
Ollama模型快速部署与使用的保姆级教程

在 AI 浪潮席卷各行各业的 2026 年,大语言模型早已不是云端巨头的专属玩具。从个人开发者到中小企业,越来越多的人希望在本地运行、微调或集成大模型既要数据隐私,又要低延迟,还要摆
|
在 AI 浪潮席卷各行各业的 2026 年,大语言模型早已不是云端巨头的专属玩具。从个人开发者到中小企业,越来越多的人希望在本地运行、微调或集成大模型——既要数据隐私,又要低延迟,还要摆脱高昂的 API 费用。这时,Ollama 几乎成了本地模型部署的标配答案。 一、认识 Ollama:把大模型装进口袋Ollama 是一个轻量级、跨平台的本地大模型运行框架,它的核心设计哲学就两个字:简单。你不需要手动安装 CUDA、PyTorch 或任何 Python 依赖,只需一条命令就能把 Llama、Mistral、Gemma、Qwen(通义千问)等上百种开源模型拉取到本地,并立刻开始对话。 它的主要亮点包括:
二、快速部署:三条命令搞定无论你用的是哪种操作系统,Ollama 的安装都称得上“傻瓜式”。 macOS直接使用 Homebrew 安装,或者从 ollama.com 下载 .dmg 包。
Linux一行脚本自动完成安装和系统服务注册。
安装完成后,Ollama 会作为后台服务自动启动,你随时可以用 ollama list 检查状态。 Windows在 ollama.com 下载 .exe 安装包,双击运行即可。安装后它会在系统托盘中运行,并自动配置好环境变量。如果你更习惯 WSL,也可以在 Ubuntu 子系统中直接使用 Linux 安装方式。 验证安装:
如果显示出类似 ollama version 0.5.1 的信息,恭喜你,部署已经完成了。 三、运行第一个模型:像是和终端聊天Ollama 的模型库中有大量即开即用的模型。以阿里通义千问系列的中文优化模型 qwen2.5:7b 为例(2026 年可能已有更新的 qwen3,你可以按需选择):
pull 命令会自动下载模型文件(3.3GB),并缓存到本地。下载完成后,直接运行:
此时你的终端就变成了一个对话界面:
常用管理命令:
想要更换模型?一个 ollama pull llama3.2 再 ollama run llama3.2 就能立刻切换到 Meta 的模型。多模型共存,互不干扰。 四、用 API 连接世界:从 curl 到 OpenAI SDK仅在终端里聊天还不够,真正让 Ollama 发光的是它的 REST API。Ollama 默认在 localhost:11434 提供 HTTP 服务,无需额外配置(首次运行模型或执行 ollama serve 时会自动启动)。 原生聊天接口用 curl 发送一次对话请求:
返回的 JSON 中直接包含 message.content 字段。如果需要流式输出,把 stream 设为 true 即可。 完全兼容 OpenAI API这是 Ollama 最具杀伤力的特性:它提供了一个 OpenAI 兼容端点,任何使用 OpenAI Python 库、LangChain 或第三方客户端的代码,只需改一行 base_url 就能切到本地模型。
对,你没看错,api_key 可以写任何字符串。这种兼容性意味着你可以把 Ollama 直接接入到 Chatbox、Open WebUI、LangChain、AutoGPT 等海量现成应用中,本地模型瞬间拥有了 ChatGPT 同等“待遇”。 五、定制你的专属模型:Modelfile每个人的需求不同,有时你需要一个带有特定人设的模型,或者调整输出温度、上下文长度。Ollama 的 Modelfile 让你能像写 Dockerfile 一样定义模型行为。 创建一个名为 Modelfile 的文件:
然后根据这个文件创建一个新模型:
运行它:
现在这个模型已经内化了“高级工程师”的角色,你问它“如何用 Go 写一个并发安全的计数器?”,它会给出比通用模型更切中要点的答复。 你也可以将任何 GGUF 格式的微调模型通过 Modelfile 导入 Ollama,只需将 FROM 指向本地文件路径即可。 六、集成到你的技术栈:LangChain、LlamaIndex 示例当你想用本地模型构建 RAG 知识库、智能代理或文档问答系统时,Ollama 同样是最佳拍档。 LangChain
LlamaIndex
这些框架会将请求自动转发到 localhost:11434,你只需保证 Ollama 在后台运行即可。对于更复杂的生产环境,你还可以通过环境变量 OLLAMA_HOST=0.0.0.0:11434 将服务暴露给内网其他机器,甚至搭配 Nginx 做负载均衡。 七、性能调优与常见问题1. GPU 加速Ollama 在安装时会自动检测 NVIDIA/AMD 显卡并启用 GPU 推理,无需手动配置。你可以用 ollama ps 查看当前模型占用的 GPU 内存。如果你有多个 GPU,可以通过环境变量 CUDA_VISIBLE_DEVICES 指定使用哪块卡。 2. 模型量化模型默认使用 Q4_K_M 量化,能在速度和精度间取得较好平衡。如果你想节省内存(比如在 8GB 显卡上跑 13B 模型),可以尝试带有 q2_K 或 q3 标签的版本:
3. 并发与上下文默认 Ollama 会并行处理多个请求,但受限于显存。你可以通过 OLLAMA_NUM_PARALLEL 环境变量调整最大并发数。另外,长上下文会消耗大量显存,可按需在 Modelfile 中设置 num_ctx。 4. 内存不足怎么办?如果模型太大导致 OOM(内存溢出),可以考虑:
八、结语:本地大模型本该如此简单Ollama 的出现,真正把大模型从“只有深度学习工程师才能摆弄”的高阁拉回到了每一个开发者的终端里。它屏蔽了底层复杂的依赖和优化细节,却保留了足够的灵活性和可扩展性。无论你是想在个人项目中嵌入 AI 能力,还是在公司内部搭建隐私安全的 LLM 服务,Ollama 都是那个值得首选的“快速部署与使用”方案。 |

