
2026年三款AI办公助手ToDesk AI、QClaw、Kimi到底怎么选

2026年,AI办公助手这件事已经悄悄变了。 一年前大家还在比谁聊天更顺,现在的问题变成了:它能不能真的帮你把事做完? 我最近密集体验了三款产品ToDesk AI、腾讯QClaw、Kimi K2.6它们刚好代表
|
2026年,AI办公助手这件事已经悄悄变了。 一年前大家还在比"谁聊天更顺",现在的问题变成了:它能不能真的帮你把事做完? 我最近密集体验了三款产品——ToDesk AI、腾讯QClaw、Kimi K2.6——它们刚好代表了三种不同的路线:
这篇文章不是我坐在办公室里看产品文档写的,是我实际用下来的感受,有褒有贬,供参考。三个产品用的是同一套测试任务,公平对比,不搞虚招。 一、ToDesk AI首页体验界面走的是功能导向路线,六大模块(技能、会话、智能体、文件夹、权限、AI接入)都有独立入口。对我来说最实用的是对话框右下角的模型切换入口——可以在7款模型之间切换,简单任务用速度快的,复杂推理切换到理解能力更强的。这个设计挺人性化,不用为了一个简单问题去等一个重型模型慢慢思考。 安全性权限分三级:查看读取、新建修改、高风险操作。高风险操作默认需要手动确认,支持全局配置,也能针对单次任务临时调整。2026年新增了操作日志审计,所有AI执行过程都有留痕,对企业用户来说这是个加分项。 功能性
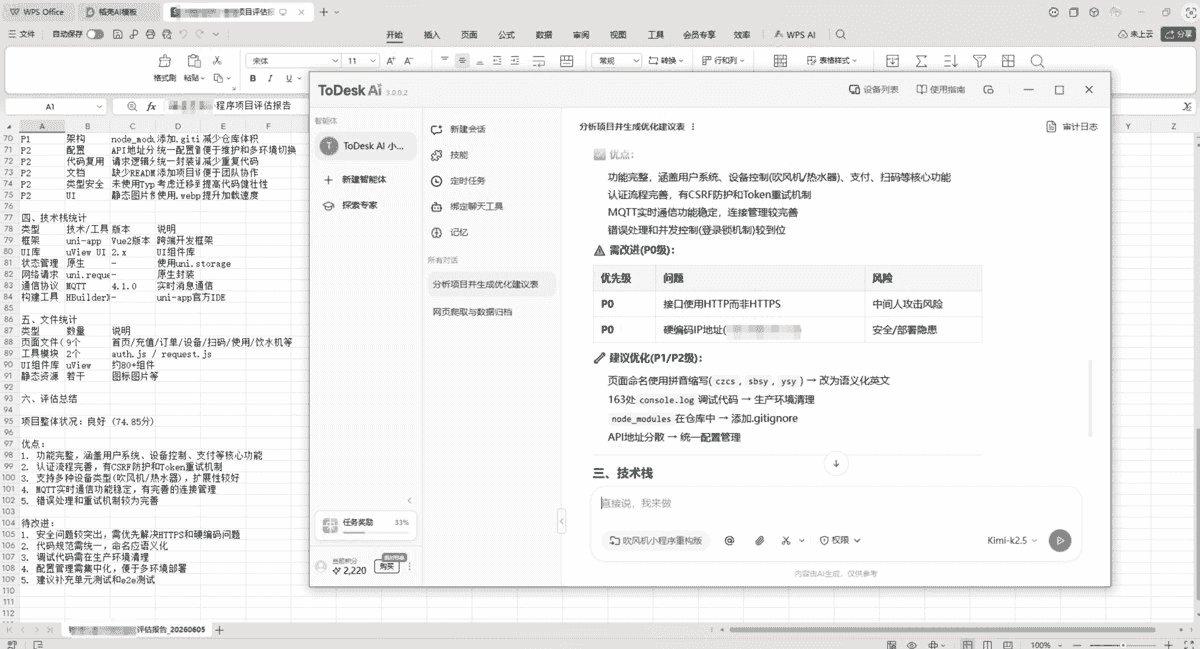
技能库覆盖很全面,有非常多的官方制作的技能,除了内置技能外,也支持通过对话创建技能,以及从社区库导入技能,扩展性不错。 理解准确度对不确定的内容会以卡片形式二次确认,避免误执行,这个交互设计值得肯定。多模型切换后,可以根据任务复杂度选择模型,准确度和响应速度能兼顾。 实战测试测试任务一:网页爬取与数据归档 指令:帮我爬取指定的几个公开网页,把里面的信息完整读取出来,按信息类别做好归档,再把核心的分析数据提取整理好。 ToDesk AI 的表现很干脆。收到指令后自动创建了一个项目文件夹,按信息类别分成了5个子文件夹,每个文件夹里都有说明文件和原始数据,核心分析数据单独整理成了一份汇总文档。整个流程全自动,不需要额外干预,从爬取到归档一气呵成。 