
codex改文件中文乱码的解决方法

最近发现闲鱼可以不到几块钱,可以拼车GPT Team,就能使用codex各个模型一个月(本质上这些人是搞的0刀或1刀试用team) 体验之后,不得不说,codex确实比kimi 2.5等国产模型一次通过率高很多,
|
最近发现闲鱼可以不到几块钱,可以拼车GPT Team,就能使用codex各个模型一个月(本质上这些人是搞的0刀或1刀试用team)
体验之后,不得不说,codex确实比kimi 2.5等国产模型一次通过率高很多,用的很爽,额度很多,真的量大管饱(如果用codex 桌面端还能限时享受2倍额度)
但是使用过程中,我发现有一个问题——codex经常把中文改成乱码,网上搜索了一翻,发现要安装powershell 7才能解决 为什么要安装powershell 7
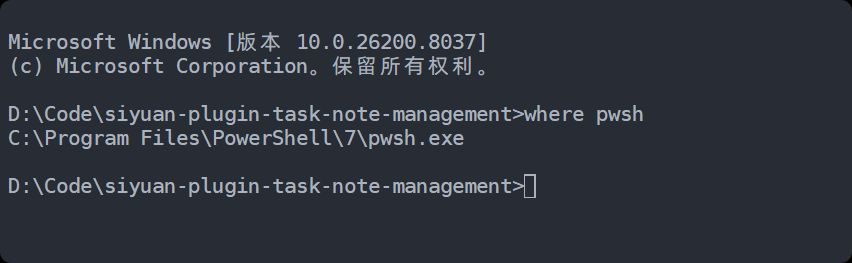
Codex 基于 Node.js,默认 UTF-8,而Windows 自带的PowerShell 5.1 /cmd 默认 GBK(代码页 936),codex读写文件之后就会导致编码冲突,从而导致中文产生乱码 而PowerShell 7 默认 UTF-8,就可以解决乱码情况 如何安装powershell 7安装powershell 7:https://github.com/powershell/powershell/releases(也可以前往微软商店下载) 之后重启电脑,不重启可能有些终端依然使用的是powershell5 打开cmd,运行where pwsh?,输出C:\Program Files\PowerShell\7\pwsh.exe?,确保pwsh命令已经可以全局使用
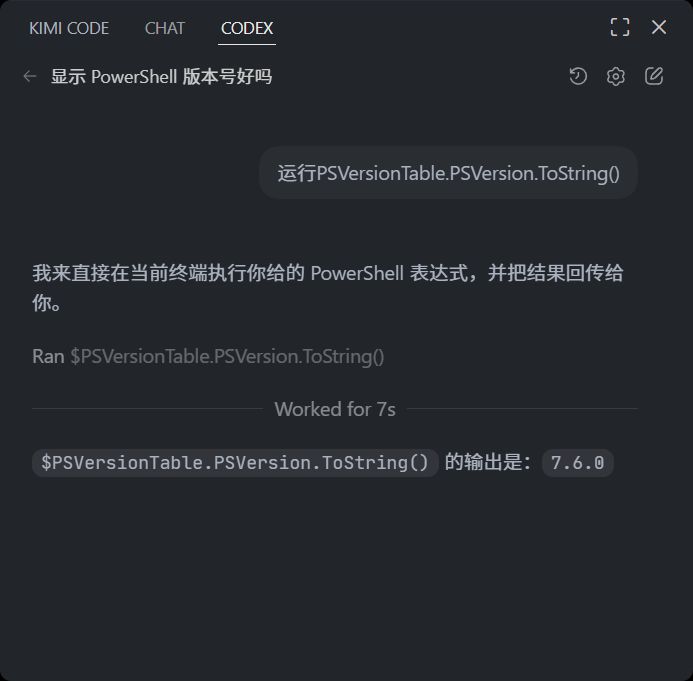
测试codex是否成功使用powershell 7打开codex运行,让其运行PSVersionTable.PSVersion.ToString()?,如果返回的是7.x,说明已经配置成功
之后再让codex改代码,就不会再重新乱码问题了! 扩展内容:彻底解决 Codex / Copilot 修改中文乱码【含自动化解决方案】 彻底解决 Codex / Copilot 修改中文乱码【含自动化解决方案】引言在使用 GitHub Copilot 或 OpenAI Codex 自动重构代码时,你是否遇到过这样的尴尬:AI 生成的代码逻辑完美,但原本注释里的中文却变成了 我爱ä¸æ–‡ 这样的乱码?有时候这种字符甚至会污染正确的代码,带来巨大的稳定性隐患。 一、 问题核心:被忽视的“终端中转”乱码的根源不在于 AI 的大脑,也不在于编辑器 的显示,而在于执行链路的编码不一致。 Copilot/Codex 在执行某些修改任务(如:重构整个文件或批量替换)时,往往会通过终端调用系统指令。由于 Windows 终端(PowerShell/CMD)默认使用 GBK 编码,它在处理 AI 传来的 UTF-8 字节时会发生“误读”,导致写入文件的内容从源头上就损坏了。 二、 解决方案:构建全链路 UTF-8 环境本文给出一套全自动的解决方案。首先,先新建一个.txt 文件,然后将下方的代码复制进新建的.txt 文件中。接着,将.txt 文件保存并更名为 fix_all_encoding.bat,右键点击并以管理员身份运行即可:
|

