简介 背景 Pandas 是 Python 的一个工具库,用于数据分析。 由 AQR Capital Management 于 2008 年 4 月开发,2009 年开源,最初被作为金融数据分析工具而开发出来。 Pandas 名称来源于panel data(面
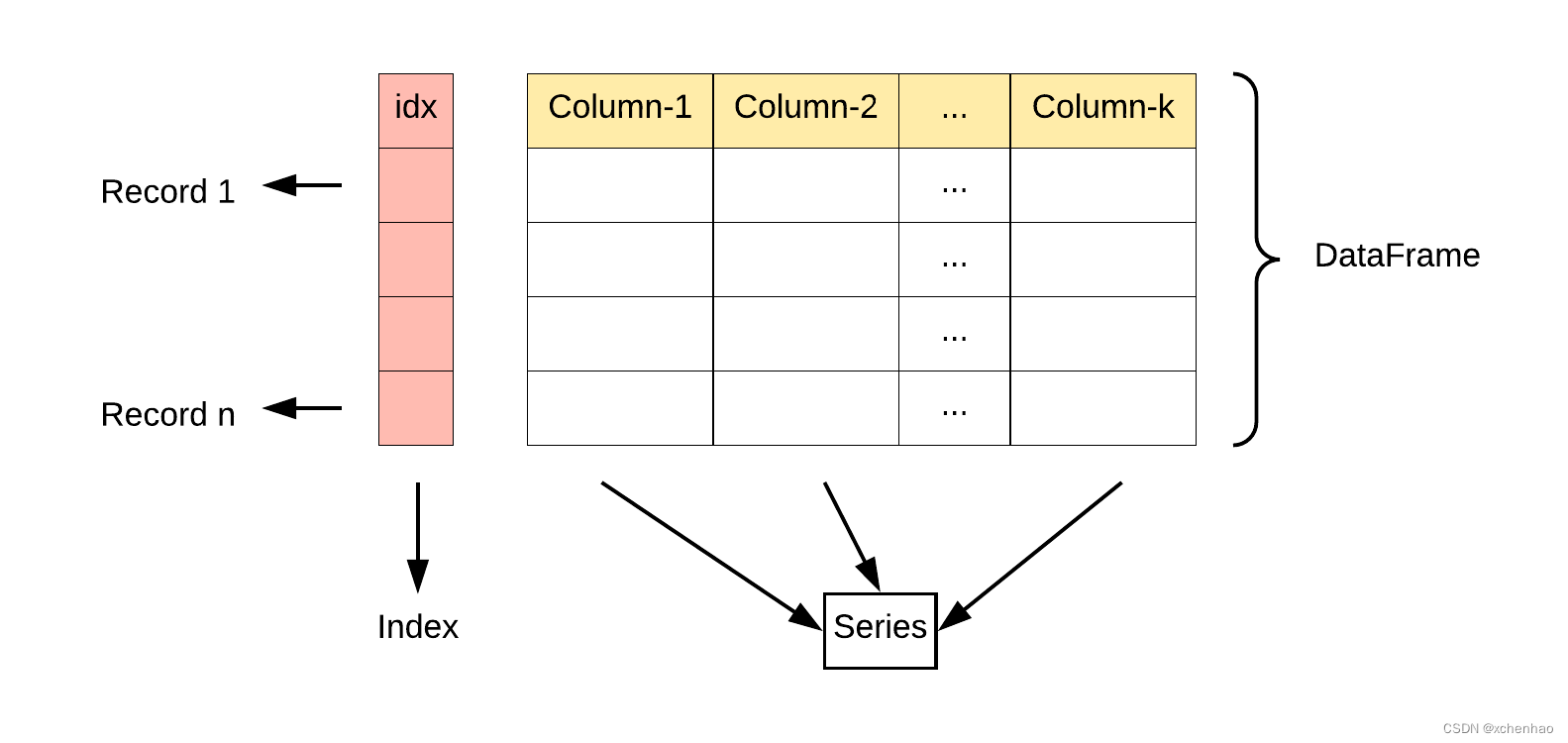
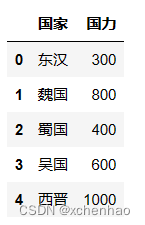
简介背景Pandas 是 Python 的一个工具库,用于数据分析。 由 AQR Capital Management 于 2008 年 4 月开发,2009 年开源,最初被作为金融数据分析工具而开发出来。 Pandas 名称来源于 panel data(面板数据)和 Python data analysis(Python 数据分析)。 适用于金融、统计等数据分析领域。 特点:两大数据结构 Series 和 DataFrame (1)Series:一维数据(列+索引)
(2)DataFrame:二维数据(表格:多个列+行/列索引)
安装如果你使用的是数据科学的 Python 发行版:Anaconda,可以使用 conda 安装
如果是普通的 Python 环境,可以使用 pip 安装
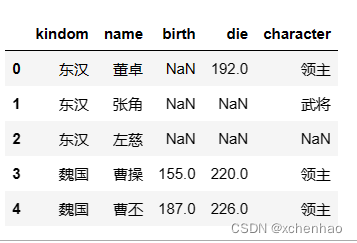
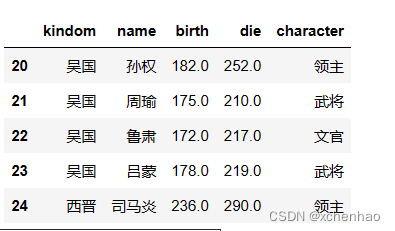