测试任务二:AI多模态内容生成 — 从小说到剧本到视觉 指令:让AI根据奇幻世界观设定生成内容——勇者被光明教会召唤讨伐魔王,但魔物全是受保护的公共资源(史莱姆是清洁工、独眼巨人是建筑工、深渊地龙是园艺师、鹰身女妖负责天气预报、哥布林是矿工),甚至有"保护魔王基金会"——因为微量魔气能提升10%修炼速度,离魔王越近最高可达300%。要求:①生成小说正文 ②基于小说改编剧本 ③生成关键道具概念图 小说和剧本的完成度很高,世界观完整、角色对话自然、喜剧节奏到位。道具图部分因需要图像生成API支持,AI自动尝试寻找免费图像API未果后,转而输出了详细的道具图提示词,方便后续对接专业绘图工具。虽然没有直接生成图片,但整个处理思路和降级方案很合理。 测试任务三:梳理前端项目代码架构 指令:分析当前文件下的项目,给出评分和优化建议,最终生成表格保存在桌面
最终生成了一份 Excel 表格直接保存到桌面,包含了模块清单、技术栈识别、综合评分,以及按优先级排列的优化建议。信息组织得比较有条理,作为一次性的项目体检报告够用。 综合评分
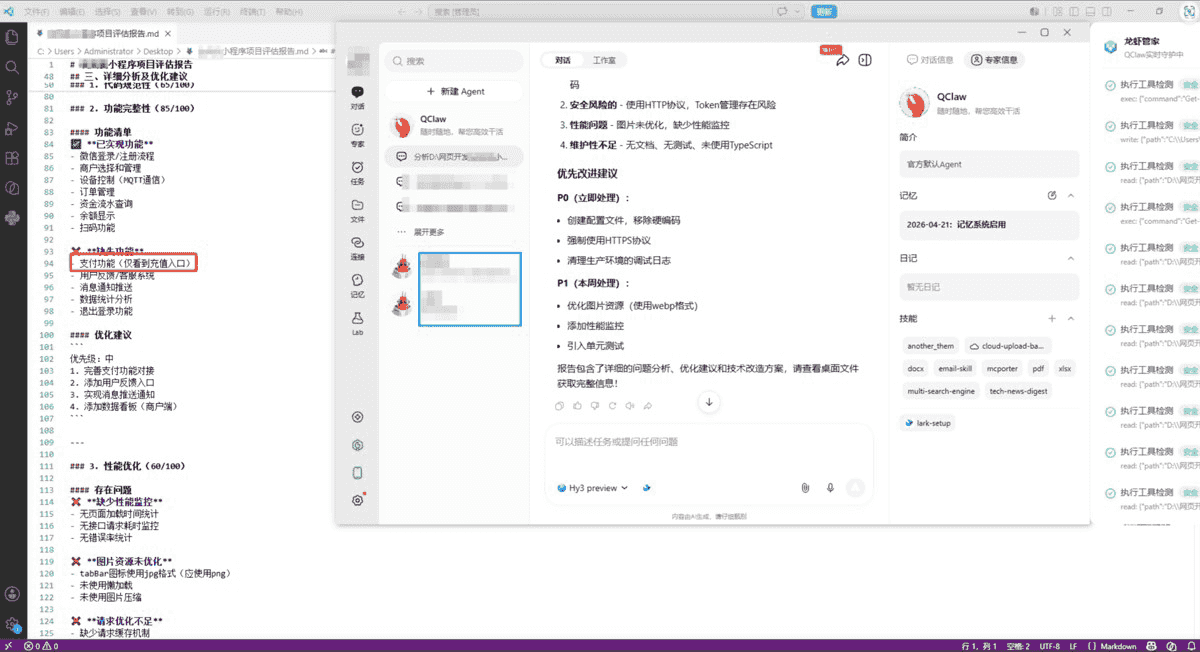
二、QClaw首页体验首页布局简洁,微信绑定入口醒目,绑定后基本功能可以直接用。对技能市场、安全设置等高级功能的入口做了优化,新用户可能还是需要一点探索时间。总体来说属于"功能都有,但你得自己找"的类型。 安全性本地优先是QClaw的核心卖点——数据不上传云端,隐私保护有天然优势。但本地化存储也意味着无法云端同步。 龙虾管家安全防护,开启后桌面会显示"龙虾管家保护条",实时拦截高风险执行脚本、文件误删、异常网络访问,后台有完整的安全守护日志。这是QClaw区别于另外两款产品的最大优势,对数据安全敏感的用户来说很有吸引力。 需要注意的地方:社区第三方技能目前缺乏统一审核机制,使用第三方技能时需要注意安全风险。另外部分安全配置默认是关闭的。 功能性技能安装这块有个明显短板:没有一键安装机制,想要什么技能得让 AI 自己去编写。这就带来一个问题——由 AI 临时生成的技能没有经过测试验证,实际执行时很容易出 bug,稳定性不太行。 理解准确度简单单步指令的理解准确度基本够用。作为本地运行的AI助手,响应速度不错,也不会有云端产品的排队等待问题。但面对较复杂的跨步骤指令时,偶尔会出现理解偏差,需要适度引导才能走到正确的执行路径上。 