您可能感兴趣的文章 :

-

Windows安装Codex及接入DeepSeek-V4的完整教程
Codex和Claude Code安装类似,都需要先安装git和Node.js,其中Node.js安装的版本需要Node.js 18+以上,如要接入DeepSeek最好安装最新版本的,会省事很 -
带你了解AI Agent Harness
一. 什么是Harness Engineering 它是一套系统化工程方法论,专门设计、搭建、运维这套 AI 管控运行体系,解决 AI 干活不稳定、越权、失忆、失 -
Claude Code Skill的入门与进阶实践指南
用 Claude Code 久了就会发现一件事:很多话你在反复说。 写 PR 描述要固定格式,做代码审查要先看风险,文档要符合团队模板。第一次解释 -
解决 Codex修改文件后中文乱码问题:根源在终端编
????? 解决 Codex 修改文件后中文乱码问题:根源在终端编码,不在 VS Code! 关键词:Codex、中文乱码、VS Code、PowerShell、UTF-8、终端编码、无 -
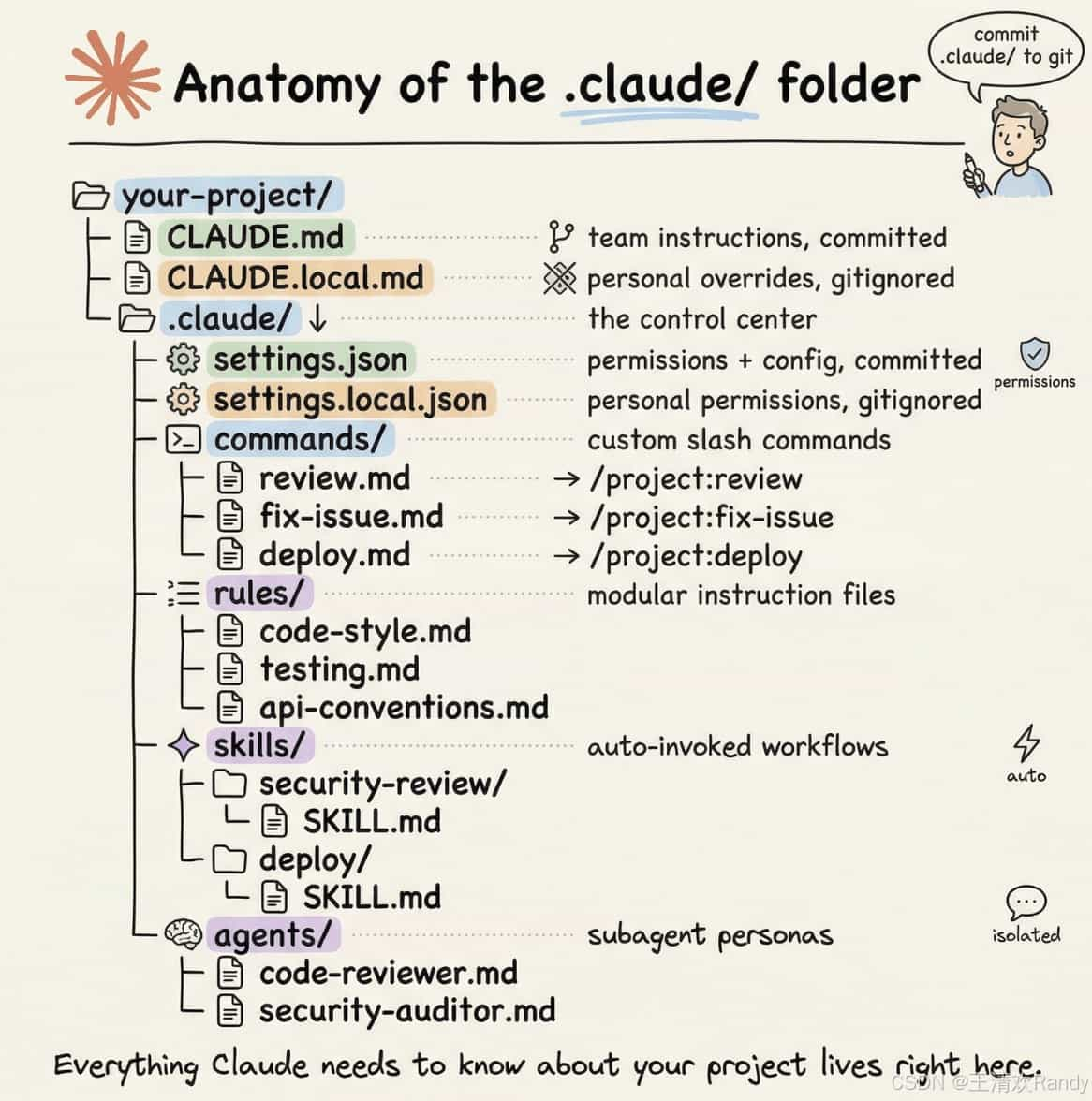