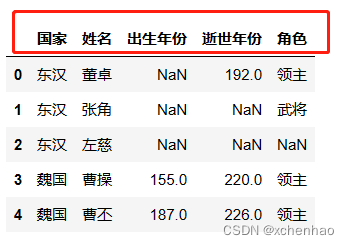
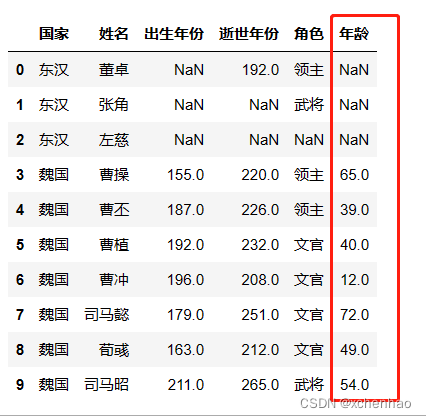
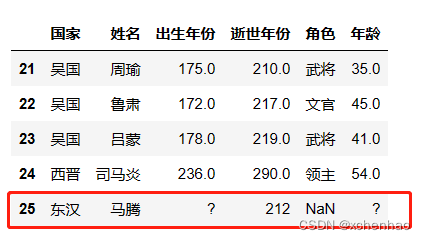
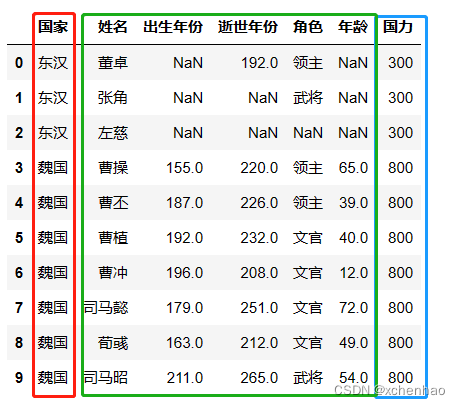
实战 我们先看看数据长啥样,数据存在 sanguo.csv 文档中
(1)导入模块
(2)读取 csv 数据
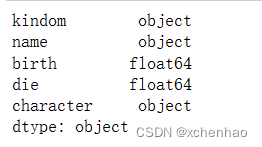
1)查看数据
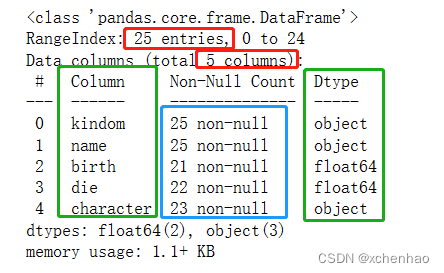
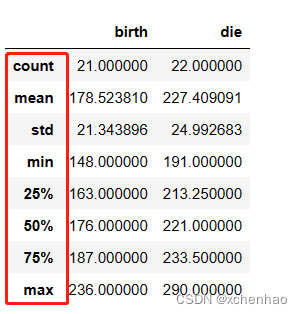
2)查看数据概况
3)数据操作 设置列名
添加新列
计算列平均值、中位数、众数、最/小值 平均值:df['年龄'].mean() 中位数:df['年龄'].median() 众数:df['年龄'].mode() 最大值:df['年龄'].max() 最小值:df['年龄'].min() 列筛选
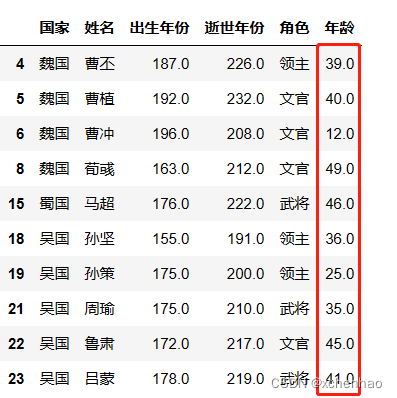
分组
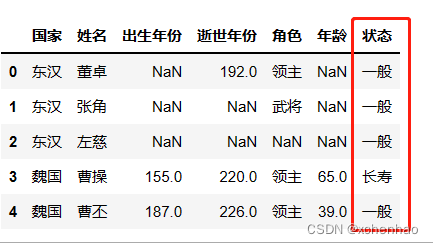
apply 函数
取数据:loc、iloc