实战测试测试任务一:网页爬取与数据归档 指令:帮我爬取指定的几个公开网页,把里面的信息完整读取出来,按信息类别做好归档,再把核心的分析数据提取整理好。 代码架构的基本分析能完成,模块划分和依赖关系描述基本正确。但需要注意的是,指令要求"最终生成表格保存在桌面",而QClaw实际只生成了一个md文件,并没有输出结构化的表格,如果你需要表格形式的结果,需要自己转换一下。测试项目中的支付功能模块没有被识别出来,在复杂业务逻辑的理解深度上还有空间。 测试任务二:AI多模态内容生成 — 从小说到剧本到视觉 指令:同上 小说和剧本都成功生成了,内容质量不错,世界观展开和角色塑造到位。文件直接保存在桌面,没有自动创建项目文件夹归类整理,需要自己拖一拖。道具概念图因本地环境缺乏图像生成能力,输出了文字描述作为替代,属于预期之内。 测试任务三:梳理前端项目代码架构 指令:分析当前文件下的项目,给出评分和优化建议,最终生成表格保存在桌面
还是一样,QClaw实际只生成了一个md文件,如果需要表格形式的结果就需要自己转换。
三、Kimi智能助手首页体验界面设计走简约路线,对话输入框居中,历史会话列表在侧边栏。整体感觉干净利落,没什么多余的东西。 安全性Kimi的权限管理相对简单,目前只有"全允许"和"请求确认"两个选项,没有像ToDesk AI那样细粒度的权限分级。数据传输有基础加密,但用户数据会被用于模型训练,对处理敏感信息的用户来说需要考虑。如果你的工作内容涉及商业机密或个人隐私,建议注意数据安全策略。 功能性技能/插件生态覆盖面广,但目前大多数技能名称为全英文,中文用户找功能时需要一定的适应成本。长文档解析和代码阅读是Kimi的传统强项,上下文窗口大,处理超长文本时优势明显。K2.6版本新增了Agent能力,多步骤任务编排比早期版本灵活了不少。 理解准确度长文本和代码推理的表现不错,对不确定的问题会选择追问确认。不过交互方式是纯文本回复,没有卡片式选项,在操作便利性上稍逊一筹。日常办公场景下准确度完全够用,复杂推理任务的表现相对更突出。 实战测试测试任务一:网页爬取与数据归档 指令:帮我爬取指定的几个公开网页,把里面的信息完整读取出来,按信息类别做好归档,再把核心的分析数据提取整理好。
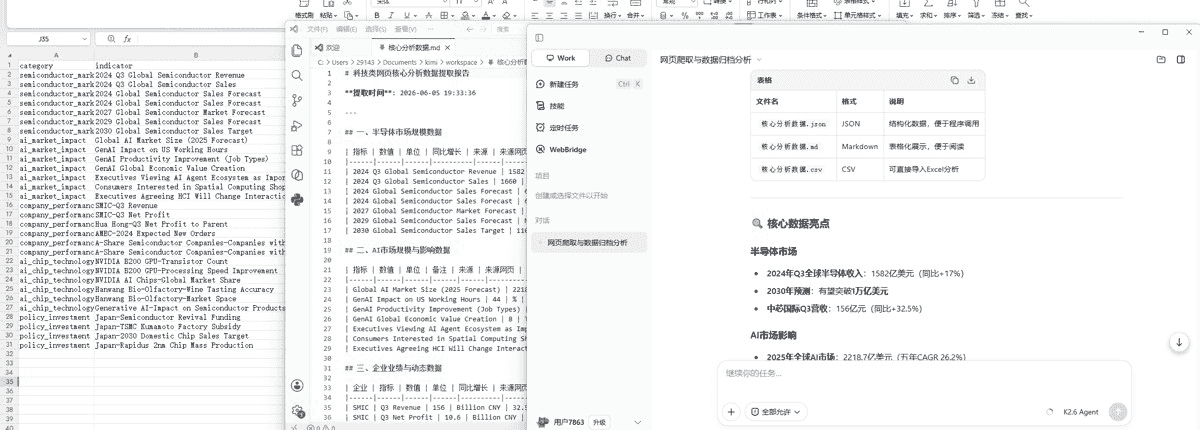
