
mysql覆盖索引的项目实践

在 MySQL 中,覆盖索引(Covering Index)是一种非常重要的查询优化技术。它的核心思想是:一个索引包含了查询所需的所有字段,因此 MySQL 可以直接从索引中获取数据,而无需回表(即无需访问
|
在 MySQL 中,覆盖索引(Covering Index) 是一种非常重要的查询优化技术。它的核心思想是:一个索引包含了查询所需的所有字段,因此 MySQL 可以直接从索引中获取数据,而无需回表(即无需访问主键索引或数据行) 。 ???? 一、为什么需要覆盖索引?1.普通索引查询的流程(非覆盖)假设有一张用户表:
执行查询:
???? 执行过程:
2.覆盖索引的查询流程如果我们将索引改为:
再执行相同查询:
? 执行过程:
? 二、覆盖索引的核心优势
????? 三、如何判断是否使用了覆盖索引?使用 EXPLAIN 查看执行计划:
关键看 Extra 列:
? 示例输出:
???? 四、覆盖索引的使用条件
?? 五、注意事项与陷阱1.不要盲目创建宽索引
2.主键自动包含在 InnoDB 二级索引中InnoDB 的二级索引叶子节点存储的是 (索引列, 主键值) 。
但:
3.函数或表达式会破坏覆盖
???? 六、实战优化示例场景:高频查询“用户邮箱”
场景:分页 + 排序
? 七、总结
如果你有具体的 SQL 查询需要优化,欢迎贴出来,我可以帮你设计覆盖索引! |
您可能感兴趣的文章 :

-
mysql覆盖索引的项目实践
在 MySQL 中,覆盖索引(Covering Index)是一种非常重要的查询优化技术。它的核心思想是:一个索引包含了查询所需的所有字段,因此 MySQL 可 -
Mac OS上安装PostgreSQL完整图文教程
macOS 上安装 PostgreSQL(完整图文教程) 适用于macOS 12+(Monterey / Ventura / Sonoma / Sequoia),支持Apple Silicon(M1/M2/M3)和Intel 推荐使用Homebrew(最 -
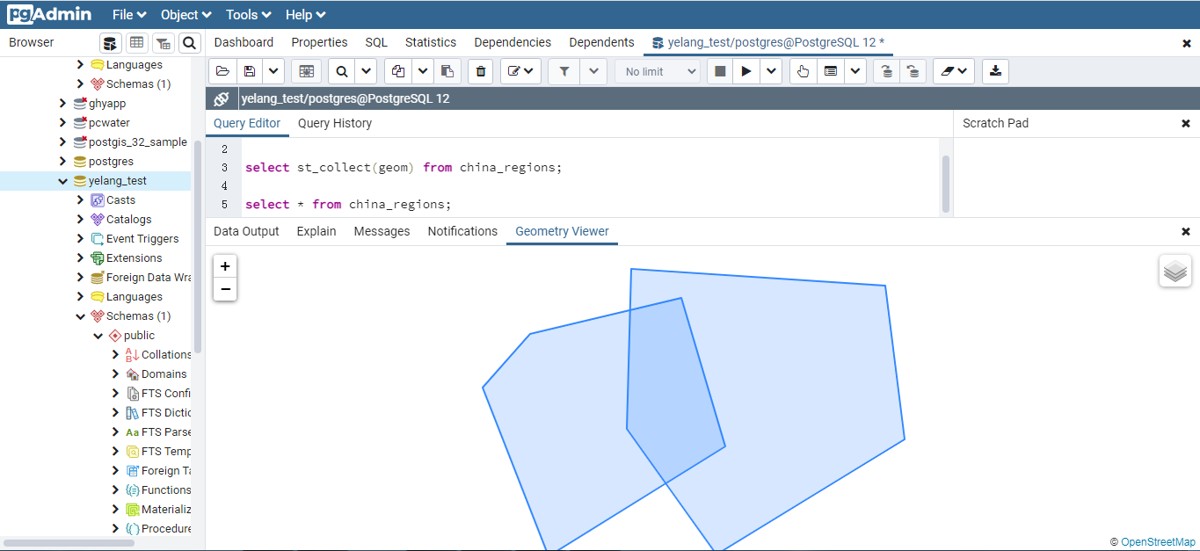
PostGIS中ST_Union与ST_Collect的区别与使用
在地理空间数据库领域,PostGIS作为PostgreSQL的扩展,为地理空间数据的存储、查询和分析提供了强大的功能。对于初入PostGIS世界的新手来说 -
对postgresql日期和时间的比较
postgresql日期和时间比较 DB里保存到时分秒,需要和年月日比较 1 2 3 select date_trunc(day,now())=date_trunc(day,date(20200615)) --true select date_trunc(day,dat -
PostgreSQL中查看当前时间和日期的几种常用方法
PostgreSQL中查看当前时间和日期 CURRENT_TIMESTAMP CURRENT_TIMESTAMP返回当前的日期和时间,包含时间戳信息,包括时区信息。 1 SELECT CURRENT_TIMESTAMP -
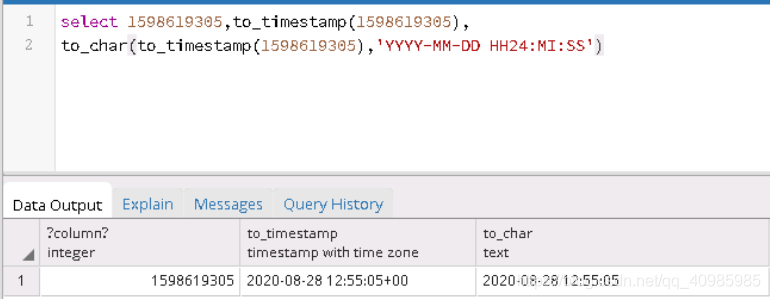
Postgresql之时间戳long,TimeStamp,Date,String互转方式
时间戳long,TimeStamp,Date,String互转 今天遇到一个神奇的问题: Postgre数据库里存的 10位long类型的时间戳,拿Java代码转完的日期年月日时分秒, -
postgresql使用dblink跨库增删改查的详细步骤
postgresql使用dblink跨库增删改查 一、使用步骤 1、创建dblink扩展,连接与被连接的两个数据库都要执行下面sql 1 create extension if not exists dblin -
PostgreSQL中json数据类型介绍
前言 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(European Computer Manufacturers Association, 欧洲计算机协会制定的 -
postgresql使用dblink跨库增删改查的步骤介绍
postgresql使用dblink跨库增删改查 一、使用步骤 1、创建dblink扩展,连接与被连接的两个数据库都要执行下面sql 1 create extension if not exists dblin




-
postgresql使用dblink跨库增删改查的详细
2023-09-30
-
Postgresql之时间戳long,TimeStamp,Date,Stri
2024-02-11
-
在Centos8-stream安装PostgreSQL13的教程
2022-02-26
-
postgresql13主从搭建Ubuntu的教程
2022-11-24
-
PostgreSQL HOT与PHOT有哪些区别
2022-09-22

