
一、背景:为什么要在 Hermes Agent 中用 DeepSeek V4 1.1 Hermes Agent 是模型无关的 Hermes Agent 设计了一个很重要的特性模型无关(Model-Agnostic)。它 -

Windows原生部署OpenClaw并对接DeepSeek-V4大模型的全流
一、准备工作 1. 系统与环境要求 操作系统:Windows 10 21H2 及以上 / Windows 11 硬件:内存 4GB(推荐 8GB+),硬盘可用空间 1GB 网络:需联网下载 -
国内直连、低成本调用主流大模型API:以OpenCla
目前市面上提供 API 代理的平台很多,但在高并发场景下往往容易出现报错或断连问题。加上近期开源生态频繁发生的依赖包投毒事件,给
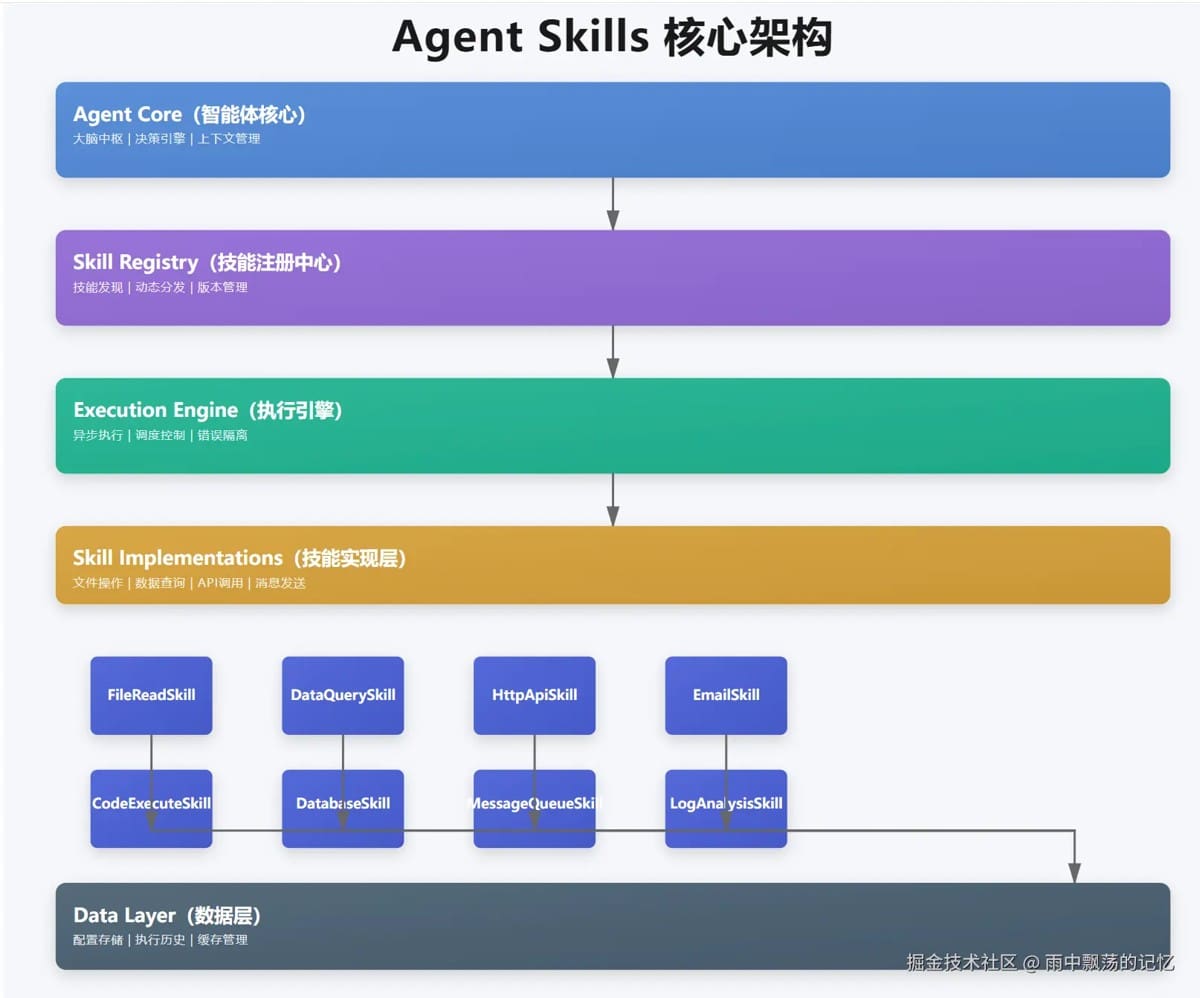




-
Agent Skills工作流从入门到实战
2026-05-11
-
OpenClaw指令分类详解与使用
2026-05-11
-
penClaw到底能做什么?有什么用?推荐
2026-05-11
-
Windows原生部署OpenClaw并对接DeepSeek-V
2026-05-11
-
在Windows上优雅地启动Hermes Agent Web D
2026-05-13

