
OpenClaw中间件请求拦截、转换与增强的完整指南

中间件是 OpenClaw 处理链路中最灵活的一环。本文从中间件的设计哲学出发,系统讲解中间件的三种模式(前置、后置、环绕)、洋葱模型执行链、请求/响应变换机制,以及流式消息处理的特殊
|
中间件是 OpenClaw 处理链路中最灵活的一环。本文从中间件的设计哲学出发,系统讲解中间件的三种模式(前置、后置、环绕)、洋葱模型执行链、请求/响应变换机制,以及流式消息处理的特殊考量。通过两个完整实战案例——“消息敏感词过滤中间件"和"请求耗时统计仪表盘中间件”——你将掌握从零开发生产级中间件的全部技能。读完你会理解:为什么 AI Agent 框架需要中间件,以及如何用它优雅地解决横切关注点。 1. 引言:为什么 AI Agent 也需要中间件1.1 场景还原先说一个真实遇到过的问题。 你的 OpenClaw Agent 接入了企业微信和飞书两个渠道,一切都运行得很好。直到有一天,安全部门找上门来:“你们 Agent 回复的消息里,有没有可能泄露敏感信息?能不能在消息发出去之前做一次检查?” 你第一反应可能是——在每个处理逻辑里加判断。但是 Agent 的回复路径不止一条:直接回复、自动摘要、子代理消息、心跳输出……每条路径都要改一遍? 更麻烦的是,一周后运维团队又提了新需求:“能不能统计每个渠道的消息响应耗时?我们想做性能监控。” 两周后产品说:“飞书渠道的消息需要自动添加加粗格式,但微信渠道不需要。” 面对这些横切关注点(cross-cutting concerns),逐个修改业务逻辑的代价越来越高。这正是中间件的用武之地。 1.2 中间件的本质
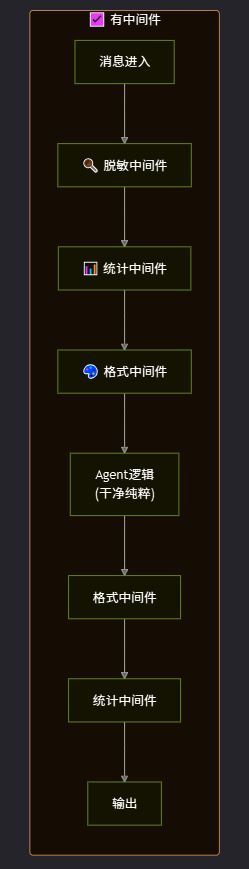
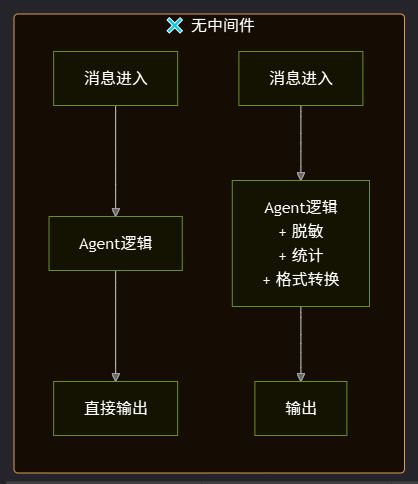
一句话总结:中间件让你在不修改 Agent 核心逻辑的前提下,插入任何需要的前置和后置处理逻辑。 2. 中间件架构设计2.1 三种中间件模式OpenClaw 的中间件根据切入时机分为三种:
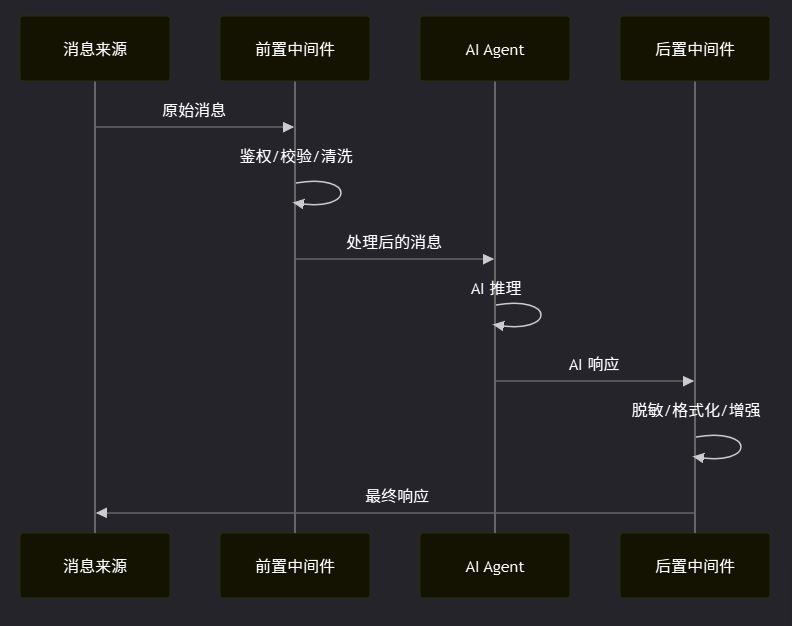
2.2 洋葱模型执行链多个中间件会形成一个洋葱模型的执行链——请求从外层穿过一层层中间件到达核心,响应再从核心穿过一层层中间件回到外层:
洋葱模型的执行顺序:
2.3 中间件配置体系
配置策略表:
3. 中间件开发实战:消息敏感词过滤3.1 需求分析
3.2 完整实现
3.3 效果演示
预期输出:
4. 实战案例二:请求耗时统计仪表盘中间件4.1 需求分析
4.2 环绕中间件实现
4.3 模拟仪表盘数据查询
5. 中间件开发最佳实践5.1 中间件设计原则
5.2 执行顺序的最佳实践
6. 总结本文从零构建了两个生产级中间件,覆盖了 OpenClaw 中间件系统的完整知识点: 核心要点:
思考题:
|

