
Python多进程与多线程适用场景案例

你想明确多进程和多线程各自的适用场景,核心是要结合任务类型、资源需求、数据共享等维度来判断简单来说,IO密集型任务优先用多线程,CPU密集型任务必须用多进程,下面拆解具体场景和
|
你想明确多进程和多线程各自的适用场景,核心是要结合任务类型、资源需求、数据共享等维度来判断——简单来说,IO密集型任务优先用多线程,CPU密集型任务必须用多进程,下面拆解具体场景和选型逻辑,附实战案例帮你落地。 一、多线程(threading):主打“IO密集型”场景多线程的核心优势是“轻量、切换快、数据共享方便”,但受GIL限制无法利用多核,因此只适合“等待时间远大于计算时间”的任务(IO等待时线程释放GIL,其他线程可执行)。 1. 核心适用场景(附案例)(1)网络相关任务(最典型)
(2)文件/数据库IO任务
(3)需频繁数据共享的轻量任务
2. 多线程避坑场景
二、多进程(multiprocessing):主打“CPU密集型”场景多进程的核心优势是“突破GIL限制、利用多核CPU、进程隔离更稳定”,但启动/通信开销大,适合“计算时间占主导”的任务。 1. 核心适用场景(附案例)(1)数据计算类任务(最典型)
(2)批量独立任务处理
(3)高稳定性要求的任务
2. 多进程避坑场景
三、选型速查表(新手直接套用)
四、特殊场景:混合使用(线程+进程)如果任务是“IO+CPU混合”(如爬取数据后立即计算),可结合二者优势: 示例:多进程(处理CPU计算)+ 多线程(处理IO爬取)
|
您可能感兴趣的文章 :

-
Python使用MySQL数据库进行事务处理示例
一、事务核心概念(先理解再实操) 事务(Transaction)是数据库操作的最小逻辑单元,遵循ACID 原则: 原子性(Atomicity):要么全部执行成 -
Python多进程与多线程适用场景案例
你想明确多进程和多线程各自的适用场景,核心是要结合任务类型、资源需求、数据共享等维度来判断简单来说,IO密集型任务优先用多线程 -
使用Python实现一个自动整理音乐文件脚本
一、音乐文件管理的痛点与解决方案 现代音乐收藏常面临杂乱无章的问题:同一艺术家的歌曲散落在不同文件夹,专辑被错误命名,甚至文 -
Python中as关键字的作用实例介绍
在 Python 中,as是一个关键字,核心语义是将某个对象绑定到指定的变量(或给对象起别名),从而简化代码操作、访问对象属性。它主要应 -
Python使用urllib和requests发送HTTP请求的方法
本文通过天气API示例演示了实际应用,并提供了超时设置、错误处理和JSON解析等实用技巧。推荐大多数场景使用requests库,同时强调了异常 -
在Mac上安装最新版本Python的方法
所有最新的 MacOS(从 macOS 12.3 开始)都预装了 Python 版本(通常是 Python 2.x),但它已经过时并且不再受支持。要充分利用 Python 的功能,您 -
python serial模块使用方法
在Python中实现串口通信,最常用且功能强大的库是pySerial(通常通过import serial导入) 。它支持跨平台操作(Windows、Linux、macOS),提供了完 -
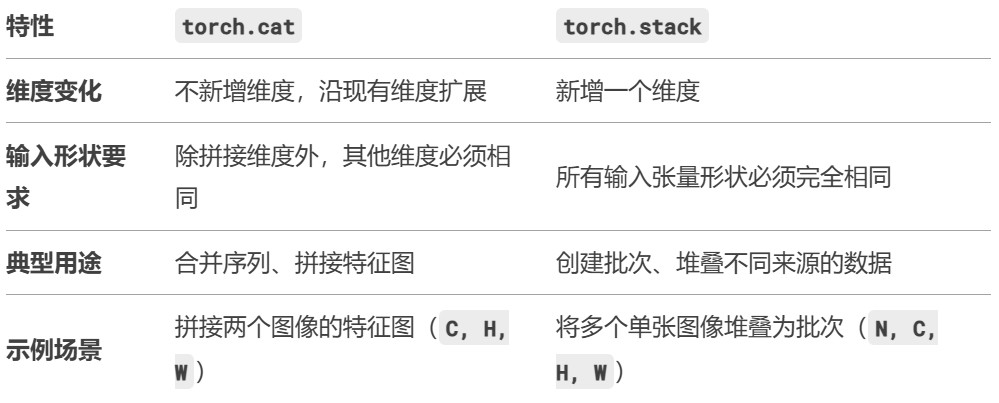
pytorch中torch.cat和torch.stack的区别
torch.cat和torch.stack是 PyTorch 中用于组合张量的两个常用函数,它们的核心区别在于输入张量的维度和输出张量的维度变化。以下是详细对比: -
Python实现快速扫描目标主机的开放端口和服务
功能介绍 这是一个功能强大的端口扫描器脚本,能够快速扫描目标主机的开放端口和服务。该脚本具备以下核心功能: 多种扫描模式:支持 -
Python轻松实现Word到Markdown的转换
在文档管理、内容发布等场景中,将 Word(.doc/.docx)转换为 Markdown 格式是常见需求。Markdown 的轻量、跨平台、易编辑特性,使其更适配网页



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

