
Ollama部署的五大崩溃场景与解决方法介绍

Ollama 是大多数人第一个接触的本地大模型工具。但它的问题也是最多的不是因为它质量差,而是因为它被用在太多奇奇怪怪的硬件组合上了。 一、Ollama vs vLLM vs SGLang:为什么 Ollama 的坑不一样
|
Ollama 是大多数人第一个接触的本地大模型工具。但它的问题也是最多的——不是因为它质量差,而是因为它被用在太多奇奇怪怪的硬件组合上了。 一、Ollama vs vLLM vs SGLang:为什么 Ollama 的坑不一样
Ollama 的坑集中在一件事:在不够的硬件上跑太大的模型,然后崩溃方式千奇百怪。 二、五大崩溃场景崩溃 1:llama runner process has terminated: exit status 2——模型启动即炸报错特征
环境:AMD RX 6750 XT、ROCm、手动替换 GPU 适配文件 根因:Ollama 的 llama runner 是底层推理进程。exit status 2 通常意味着:
修复方案: 强制指定 CPU 推理(临时绕过 GPU 问题):
清理损坏的模型文件重新下载:
AMD GPU 用户检查 ROCm 驱动:
NVIDIA 用户检查 CUDA 库: Ollama 内置多种 CUDA 库(cu11/cu12),强制用特定版本:
崩溃 2:Ollama 运行 10 分钟后停止响应——"Failed to acquire semaphore"报错特征
然后所有请求立即返回:
环境:双 RTX 4090、Ollama 0.1.38、连续 embedding 任务 发生了什么:前 10-15 分钟一切正常。然后 Ollama 先挂起请求到超时 → 之后所有新请求都立即返回错误。不重启就无法恢复。 根因:Ollama 的并发槽位(slots)管理 bug。embedding 任务长期占用 GPU 后,Ollama 无法正确释放槽位。新请求进来时 no slots available——即使 GPU 实际上空闲。 修复方案: 降低并发数:
默认并发数较高,降到 4 或 8 可避免槽位耗尽。 限制 OLLAMA_MAX_LOADED_MODELS:
只允许一个模型常驻显存,减少槽位争用。 定期清理 + 健康检查(生产环境):
keep_alive:0 强制请求完成后立即卸载模型。 升级 Ollama 版本:
0.1.45+ 版本对槽位管理有显著改进。 崩溃 3:GGUF 模型加载时断言失败——GGML_ASSERT(size <= INT_MAX) failed报错特征
环境:ollama run gpt-oss:20b(MXFP4 量化,20.9B 参数) 根因:Ollama 底层使用 GGML 张量库,其中单个张量的字节数用 int 存储。当模型参数超过 2^31-1 字节(约 2.1 GB)时,某个中间张量超过了 INT_MAX 限制,触发断言崩溃。 这本质上是 GGML 的限制——单个张量不能超过 2.1 GB。大模型 + 大上下文会在 KV cache 中产生超限的张量。 修复方案: 用更激进的量化降低模型体积:
限制上下文长度:
上下文越短,KV cache 的张量越小,越不容易超 INT_MAX。 换到 GGUF 的 Q8_0 或更小量化格式: Ollama 的 Modelfile 中指定量化版本:
崩溃 4:Ollama server not responding - timed out waiting for server to start报错特征:
根因:这是 Ollama 最常见的启动失败。背后可能有三类原因:
修复方案: 检查日志:
手动启动并观察:
完全重置 Ollama:
用 CPU 模式启动排除 GPU 问题:
如果 CPU 模式能启动 → 问题在 GPU → 重装驱动。 崩溃 5:Ollama 吃满显存不释放——模型不卸载特征:ollama run model-a 跑完,切换到 ollama run model-b,显存不够。nvidia-smi 显示 model-a 仍占着显存。 根因:Ollama 默认 keep_alive=5m——模型在最后一次请求后继续占用显存 5 分钟。这在开发调试时频繁切换模型极其难受。 修复方案: 立即卸载模型:
keep_alive:0 强制请求完成后立即卸载。 全局缩短 keep_alive:
30 秒无请求后自动卸载。 生产环境设 OLLAMA_KEEP_ALIVE=-1:
模型永远不卸载(适合固定模型高并发场景),但开发时别用这个。 三、Ollama 环境变量速查
四、总结Ollama 的坑跟 vLLM/SGLang 有本质区别:vLLM 坑在调度器和 CUDA Graph,SGLang 坑在环境配置和通信,Ollama 坑在硬件兼容性 + 量化格式 + 消费级 GPU 的极限压榨。 核心原则:
搭配我们推理引擎系列前三篇(vLLM V1 / SGLang / Dify),你现在有了完整的本地推理工具排障体系。 |
您可能感兴趣的文章 :

-
Claude Code Router实现一键接入多种AI模型的智能路由
什么是Claude Code Router? Claude Code Router是一款革命性的开源代理工具,专为解决AI模型平台锁定问题而生。它作为Claude Code CLI与各大AI模型供应 -
使用OpenClaw Browser实现表单自动化的方法
本文通过实际案例演示 OpenClaw Browser 的表单自动化能力。从简单登录表单到复杂多步骤表单,全面解析表单自动化的实现技巧。涵盖表单分 -