您可能感兴趣的文章 :
- OpenClaw使用Canvas截图进行页面捕获与保存
- Ubuntu从零部署OpenClaw全过程(本地模型+DeepSeek)
- OpenClaw从0到1安装搭建的保姆级教程
- OpenClaw中Shell Tool使用教学:命令执行、输出读取和长任务管理
- macOS平台AI CLI工具安装与配置避坑指南(OpenClaw/Gemini CLI/Claude Code)
- Ubuntu系统上快速部署OpenClaw的完整教程
- OpenClaw页面无法访问的解决方法
- OpenClaw局域网访问配置的实现
- 利用OpenClaw日志排查403和503错误的流程
- OpenClaw安装与配置指南之如何使用自定义模型提供商

-
OpenClaw使用Canvas截图进行页面捕获与保存
本文详细介绍 OpenClaw Canvas 的截图功能。从基本截图、全页面捕获、元素截图到图像处理,全面解析如何通过 Canvas 实现灵活的页面捕获。通 -

Claude Code中上下文压缩机制介绍
一次真实的编码会话,token 总量可能轻松冲到 400K 甚至更高可模型的上下文窗口只有 200K。Claude Code 是怎么把无限增长的对话塞进固定大小的 -
Ubuntu从零部署OpenClaw全过程(本地模型+DeepSeek)
0. 前言 OpenClaw给是一个开源、可自托管的AI助手平台,原生支持Ollama本地模型和DeepSeek等云端API,让你在隐私与性能之间自由切换。本文记录 -

Claude Code 接入 ClaudeAPI.com 教程:CC Switch 一键配置
在使用 Claude Code、Cline、Cursor 这类 AI 编程工具时,很多开发者真正卡住的地方不是安装工具,而是 API 配置。 常见问题包括: Claude Code 的 -
Claude Code对接DeepSeek的完整使用教程(2026 最新版
一、概述 Claude Code 是 Anthropic 推出的终端级 AI 编程代理,以命令行形式运行在项目目录中。它不仅能回答问题,还能直接读写文件、执行命 -

Claude Code配置本地Ollama模型或别的模型(Deepseek等
个人使用场景claude模型实在是太贵了,想使用Claude Code默认只支持Anthropic的接口格式,所以本文记录了如何把本地模型或者其他模型(Deeps -
2026年三款AI办公助手ToDesk AI、QClaw、Kimi到底怎么
2026年,AI办公助手这件事已经悄悄变了。 一年前大家还在比谁聊天更顺,现在的问题变成了:它能不能真的帮你把事做完? 我最近密集体验





-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Claude Code配置Skills的三种方法
2026-05-31