Claude Code 的 .claude 目录介绍
用 Claude Code 一段时间后,会发现真正决定它好不好用的,不是模型本身,而是.claude/目录里那几个文件 01 两个 .claude/ 目录 .claude/不是一个目 -
使用AI Agent 做一个前端小游戏(从提示词到可运行
最近 AI 编程很火,但只说AI Agent 很强其实没什么意思。 这篇文章我们换个玩法:直接用 AI Agent 的思路,做一个能运行的前端小游戏。 不讲 -
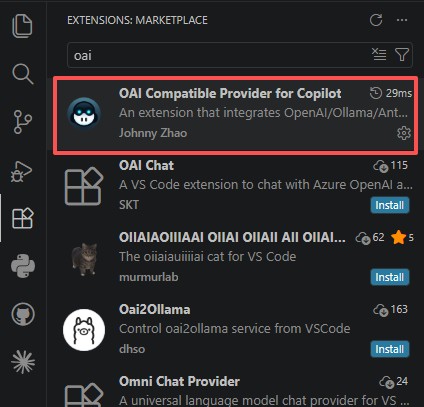
kimi 2.5接入VScode copilot完整图文教程
1.下载extension:OAI Compatible Provider for Copilot 2. 打开vscode settings 3.设置base_url. PS:如果用别的模型的API的话,具体URL参考官方文档,都会有写明



-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Claude Code配置Skills的三种方法
2026-05-31