Kimi完成了网页数据的采集,但结果不太理想——爬取到的原始内容几乎全是英文,从截图可以看到 Excel 中充斥着大量未经翻译的原始数据,对中文用户来说可读性很差。对话区虽然输出了中文版的核心数据摘要并生成了 .json/.md/.csv 文件,但整体来看更像是"爬了 → 翻了部分摘要 → 剩下的你自己看",离按信息类别做好归档的要求有明显差距。 测试任务二:AI多模态内容生成 — 从小说到剧本到视觉 指令:同上 小说创作是Kimi比较擅长的地方,故事节奏把控好,角色对话生动,世界观展开自然。剧本改编也顺利完成,场景调度和台词设计合理。道具图环节比较有意思——无法直接生成图片,Kimi用HTML + CSS画了一个"概念图"保存下来,虽然视觉效果比较抽象,但这种"遇到限制就换路"的处理方式确实有创意。 测试任务三:梳理前端项目代码架构 指令:分析当前文件下的项目,给出评分和优化建议,最终生成表格保存在桌面
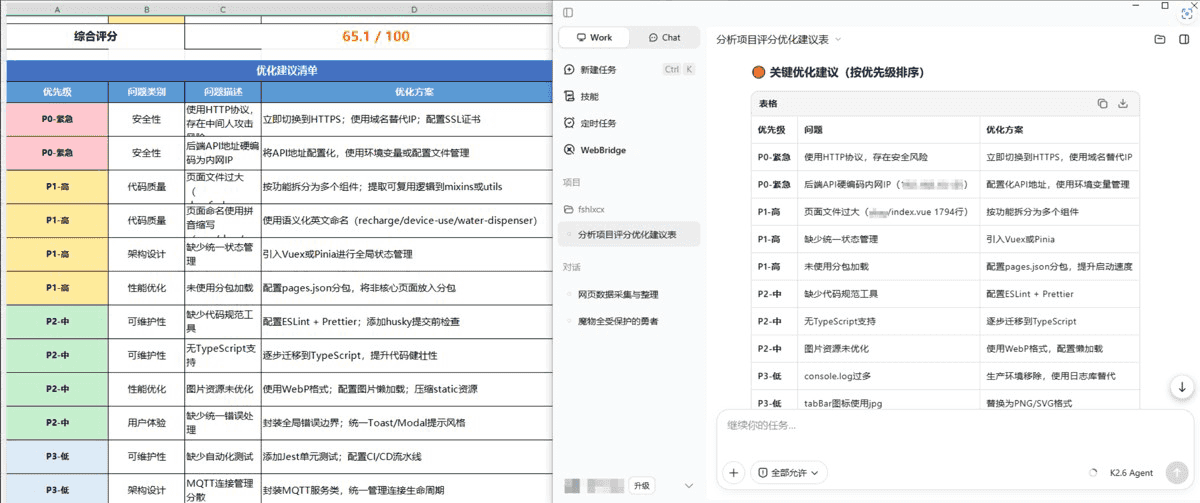
输出了结构化的评分表格,按优先级(P0→P3)和类别做了归纳,表面框架是完整的。但实际看下来,不少优化建议经不起推敲——比如把单一 MQTT 连接识别为"API 地址分散需要统一管理"、逐步迁移到 TypeScript。作为一次快速浏览的体检报告勉强能用,但具体结论建议逐条核实后再落地。 综合评分
四、横向对比
功能亮点对比:
五、总结三款产品到现在,定位差异已经比较清晰了:
综合来看,如果你需要的是一个真正能帮你把事做完的AI助手,ToDesk AI 是目前三个里面完成度最高的选择。QClaw 则更适合对隐私有极致要求的用户,Kimi 适合特定场景(长文档分析、代码阅读)。大多数日常办公场景下,ToDesk AI 的综合体验更省心。 |
您可能感兴趣的文章 :

-
Ubuntu从零部署OpenClaw全过程(本地模型+DeepSeek)
0. 前言 OpenClaw给是一个开源、可自托管的AI助手平台,原生支持Ollama本地模型和DeepSeek等云端API,让你在隐私与性能之间自由切换。本文记录 -

Claude Code 接入 ClaudeAPI.com 教程:CC Switch 一键配置