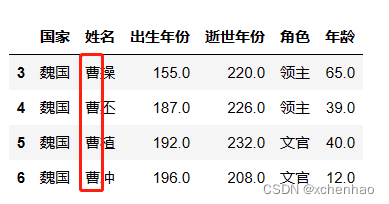
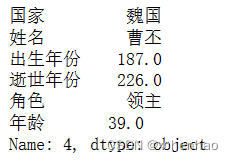
取第 5 行数据(索引从 0 开始)
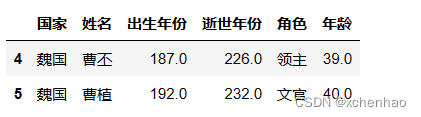
取第 5~6 行数据
df.loc[4, '姓名']或 df.iloc[4, 1]取第 5 行姓名列或第 5 行第 2 列
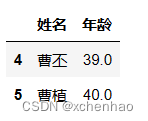
df.loc[4, ['姓名', '年龄']]或 df.iloc[4, [1, 5]]取第 5 行姓名、年龄列或第 5 行第 2 列、第 6 列
df.loc[4:5, ['姓名', '年龄']]或 df.iloc[[4, 5], [1, 5]]或 df.iloc[4:6, [1, 5]]取第 5~6 行姓名、年龄列或取第 5~6 行第 2 列、第 6 列
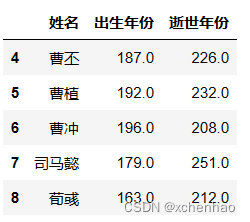
df.iloc[4:9, 1:4]取 5~10 列第 2~5 列
追加、合并数据 concat
merge
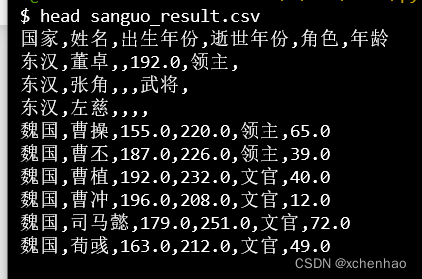
4)导出数据
|








2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27