OpenClaw从单机Docker部署迁移到Kubernetes集群的完整
当你的 OpenClaw 从单机走向集群,Kubernetes 是绕不开的选择。本文从 K8s 核心概念出发,系统讲解 OpenClaw 的 K8s 部署架构包括 Deployment 无状态部 -

Codex桌面版配对码在哪里找?Codex手机连接电脑完整
一、为什么要关注 Codex 桌面版的设备连接 Codex桌面版开始支持更多跨设备协作能力后,很多人第一次使用时会卡在一个问题上:手机端提示 -
Ollama部署的五大崩溃场景与解决方法介绍
Ollama 是大多数人第一个接触的本地大模型工具。但它的问题也是最多的不是因为它质量差,而是因为它被用在太多奇奇怪怪的硬件组合上了 -
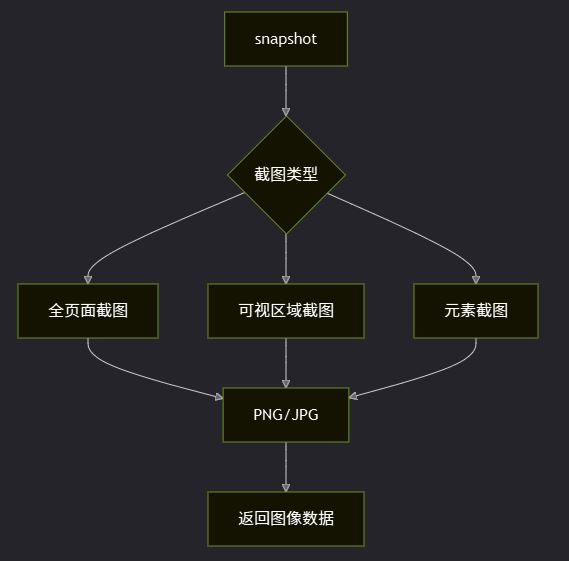
OpenClaw使用Canvas截图进行页面捕获与保存
本文详细介绍 OpenClaw Canvas 的截图功能。从基本截图、全页面捕获、元素截图到图像处理,全面解析如何通过 Canvas 实现灵活的页面捕获。通 -

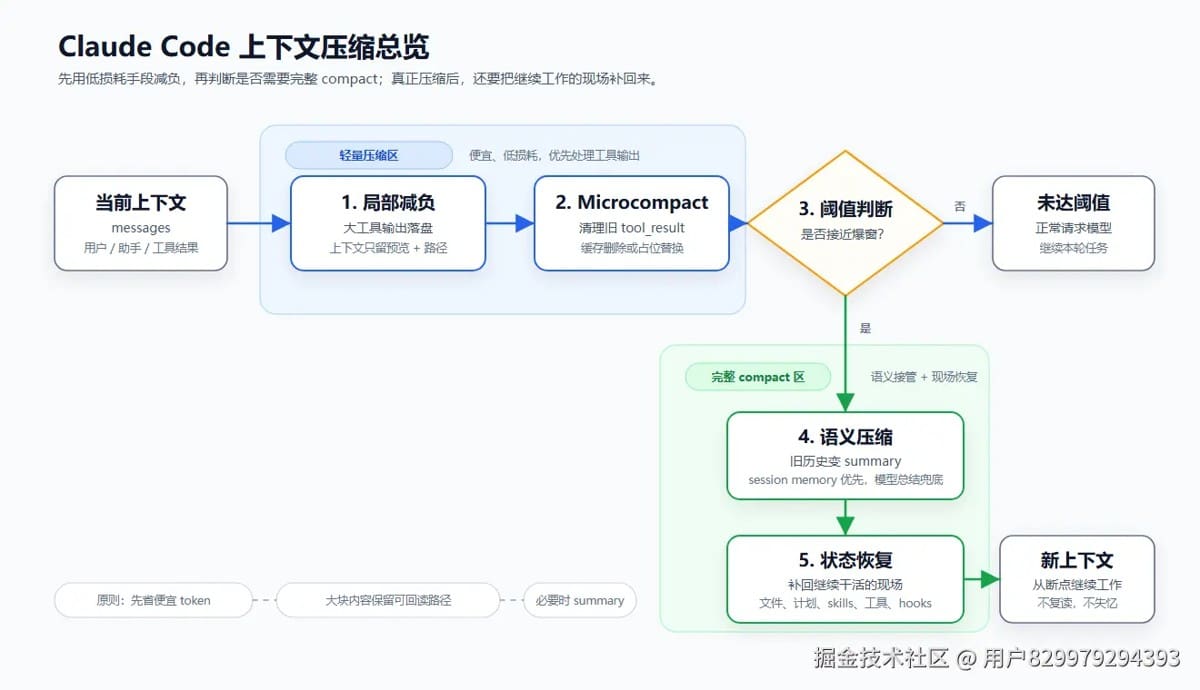
Claude Code中上下文压缩机制介绍
一次真实的编码会话,token 总量可能轻松冲到 400K 甚至更高可模型的上下文窗口只有 200K。Claude Code 是怎么把无限增长的对话塞进固定大小的




-
Codex安装、入门和快速使用的新手教程
2026-06-02
-
Qwen Code 0.16 新特性介绍
2026-06-01
-
Windows安装Codex及接入DeepSeek-V4的完整教
2026-06-25
-
kimi 2.5接入VScode copilot完整图文教程
2026-06-24
-
Claude Code配置Skills的三种方法
2026-05-31