在使用 Claude Code、Cline、Cursor 这类 AI 编程工具时,很多开发者真正卡住的地方不是安装工具,而是 API 配置。 常见问题包括: Claude Code 的 -
Claude Code对接DeepSeek的完整使用教程(2026 最新版
一、概述 Claude Code 是 Anthropic 推出的终端级 AI 编程代理,以命令行形式运行在项目目录中。它不仅能回答问题,还能直接读写文件、执行命 -

Claude Code配置本地Ollama模型或别的模型(Deepseek等
个人使用场景claude模型实在是太贵了,想使用Claude Code默认只支持Anthropic的接口格式,所以本文记录了如何把本地模型或者其他模型(Deeps -
2026年三款AI办公助手ToDesk AI、QClaw、Kimi到底怎么
2026年,AI办公助手这件事已经悄悄变了。 一年前大家还在比谁聊天更顺,现在的问题变成了:它能不能真的帮你把事做完? 我最近密集体验 -

使用claude code的15个实用小技巧
虽然目前有很多命令行方式的ai代码工具,比如codex code、qwen、gemini等等。但是我仍然觉得claude code非常好用。要想顺畅的使用它,有必要掌 -
CCSwitch 接入Claude 无限token的完整配置(工具推荐
[工具分享]CCSwitch 接入Claude 无限token 本期将会分享开源免费的AI环境切换助手,同时以AgnesAI来给大家演示完整配置。 目前AgnesAI提供免费To -
VSCode+ClaudeCode+Deepseek的配置与联动搭建
本文将以实操落地为核心,详细讲解如何在本地完成 VS Code、Claude Code、Deepseek 三者的环境配置与联动搭建,实现 编辑器 + 代码 AI + 文本 A -

Windows安装Codex及接入DeepSeek-V4的完整教程
Codex和Claude Code安装类似,都需要先安装git和Node.js,其中Node.js安装的版本需要Node.js 18+以上,如要接入DeepSeek最好安装最新版本的,会省事很




-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Claude Code配置Skills的三种方法
2026-05-31