您可能感兴趣的文章 :
- Ubuntu从零部署OpenClaw全过程(本地模型+DeepSeek)
- Claude Code配置本地Ollama模型或别的模型(Deepseek等)的实践指南
- 使用codex快速接入第三方模型
- 最新版Claude Desktop接入第三方模型指南
- OpenClaw安装与配置指南之如何使用自定义模型提供商
- Claude Code接入本地大模型Qwen3.6 进行代码开发(vLLM 部署 + 环境配置)
- 一篇带你搞定Ollama模型的安装到生产级调优
- Windows原生部署OpenClaw并对接DeepSeek-V4大模型的全流程
- 国内直连、低成本调用主流大模型API:以OpenClaw为案例的AGENT本地部署

-
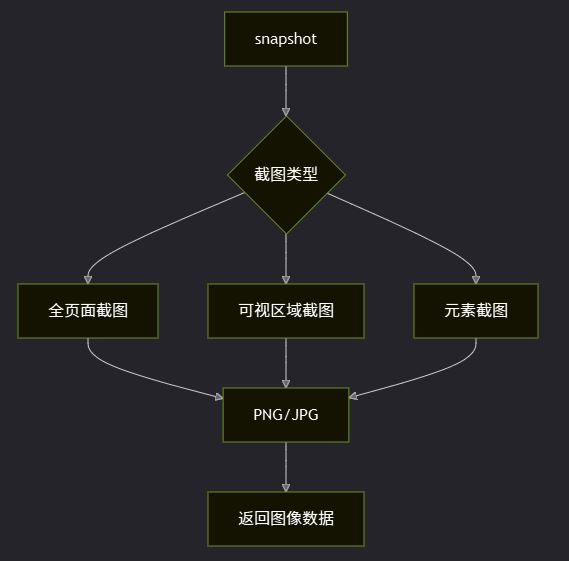
OpenClaw使用Canvas截图进行页面捕获与保存
本文详细介绍 OpenClaw Canvas 的截图功能。从基本截图、全页面捕获、元素截图到图像处理,全面解析如何通过 Canvas 实现灵活的页面捕获。通 -

Claude Code中上下文压缩机制介绍
一次真实的编码会话,token 总量可能轻松冲到 400K 甚至更高可模型的上下文窗口只有 200K。Claude Code 是怎么把无限增长的对话塞进固定大小的 -
Ubuntu从零部署OpenClaw全过程(本地模型+DeepSeek)
0. 前言 OpenClaw给是一个开源、可自托管的AI助手平台,原生支持Ollama本地模型和DeepSeek等云端API,让你在隐私与性能之间自由切换。本文记录 -

Claude Code 接入 ClaudeAPI.com 教程:CC Switch 一键配置
在使用 Claude Code、Cline、Cursor 这类 AI 编程工具时,很多开发者真正卡住的地方不是安装工具,而是 API 配置。 常见问题包括: Claude Code 的 -
Claude Code对接DeepSeek的完整使用教程(2026 最新版
一、概述 Claude Code 是 Anthropic 推出的终端级 AI 编程代理,以命令行形式运行在项目目录中。它不仅能回答问题,还能直接读写文件、执行命 -

Claude Code配置本地Ollama模型或别的模型(Deepseek等
个人使用场景claude模型实在是太贵了,想使用Claude Code默认只支持Anthropic的接口格式,所以本文记录了如何把本地模型或者其他模型(Deeps -
2026年三款AI办公助手ToDesk AI、QClaw、Kimi到底怎么
2026年,AI办公助手这件事已经悄悄变了。 一年前大家还在比谁聊天更顺,现在的问题变成了:它能不能真的帮你把事做完? 我最近密集体验




-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Claude Code配置Skills的三种方法
2026-05-31

