
python实现PDF文档提取,分割与合并操作

一、PDF提取文字/转图片 提取文字和转图片使用的是fitz模块,模块安装: 1 pip install PyMuPDF 提取文字 1 2 3 4 5 6 7 8 9 10 11 12 13 import fitz pdf = fitz.open(xxxx.pdf) # xxxx.pdf是pdf文件名或路径 pages = pdf.pag
一、PDF提取文字/转图片提取文字和转图片使用的是fitz模块,模块安装:
提取文字
转图片
二、分割、合并PDF文档2.1 使用PyPDF2模块模块安装:
分割、合并PDF
2.2 使用fitz模块模块安装:
示例:
分割跟合并PDF的原理是一样的,前者是打开一个PDF文档,创建并保存为多个PDF文档;后者是打开多个PDF文档,创建并保存为一个PDF文档。 使用PyPDF2模块合并pdf文件时常常遇到乱码问题,因此本人更推荐使用fitz模块。 |
您可能感兴趣的文章 :

-
python实现PDF文档提取,分割与合并操作
一、PDF提取文字/转图片 提取文字和转图片使用的是fitz模块,模块安装: 1 pip install PyMuPDF 提取文字 1 2 3 4 5 6 7 8 9 10 11 12 13 import fitz pdf = f -
Python中enumerate函数的巧妙用法
在算法题目中,处理数组(List)、字符串、矩阵等可迭代对象时,同时获取索引和元素值 是高频需求 比如找目标元素的位置、双指针遍历 -
Python中的断言机制的介绍
想象你正在开发一个电商系统,有个计算商品折扣的函数。正常情况下,折扣率应该在0到1之间,但某天测试时发现某个商品折扣变成了1. -
Python使用MySQL数据库进行事务处理示例
一、事务核心概念(先理解再实操) 事务(Transaction)是数据库操作的最小逻辑单元,遵循ACID 原则: 原子性(Atomicity):要么全部执行成 -
Python多进程与多线程适用场景案例
你想明确多进程和多线程各自的适用场景,核心是要结合任务类型、资源需求、数据共享等维度来判断简单来说,IO密集型任务优先用多线程 -
使用Python实现一个自动整理音乐文件脚本
一、音乐文件管理的痛点与解决方案 现代音乐收藏常面临杂乱无章的问题:同一艺术家的歌曲散落在不同文件夹,专辑被错误命名,甚至文 -
Python中as关键字的作用实例介绍
在 Python 中,as是一个关键字,核心语义是将某个对象绑定到指定的变量(或给对象起别名),从而简化代码操作、访问对象属性。它主要应 -
Python使用urllib和requests发送HTTP请求的方法
本文通过天气API示例演示了实际应用,并提供了超时设置、错误处理和JSON解析等实用技巧。推荐大多数场景使用requests库,同时强调了异常 -
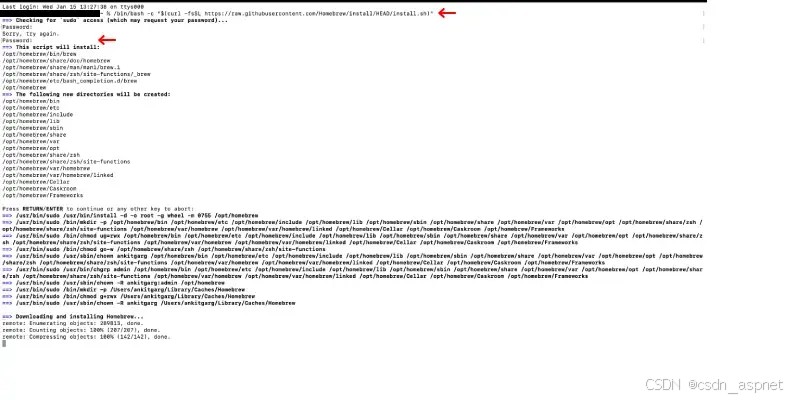
在Mac上安装最新版本Python的方法
所有最新的 MacOS(从 macOS 12.3 开始)都预装了 Python 版本(通常是 Python 2.x),但它已经过时并且不再受支持。要充分利用 Python 的功能,您 -
python serial模块使用方法
在Python中实现串口通信,最常用且功能强大的库是pySerial(通常通过import serial导入) 。它支持跨平台操作(Windows、Linux、macOS),提供了完



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

